كيف تعمل الشبكة المسرّعة (1)؟
في مقال اليوم، سنستمر في التعريف بالشبكة المسرّعة وسنشرح بوضوح مبادئ التشغيل والتقنيات ذات الصلة بالشبكة المسرّعة.
 JinseFinance
JinseFinance

في بداية عام 2024، ألقت OpenAI قنبلة أخرى للذكاء الاصطناعي على العالم - نموذج توليد الفيديو Sora.
تمامًا مثل ChatGPT قبل عام، تعتبر Sora بمثابة لحظة بارزة أخرى في AGI (الذكاء العام الاصطناعي).
"يعني Sora أنه سيتم اختصار تنفيذ الذكاء الاصطناعي العام من 10 سنوات إلى سنة واحدة"، توقع تشو هونغ يي، رئيس 360.
لكن هذا النموذج مثير للغاية ليس فقط لأن مقاطع الفيديو التي تم إنشاؤها بواسطة الذكاء الاصطناعي أطول وأعلى في الوضوح، ولكن لأن OpenAI تجاوزت جميع مقاطع الفيديو السابقة. تعمل قدرة AIGC على إنشاء محتوى فيديو يتعلق بالعالم المادي الحقيقي.
إن لعبة السايبربانك التي لا معنى لها رائعة، ولكن كيف يمكن إعادة إنتاج كل شيء في العالم الحقيقي بواسطة الذكاء الاصطناعي أكثر أهمية.
ولتحقيق هذه الغاية، اقترحت OpenAI مفهومًا جديدًا تمامًا - World Simulator.
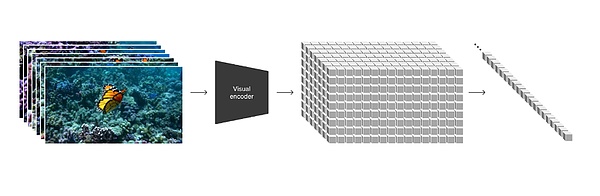
في التقرير الفني الصادر رسميًا عن OpenAI، تم وضع Sora باعتباره"نموذجًا لتوليد الفيديو كمحاكي عالمي"، "تظهر نتائج بحثنا أن توسيع نموذج إنشاء الفيديو هو وسيلة مجدية لبناء محاكاة عامة للعالم المادي."

(المصدر: موقع OpenAI الرسمي) تعتقد شركة OpenAI أنوضعت Sora الأساس لنماذج يمكنها فهم ومحاكاة العالم الحقيقي، الأمر الذي سيكون بمثابة علامة فارقة مهمة في تحقيق ذلك من AGI. وبهذا تكون قد فصلت نفسها تمامًا عن شركات مثل Runway وPika في مسار فيديو الذكاء الاصطناعي. من النص (ChatGPT) إلى الصور (DALL·E) إلى الفيديو (Sora)، بالنسبة لـ OpenAI، يشبه الأمر جمع قطع الألغاز واحدة تلو الأخرى، ومحاولة كسر الحدود تمامًا بين الواقع الافتراضي والواقع من خلال شكل وسائط الصور. ليصبح فيلم "Ready Player One" شبيهًا بالوجود. إذا كانت Apple Vision Pro هي شاشة عرض الأجهزة للاعب رقم واحد، فإن نظام الذكاء الاصطناعي الذي يمكنه تلقائيًا بناء عالم افتراضي محاكاة هو الروح. "نموذج اللغة يقارب الدماغ البشري، ونموذج الفيديو يقارب العالم المادي"، قال ياو فو، طالب الدكتوراه في جامعة إدنبره. "طموح OpenAI يفوق خيال الجميع، ولكن يبدو أنه الوحيد القادر على القيام بذلك." اشتكى العديد من رواد الأعمال في مجال الذكاء الاصطناعي من طريق Light Cone Intelligence. كيف أصبح سورا "محاكيًا للعالم"؟ فتح نموذج Sora الذي تم إصداره حديثًا من OpenAI الباب أمام مسار فيديو الذكاء الاصطناعي في عام 2024، وهو مختلف تمامًا عن ذلك في عام 2023 تم رسم الخط الفاصل بين العالم القديم. في مقاطع الفيديو التوضيحية الـ 48 التي تم إصدارها في نفس واحد، وجدت Light Cone Intelligence أن معظم المشكلات التي تم انتقادها لمقاطع فيديو الذكاء الاصطناعي في الماضي قد تم حلها: إنشاء صور أكثر وضوحًا، وتأثيرات إنشاء أكثر واقعية، وفهم أكثر دقة، وفهم منطقي أكثر سلاسة، ونتائج إنشاء أكثر استقرارًا وثباتًا، وما إلى ذلك. ولكن كل هذا مجرد غيض من فيض الذي أظهرته OpenAI،لأن OpenAI لم تكن تستهدف مقاطع الفيديو منذ البداية، بل كل الصور الموجودة . . الصورة مفهوم أكبر، والفيديو مجموعة فرعية منه، مثل شاشات التمرير الكبيرة في الشارع والمشاهد الافتراضية في عالم اللعبة الخ ما تريد OpenAI فعله هو استخدام الفيديو كنقطة دخول لتغطية جميع الصور ومحاكاة وفهم العالم الحقيقي، وهو مفهوم "محاكاة العالم" الذي تؤكد عليه. كما قال Chen Kun، منتج فيلم الذكاء الاصطناعي "Wonderland of Mountains and Seas" وثقافة Xingxian، لـ Lightcone Intelligence، "إن OpenAI تظهر لنا قدراتها القدرات في الفيديو. ولكن الغرض الحقيقي هو الحصول على بيانات تعليقات الأشخاص لاستكشاف نوع مقاطع الفيديو التي يرغب الأشخاص في إنتاجها والتنبؤ بها. تمامًا مثل تدريب النماذج الكبيرة، بمجرد فتح الأداة، ستكون مكافئة للأشخاص في جميع أنحاء العالم الذين يعملون لذلك، من خلال وضع العلامات والإدخال المستمر، يجعل نموذجها العالمي أكثر ذكاءً وأكثر ذكاءً." لذلك نرى أنفيديو الذكاء الاصطناعي أصبح وسيلة للفهم العالم المادي: في المرحلة الأولى، يسلط الضوء بشكل أساسي على خصائصه باعتباره "نموذج توليد الفيديو"، وفي المرحلة الثانية، يمكن أن يوفر قيمة باعتباره "محاكيًا للعالم". إن جوهر استيعاب سمة "إنشاء الفيديو" الخاصة بسورا هو العثور على الاختلافات، أي Sora وRunway وبيكا أين ينعكس الفرق؟ هذا السؤال مهم لأنه يفسر إلى حد ما سبب قدرة سورا على الانسحاق. بادئ ذي بدء، يتبع OpenAI فكرة تدريب نموذج لغوي كبير، باستخدام بيانات مرئية واسعة النطاق لتدريب نموذج توليدي مع عام قدرات. هذا يختلف تمامًا عن منطق "الموظفين المتفانين فقط" في مجال فيديو Wensheng. في العام الماضي، كان لدى شركة Runway خطة مماثلة، والتي أطلقت عليها اسم "النموذج العالمي العالمي"، وكانت الفكرة مشابهة تقريبًا، ولكن لم تكن هناك متابعة، وهذه المرة أخذ سورا زمام المبادرة في تحقيق حلم Runway. وفقًا لحسابات البروفيسور المساعد بجامعة نيويورك Xie Saining، يبلغ عدد معلمات Sora حوالي 3 مليارات. وعلى الرغم من أنها غير مهمة مقارنة بنموذج GPT، إلا أن هذا لقد تجاوز حجم هذا الهجوم بكثير مستوى Runway و Pika، وبالنسبة لبعض الشركات، يمكن أن يطلق عليه هجوم تقليل الأبعاد. علق Qi Borquan، المدير العام لمركز Wanxing Technology AI Innovation Center، بأن نجاح Sora أثبت مرة أخرى إمكانية حدوث "معجزات كبيرة"، "لا يزال Sora يتبع توسيع نطاق OpenAI Law، يعتمد على العمل الجاد لتحقيق المعجزات، وكمية كبيرة من البيانات، ونماذج كبيرة، وكمية كبيرة من القوة الحاسوبية. تستخدم الطبقة السفلية من Sora نماذج عالمية تم التحقق منها في مجالات الألعاب، والقيادة بدون سائق، والروبوتات لبناء فيديو فنسنت. نموذج لتحقيق القدرة على محاكاة العالم." ثانيًا، أظهر Sora لأول مرة التكامل المثالي بين نموذج الانتشار وقدرات النموذج الكبيرة. يشبه فيديو الذكاء الاصطناعي الأفلام الرائجة، ويعتمد على عنصرين مهمين: النص والمؤثرات الخاصة. من بينها، يتوافق البرنامج النصي مع "المنطق" في عملية إنشاء فيديو الذكاء الاصطناعي، وتتوافق المؤثرات الخاصة مع "التأثير". ومن أجل تحقيق "المنطق" و"التأثير"، يتم التمييز بين مسارين تقنيين خلف نموذج الانتشار والنموذج الكبير. في نهاية العام الماضي، توقع Light Cone Intelligence أنه من أجل تلبية كل من التأثيرات والمنطق، فإن طريقي الانتشار والنماذج الكبيرة سوف يتقاربان في النهاية. وبشكل غير متوقع، قامت OpenAI بحل هذه المشكلة بهذه السرعة. (المصدر: موقع OpenAI الرسمي) OpenAI يجذب أبرز التقارير الفنية : "يعمل نهجنا على تحويل أنواع مختلفة من البيانات المرئية إلى تمثيل موحد يمكن استخدامه للتدريب واسع النطاق للنماذج التوليدية." على وجه التحديد، يقوم OpenAI بتشفير كل منها إطار الفيديو إلى تصحيحات مرئية، تشبه كل تصحيح رمزًا مميزًا في GPT وتصبح أصغر وحدة قياس في مقاطع الفيديو والصور، ويمكن كسرها وإعادة تنظيمها في أي وقت وفي أي مكان. وبعد أن وجدنا طريقة لتوحيد البيانات وتوحيد الأوزان والمقاييس، وجدنا جسراً بين نموذج الانتشار والنموذج الكبير. خلال عملية التوليد بأكملها، لا يزال نموذج الانتشار مسؤولاً عن تأثير التوليد. بعد إضافة آلية الانتباه للنموذج الكبير للمحول، سيكون هناك المزيد من التحكم على مدار الجيل، يتمتع بقدرات التنبؤ والاستدلال، وهو ما يفسر قدرة Sora على إنشاء مقاطع فيديو من الصور الثابتة المكتسبة الموجودة، ويمكنه أيضًا توسيع مقاطع الفيديو الموجودة أو ملء الإطارات المفقودة. منذ تطويرها، أظهرت نماذج الفيديو اتجاهًا للمركب. وبينما تتجه النماذج نحو الاندماج، تتجه التكنولوجيا أيضًا نحو المركب. أصبح تطبيق تراكم التكنولوجيا المتراكمة مسبقًا على النماذج المرئية أيضًا ميزة OpenAI. أثناء عملية التدريب على فيديو Sora Vincent، قدمت OpenAI إمكانات فهم اللغة لـ DALL-E3 وGPT. وفقًا لـ OpenAI، يمكن للتدريب المعتمد على DALL-E3 وGPT أن يمكّن Sora من إنشاء مقاطع فيديو عالية الجودة بدقة وفقًا لمطالبات المستخدم. بعد مجموعة من اللكمات المجمعة، تكون النتيجة قدرة المحاكاة، والتي تشكل أساس "محاكي العالم". "لقد وجدنا أن نماذج الفيديو تعرض عددًا من القدرات الناشئة المثيرة للاهتمام عند تدريبها على نطاق واسع. هذه القدرات تجعل Sora قادرًا على محاكاة بعض القدرات "جوانب الناس والحيوانات والبيئات في العالم المادي. تنشأ هذه الخصائص دون أي تحيز استقرائي واضح تجاه الأبعاد الثلاثة والأشياء وما إلى ذلك. - إنها ظواهر ذات حجم بحت". السبب الأساسي الذي يجعل "المحاكاة" تنفجر كثيرًا هو أن الناس معتادون على استخدام نماذج كبيرة لإنشاء أشياء غير موجودة، لكنهم يستطيعون ذلك بدقة فهم الفيزياء. منطق كيفية عمل العالم، مثل كيفية تفاعل القوى، وكيفية توليد الاحتكاك، وكيف تضرب كرة السلة القطع المكافئ، وما إلى ذلك. هذه أشياء لم يتمكن أي نموذج سابق من تحقيقها، وهذا هو المعنى الأساسي سورا يتجاوز مستوى توليد الفيديو. ومع ذلك، من العرض التوضيحي إلى المنتج النهائي الفعلي، قد يكون ذلك مفاجأة أو صدمة. سأل يانغ ليكون، كبير علماء ميتا، سورا مباشرة، وقال: "إن مجرد القدرة على إنشاء مقاطع فيديو واقعية بناءً على المطالبات لا يعني أن النظام يفهم حقًا العالم المادي. تختلف عملية التوليد عن التنبؤ السببي استنادًا إلى النماذج العالمية "النماذج التوليدية ما عليك سوى العثور على عينة معقولة من مساحة الاحتمال، دون فهم ومحاكاة العلاقة السببية في العالم الحقيقي." كما قال Qi Borquan أنه على الرغم من أن OpenAI قد تم التحقق من أن نموذج فيديو فنسنت الكبير المبني على النموذج العالمي ممكن، إلا أن هناك أيضًا صعوبات في دقة التفاعلات الفيزيائية، وعلى الرغم من أن سورا يمكنه محاكاة بعض التفاعلات الفيزيائية الأساسية، إلا أنه قد يواجه صعوبات عند التعامل مع المزيد الظواهر الفيزيائية المعقدة؛ هناك تحديات في التعامل مع التبعيات طويلة المدى، أي كيفية الحفاظ على الاتساق الزمني والمنطق؛ دقة التفاصيل المكانية. إذا لم تكن معالجة التفاصيل المكانية دقيقة بما فيه الكفاية، فقد يؤثر ذلك على الدقة والمصداقية من محتوى الفيديو. فيديو مزعج، ولكنه أكثر من مجرد فيديو ربما أصبح Sora محاكيًا للعالم منذ وقت طويل، ولكن فيما يتعلق بإنشاء مقاطع الفيديو، فقد كان له بالفعل تأثير على العالم الحالي. الفئة الأولى هي حل المشكلات التي لم يكن من الممكن حلها في التقنيات السابقة ودفع بعض الصناعات إلى مرحلة جديدة. أكثرها شيوعًا هي صناعة الإنتاج السينمائي والتلفزيوني. القدرة الأكثر ثورية لسورا هذه المرة هي أن أطول طول فيديو تم إنشاؤه يصل إلى 1 دقيقة. كمرجع، يمكن لفيديو Pika الشهير أن يولد طولًا يصل إلى 3 ثوانٍ، ويمكن لـ Runway's Gen-2 أن يولد طولًا يصل إلى 18 ثانية، وهذا يعني أنه مع Sora، سيصبح فيديو الذكاء الاصطناعي إنتاجية حقيقية، مما يؤدي إلى تقليل التكلفة وتحسين الكفاءة. أخبر تشين كون شركة Guangcone Intelligence أنه قبل ولادة Sora، انخفضت تكلفة استخدام أدوات فيديو الذكاء الاصطناعي لإنتاج أفلام الخيال العلمي إلى النصف. وبعد إطلاق Sora، لقد أصبح الأمر أكثر جدارة بالاهتمام. بعد إطلاق سراح سورا، كان أكثر ما أثار إعجابه هو عرض دولفين يركب دراجة. في هذا الفيديو، الجزء العلوي من الجسم عبارة عن دولفين، والجزء السفلي من الجسم عبارة عن ساقين بشريتين، ويوجد حذاء على الساقين، وبأسلوب غريب جدًا في الرسم، يكمل الدولفين حركة ركوب الدراجة كإنسان. "هذا أمر مذهل بالنسبة لنا بكل بساطة! هذه الصورة تخلق إحساسًا بالعبثية التي هي خيالية ومتوافقة مع قوانين الفيزياء. إنها معقولة وغير متوقعة في نفس الوقت. وهذا ما يجعل الجمهور مندهشًا. أعمال السينما والتلفزيون "، قال تشين كون. يعتقد تشين كون أنسوف يخفض Sora عتبة جميع منشئي المحتوى بخطوة كبيرة، تمامًا مثل الهواتف الذكية وDouyin في ذلك الوقت. . "في المستقبل، قد لا يحتاج منشئو المحتوى إلى التقاط صور. ما عليهم سوى قول فقرة أو كلمة للتعبير عن الأفكار الفريدة في رؤوسهم. اخرج ليشاهدهم عدد أكبر من الأشخاص. بحلول ذلك الوقت، أعتقد أنه قد تكون هناك منصة جديدة أكبر من Douyin. باتخاذ خطوة إلى الأمام، ربما يتمكن Sora من فهم أفكار العقل الباطن لكل شخص وإنشاء محتوى وإنشاءه تلقائيًا لا يتطلب مستخدمين قال تشين كون: "للبحث بنشاط عن التعبير". وتشمل نفس الصناعة أيضًا الألعاب، نهاية التقرير الفني لـ OpenAI عبارة عن فيديو لعبة "Minecraft" مكتوب بجانبه الجملة التالية: "Sora" يمكنه التحكم في اللاعبين في لعبة Minecraft في نفس الوقت من خلال الاستراتيجيات الأساسية مع عرض العالم وديناميكياته بدقة عالية. سيؤدي مجرد ذكر "Minecraft" في ترجمات Sora السريعة إلى تشغيل هذه الميزات عن قرب." "كما قال OpenAI فإن Sora عبارة عن محاكي ومحرك ألعاب وواجهة تحويل بين الخيال والعالم الحقيقي. المستقبل للألعاب ، طالما أنك تتحدث عن ذلك، يمكن عرض الصورة. لقد تعلمت Sora الآن كيفية بناء عالم في دقيقة واحدة، ويمكنها أيضًا إنشاء شخصيات مستقرة. إلى جانب GPT-5 الخاص بها، وهو جهاز تم إنشاؤه بواسطة الذكاء الاصطناعي تمامًا، الآلاف من كيلومترات مربعة، خريطة مليئة بالمخلوقات النشطة ذات الألوان المختلفة، لم تعد تبدو وكأنها خيال. بالطبع، ما إذا كان يمكن إنشاء الشاشة في الوقت الفعلي وما إذا كانت تدعم اللعب المتعدد عبر الإنترنت هي مشكلات حقيقية للغاية. ولكن بغض النظر عن أي شيء ، وضع اللعبة الجديد قادم بالفعل، على الأقل مع أنه لا توجد مشكلة بالنسبة لـ Sora في إنشاء "لقد انتهى الأمر، أنا محاط بالجميلات"،" قال Chen Xidao. الفئة الثانية تعتمد على القدرة على محاكاة العالم لخلق أشياء جديدة في المزيد من المجالات. قال ياو فو، طالب الدكتوراه في جامعة إدنبره: "تتعلم النماذج التوليدية الخوارزميات التي تولد البيانات، بدلاً من تذكر البيانات نفسها . تمامًا مثل اللغة، تمامًا كما تقوم النماذج بتشفير الخوارزميات (في دماغك) التي تولد اللغة، تقوم نماذج الفيديو بتشفير المحركات الفيزيائية التي تولد تدفقات الفيديو.يمكن اعتبار نماذج اللغة تقريبية للعقل البشري، في حين تقارب نماذج الفيديو العالم المادي."< /p> إن تعلم القوانين العالمية في العالم المادي يجعل الذكاء المتجسد أقرب إلى الذكاء البشري. على سبيل المثال، في مجال الروبوتات، كانت عملية الإرسال السابقة تتمثل في إعطاء تعليمات المصافحة أولاً إلى دماغ الروبوت ثم تمريرها إلى اليد. ، نظرًا لأن الروبوت لا يمكنه حقًا فهم معنى "المصافحة"، لذلك لا يمكن تحويل التعليمات إلا إلى "كم سنتيمترًا يمكن تقليل قطر اليد إليه؟" إذا أصبحت محاكاة العالم حقيقة واقعة، فيمكن للروبوتات تخطي عملية تحويل الأوامر مباشرة وفهم احتياجات القيادة البشرية في خطوة واحدة. أعرب جيا كوي، مؤسس الذكاء متعدد الأبعاد والأستاذ في جامعة جنوب الصين للتكنولوجيا، لـ Light Cone Intelligence عن إمكانية تطبيق محاكاة فيزيائية صريحة بالنسبة للروبوتات في مجال المستقبل، "إن محاكاة سورا الفيزيائية ضمنية. فهي تُظهر تأثيرات لا يمكن توليدها إلا من خلال فهمها الداخلي ومحاكاة العالم المادي. ولكي تكون مفيدة بشكل مباشر للروبوتات، أعتقد أنه من الأفضل جعلها واضحة. " "لا تزال قدرات Sora تتحقق من خلال بيانات الفيديو الضخمة وتقنية إعادة التسجيل. ولا توجد حتى نماذج واضحة ثلاثية الأبعاد، ناهيك عن المحاكاة المادية. . وقال جاكي: "على الرغم من أن التأثير الذي يولده قد وصل/قريبًا من التأثير الذي تم تحقيقه من خلال المحاكاة الفيزيائية، إلا أن محرك الفيزياء يمكنه القيام بأكثر من مجرد إنشاء مقاطع فيديو، وهناك العديد من العناصر الأخرى الضرورية لتدريب الروبوتات". على الرغم من أن Sora لا يزال لديه العديد من القيود، إلا أنه تم إنشاء رابط بين العالمين الافتراضي والحقيقي، مما يجعل ما إذا كان عالمًا افتراضيًا جاهزًا للاعب واحد، سواء كانت الروبوتات تشبه البشر أم لا، فكلاهما مليئ بإمكانيات أكبر. 
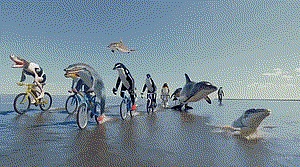

أخبرنا رائد ألعاب الذكاء الاصطناعي Chen Xi "أي ممارس للعبة سوف يتصبب عرقاً عندما يرى هذه الجملة! OpenAI تظهر طموحاتها دون تحفظ." يعتقد تفسير وتحليل Chen Xi أن هذه الجملة القصيرة تنقل شيئين:يستطيع Sora التحكم في شخصية اللعبة وفي نفس الوقت عرض بيئة اللعبة.
في مقال اليوم، سنستمر في التعريف بالشبكة المسرّعة وسنشرح بوضوح مبادئ التشغيل والتقنيات ذات الصلة بالشبكة المسرّعة.
JinseFinanceArweave، مبدأ عمل Arweave وأهميته، تقدم هذه المقالة باختصار مبدأ عمل Arweave وقيمته.
JinseFinanceيستخدم نموذج الذكاء الاصطناعي الجديد من جوجل، HeAR، التحليل الصوتي الحيوي للكشف عن العلامات المبكرة للحالات الصحية من خلال تحليل الأصوات مثل السعال والتنفس. من خلال الشراكة مع Salcit Technologies، تهدف جوجل إلى تحسين الكشف المبكر عن الأمراض وإمكانية الوصول إليها، على الرغم من التحديات التي لا تزال قائمة في ضمان دقة الذكاء الاصطناعي واكتساب الثقة الطبية.
 Joy
Joyتتميز Zircuit، وهي شبكة من الطبقة الثانية من Ethereum، بمنظم التسلسل المدعوم بالذكاء الاصطناعي لتعزيز أمان المعاملات وكفاءتها، حيث تجتذب أكثر من 3.3 مليار دولار من الأصول المرهونة قبل إطلاق شبكتها الرئيسية بدعم من Binance Labs.
Joy"قبل يومين، أجرت وسائل الإعلام الأجنبية مقابلة حصرية مع فريق سورا الأساسي. بعد مشاهدة الفيديو الأصلي، بدا الأمر وكأن شيئًا لم يُقال. بدا المشهد وكأنه خطاب ألقاه رئيس القسم ما في اللجنة الوطنية للتنمية والإصلاح.
JinseFinanceاستكشف مستقبل تكامل الذكاء الاصطناعي وWeb3: قوة الحوسبة اللامركزية، والبيانات الضخمة، وابتكار Dapp، وتأثيرها العميق على الابتكار الصناعي.
JinseFinanceهناك أربع طرق لدمج الذكاء الاصطناعي وWeb3: قوة الحوسبة اللامركزية، والخوارزمية والتعاون النموذجي، والبيانات الضخمة اللامركزية، والتطبيق اللامركزي المدعم بالذكاء الاصطناعي.
JinseFinanceلماذا يمكن تسمية سورا بعلامة فارقة جديدة في صناعة الذكاء الاصطناعي؟ كيف اخترقت AIGC، الحد الأعلى لإنشاء محتوى الذكاء الاصطناعي؟ من الناحية الموضوعية، هل هناك أي قيود أو عيوب في الإصدار الحالي من سورا؟
JinseFinanceSora هو نموذج ذكاء اصطناعي تم تطويره بواسطة OpenAI يمكنه إنشاء مشاهد فيديو واقعية ومتخيلة بناءً على تعليمات نصية يدخلها المستخدم.
JinseFinanceمسار الذكاء الاصطناعي يزدهر من جديد، ما هي المشاريع التي تحقق أداء جيد وما هي القوى الجديدة التي تظهر؟
JinseFinance