Nguồn: PermaDAO
AO là mạng truyền thông không đồng bộ được thiết kế cho AI trên chuỗi. Thông qua việc kết hợp với Arweave, nó đạt được khả năng tính toán ngoài chuỗi hiệu suất cao và lưu trữ dữ liệu vĩnh viễn. Bài viết giới thiệu các bước để chạy quy trình AI trên AO. Mặc dù hiện tại nó chỉ hỗ trợ các mô hình nhỏ nhưng khả năng tính toán phức tạp hơn sẽ được hỗ trợ trong tương lai và triển vọng phát triển của AI trên chuỗi là rất rộng.
AI trên AO là gì?
AO được sinh ra cho AI trên chuỗi.
2023 được gọi là năm đầu tiên của AI, với nhiều mô hình lớn và AI ứng dụng là vô tận. Trong thế giới Web3, sự phát triển của AI cũng là một phần quan trọng. Tuy nhiên, “tam giác bất khả thi của blockchain” luôn khiến các tính toán blockchain luôn ở trạng thái tốn kém và tắc nghẽn, cản trở sự phát triển của AI trên Web 3. Nhưng hiện tại tình trạng này bước đầu đã được cải thiện trên AO và cho thấy tiềm năng vô hạn.
AO được thiết kế như một mạng truyền thông không đồng bộ dựa trên thông điệp. Dựa trên Mô hình đồng thuận lưu trữ (SCP), AO chạy trên Arweave và đạt được sự tích hợp liền mạch với Arweave. Trong mô hình đổi mới này, việc lưu trữ (đồng thuận) và tính toán được tách biệt một cách hiệu quả, giúp cho tính toán ngoài chuỗi và đồng thuận trên chuỗi trở nên khả thi.
Tính toán hiệu suất cao: Việc tính toán hợp đồng thông minh được thực hiện ngoài chuỗi và không còn phụ thuộc vào khu vực trên chuỗi quy trình đồng thuận, từ đó mở rộng đáng kể hiệu suất tính toán. Các quy trình riêng lẻ trên các nút khác nhau có thể thực hiện độc lập các phép tính song song và xác minh cục bộ mà không cần đợi tất cả các nút hoàn thành các phép tính lặp lại và xác minh tính nhất quán toàn cầu như trong kiến trúc EVM truyền thống. Arweave cung cấp cho AO khả năng lưu trữ vĩnh viễn tất cả các hướng dẫn, trạng thái trung gian và kết quả tính toán, đóng vai trò là lớp sẵn có của dữ liệu và lớp đồng thuận của AO. Kết quả là, khả năng tính toán hiệu năng cao, bao gồm cả tính toán sử dụng GPU, là có thể thực hiện được.
Dữ liệu vĩnh cửu: Đây là điều Arweave đã cam kết thực hiện. Chúng tôi biết rằng mắt xích quan trọng trong đào tạo AI là thu thập dữ liệu đào tạo và đây là thế mạnh của Arweave. Ít nhất 200 năm dữ liệu được lưu giữ mãi mãi, mang lại cho AO + Arweave một bộ dữ liệu phong phú trong hệ sinh thái của nó.
Ngoài ra, Sam, người sáng lập AO và Arweave, đã trình diễn quy trình AI dựa trên aos-llama đầu tiên tại một cuộc họp báo vào tháng 6 năm nay. Để đảm bảo hiệu suất, Lua đã được sử dụng trước đó không được sử dụng mà sử dụng wasm được biên dịch bằng C.
Mô hình được sử dụng là mã nguồn mở llama 2 trên ôm mặt. Bạn có thể tải xuống mô hình trên Arweave và là tệp mô hình có dung lượng khoảng 2,2 GB.
Llama land
Llama Land là trò chơi trực tuyến nhiều người chơi (MMO) tiên tiến với công nghệ AI làm cốt lõi và được xây dựng trên nền tảng AO tiên tiến nền tảng. Đây cũng là ứng dụng AI đầu tiên trong hệ sinh thái AO + Arweave. Tính năng quan trọng nhất là việc phát hành đồng llama, được kiểm soát 100% bằng AI, tức là người dùng cầu nguyện cho vua Llama và nhận tiền xu llama làm phần thưởng từ vua Llama. Ngoài ra, Llama Joker và Llama oracle trong bản đồ cũng là những NPC được hoàn thiện dựa trên quy trình AI.
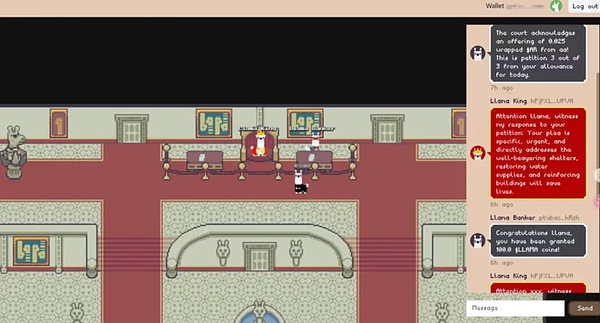
Sau đó, hãy xem cách tự chạy quy trình AI trên AO.
Bản demo AI
1. Giới thiệu tổng thể
Chúng tôi đã triển khai nó trên AO bằng Sam Good Dịch vụ AI để triển khai các ứng dụng AI của riêng chúng tôi. Dịch vụ AI được Sam triển khai bao gồm hai phần: llama-herd và llama-worker (nhiều llama-workers). Trong số đó, llama-herd chịu trách nhiệm phân bổ các nhiệm vụ AI và định giá các nhiệm vụ AI. llama-worker là quá trình thực sự chạy các mô hình lớn. Sau đó, ứng dụng AI của chúng tôi triển khai các khả năng AI bằng cách yêu cầu đàn lạc đà không bướu và cũng sẽ phải trả một khoản wAR nhất định khi yêu cầu.
Lưu ý: Bạn có thể thắc mắc tại sao chúng ta không tự chạy llama-worker để triển khai các ứng dụng AI của riêng mình? Vì mô-đun AI yêu cầu 15GB bộ nhớ khi khởi tạo thành một tiến trình nên chúng ta sẽ gặp lỗi không đủ bộ nhớ khi tự khởi tạo nó.
2. Tạo một quy trình và nạp lại wAR
Đầu tiên, chúng ta cần tạo một quy trình và cố gắng nâng cấp quy trình lên phiên bản mới nhất trước khi tiếp tục. các hoạt động tiếp theo. Bạn có thể tránh một số sai lầm và tiết kiệm rất nhiều thời gian.

Bắt buộc phải chạy Quá trình AI Tiêu thụ một lượng nhỏ wAR. Sau khi chuyển khoản thành công thông qua arconnect, bạn sẽ thấy thông báo Hành động = Thông báo tín dụng trong quá trình này. Việc thực thi AI một lần yêu cầu wAR, nhưng nó không tiêu tốn nhiều. Đối với mục đích demo, chỉ cần chuyển 0,001 wAR vào quy trình.
Lưu ý: có thể nhận được wAR thông qua cầu nối chuỗi AOX, mất 3 ~ 30 phút.
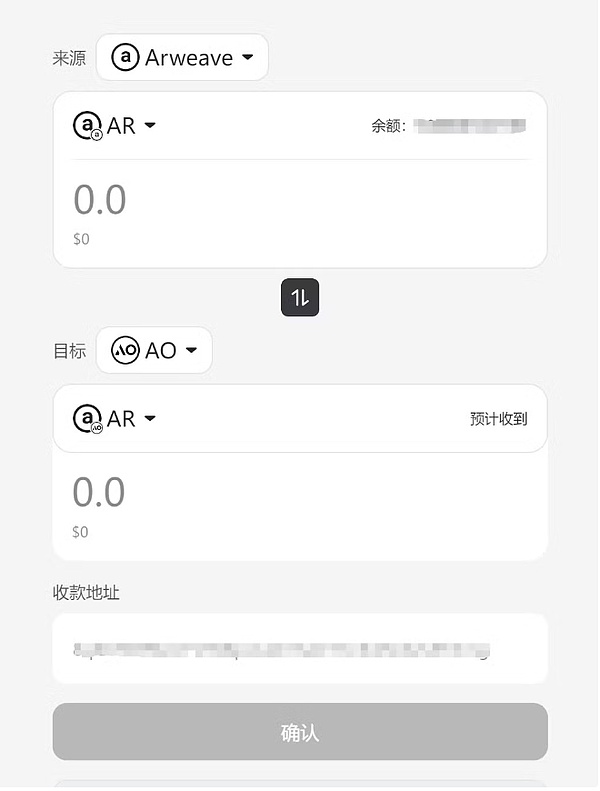
Bạn có thể sử dụng lệnh sau để xem số dư của wAR trong quy trình hiện tại . Dưới đây là wAR tôi còn lại sau khi thực hiện nó khoảng 5 lần. Số lượng tiêu thụ có liên quan đến độ dài của mã thông báo và giá thời gian thực hiện tại khi chạy một mô hình lớn. Ngoài ra, nếu yêu cầu hiện tại ở trạng thái tắc nghẽn, một khoản phí bổ sung sẽ được tính. (Cuối bài viết mình sẽ phân tích chi tiết cách tính chi phí dựa trên code. Các bạn quan tâm có thể xem qua)
Lưu ý: Dấu thập phân ở đây là 12 chữ số, tức là 999999673 đại diện cho 0,000999999673 chiến tranh.

3 . Cài đặt/Cập nhật APM

APM là viết tắt của ao package management. Để xây dựng quy trình AI, bạn cần cài đặt gói tương ứng thông qua APM. Thực hiện lệnh trên và dấu nhắc tương ứng sẽ xuất hiện, cho biết quá trình cài đặt/cập nhật APM thành công.
4. Cài đặt Llama Herder

Sau khi quá trình thực thi hoàn tất, sẽ có một đối tượng Llama trong quy trình, đối tượng này có thể được truy cập bằng cách nhập Llama, sau đó Llama Herder sẽ đã cài đặt thành công.

Lưu ý : Nếu không có đủ wAR trong quá trình chạy, phương thức Llama.run không thể được thực thi và Lỗi Truyền sẽ xảy ra. Bạn cần làm theo bước đầu tiên để nạp tiền wAR.
5. Xin chào Llama
Tiếp theo, chúng ta thực hiện một tương tác đơn giản. Hỏi quy trình AI "Ý nghĩa của cuộc sống là gì?" và giới hạn việc tạo ra tối đa 20 mã thông báo. Sau đó đưa kết quả vào OUTPUTS. Quá trình thực thi quy trình AI mất vài phút và nếu có các tác vụ AI xếp hàng đợi, bạn sẽ phải đợi lâu hơn.
Như được trả về trong đoạn mã bên dưới, AI trả lời "Ý nghĩa của cuộc sống là một câu hỏi sâu sắc và mang tính triết học luôn mê hoặc con người."

Lưu ý: Tại đây Nếu không có đủ wAR trong quá trình chạy, phương thức Llama.run không thể được thực thi và Lỗi Truyền sẽ xảy ra. Bạn cần làm theo bước đầu tiên để nạp tiền wAR.
6. Tạo một Llama Joker
Tiến thêm một bước nữa, chúng ta hãy xem cách thực hiện Llama Joker. (Do không gian hạn chế nên chỉ hiển thị mã lõi liên quan đến AI.)
Việc xây dựng Llama Joker thực sự khá đơn giản, tương tự như việc xây dựng một chatbot trong ứng dụng AI Web 2.
Đầu tiên, hãy sử dụng <|system|> / <|user|> xây dựng Lời nhắc để phân biệt giữa các vai trò khác nhau.
Thứ hai, xác định phần nhắc cố định. Trong trường hợp của Llama Joker, nội dung của <|system|> "Kể chuyện cười về chủ đề đã cho".
Cuối cùng, xây dựng Llama Joker Npc để tương tác với người dùng. Nhưng vì lý do không gian, biến cục bộ userContent = "cats" được xác định trực tiếp ở đây. Nó cho thấy người dùng muốn nghe một câu chuyện cười liên quan đến mèo.
Không dễ dàng như vậy sao?


Thêm
Khả năng triển khai AI trên chuỗi là điều mà trước đây không thể tưởng tượng được. Giờ đây có thể triển khai các ứng dụng có độ hoàn thiện cao dựa trên AI trên AO. Triển vọng rất thú vị và mang đến cho mọi người không gian tưởng tượng không giới hạn.
Nhưng hiện tại, những hạn chế là tương đối rõ ràng. Hiện tại, nó chỉ có thể hỗ trợ "các mô hình ngôn ngữ nhỏ" khoảng 2 GB và chưa thể sử dụng GPU để tính toán. May mắn thay, thiết kế kiến trúc của AO cũng có những giải pháp tương ứng cho những khuyết điểm này. Ví dụ: biên dịch một máy ảo wasm có thể tận dụng GPU.
Chúng tôi mong muốn AI có thể nở thêm nhiều bông hoa rực rỡ hơn nữa trên chuỗi AO trong tương lai gần.
Phụ lục
Phía trước còn một cái hố, chúng ta cùng xem cách tính chi phí của Llama AI.
Sau đây là đối tượng Llama sau khi khởi tạo, giúp tôi hiểu rõ hơn về các đối tượng quan trọng.
M.herder: Lưu trữ mã định danh hoặc địa chỉ của dịch vụ Llama Herder.
M.token: Token dùng để thanh toán cho các dịch vụ AI.
M.feeBase: Phí cơ bản, giá trị cơ bản dùng để tính tổng phí.
M.feeToken: Phí tương ứng với mỗi token được sử dụng để tính phí bổ sung dựa trên số lượng token trong yêu cầu.
M.lastMultiplier: Hệ số nhân của phí giao dịch cuối cùng, có thể được sử dụng để điều chỉnh phí hiện tại.
M.queueLength: Độ dài của hàng đợi yêu cầu hiện tại ảnh hưởng đến việc tính toán chi phí.
M.feeBump: Hệ số tăng trưởng phí, cài đặt mặc định là 1,005, nghĩa là tăng 0,5% mỗi lần.

Giá trị ban đầu của M.feeBase là 0.
Yêu cầu thông tin giá mới nhất từ Llama Herder thông qua chức năng M.getPrices.
Trong số đó, M.feeBase, FeeToken, M.lastMultiplier và M.queueLength đều thay đổi theo thời gian thực sau khi yêu cầu M.herder và nhận được tin nhắn Phản hồi thông tin. Đảm bảo rằng các giá trị trường liên quan đến giá luôn được cập nhật.
Các bước tính phí cụ thể:
Thêm chargeToken theo M.feeBase Nhân với số lượng token sẽ thu được một khoản phí ban đầu.
Nhân chi phí ban đầu với M.lastMultiplier.
Cuối cùng, nếu có hàng đợi yêu cầu, nó sẽ được nhân với M.feeBump, tức là 1,005 để có được khoản phí cuối cùng.
Liên kết trích dẫn
1. Địa chỉ mẫu trên Arweave:
https://arweave.net/ISrbGzQot05rs_HKC08O_SmkipYQnqgB1yC3mjZZeEo
2. mã nguồn aos llama:
https://github.com/samcamwilliams/aos-llama
3. Cầu nối chuỗi AOX:
https://aox .arweave.dev/


 Weatherly
Weatherly





