アルウィーヴの寄付メカニズムを理解する:探査とモデル化
この論文では、保存された寄付がどのように機能するのかを詳しく説明し、マルコフ連鎖を使ってその実行をモデル化することで、その特性とリスクプロファイルを検証する。
 JinseFinance
JinseFinance

Author: Arweave Oasis
私たちは、以前の記事Arweaveのコンセンサス・メカニズムの反復で、バージョン2.6のより包括的な反復を約束した、過去5年間のArweaveの反復の旅について学びました。Arweaveの反復的合意メカニズムでは、Arweaveのバージョン2.6のより包括的な分析を提供すると約束しましたが、その約束を果たすためにここに来ました。この記事では、その約束を果たすべく、バージョン2.6におけるArweaveのコンセンサスメカニズムの設計の詳細について説明します。
ビットコインが次の半減期を迎えるまで、あと1ヶ月ほどあります。しかし著者は、サトシ・ナカモトのビジョン--誰もがCPUを使って参加できるコンセンサス--は実現されていないと考えている。とはいえ、Arweaveのメカニズムの反復は、サトシ・ナカモトのオリジナルのビジョンにより忠実だったかもしれないし、バージョン2.6によって、Arweaveネットワークはサトシ・ナカモトの期待に真に適合し始めることができる。
ハードウェアアクセラレーションを制限することで、汎用グレードのCPU + 機械式ハードドライブがシステムのコンセンサスの維持に関与できるようにし、ストレージコストを削減します。
コンセンサスのコストを、エネルギーではなく、効率的なデータストレージにできるだけ向けます。
エネルギー集約的なハッシュ化競争ではなく、効率的なデータストレージに向けます。
マイナーがArweaveデータセットの完全なコピーを独自に構築するよう促し、より高速なデータルーティングと分散ストレージを可能にします。
上記の目標に基づき、メカニズムの2.6バージョンはおおよそ次のようになっています:
Hash Chainと呼ばれる新しいコンポーネントがオリジナルのSPoRAメカニズムに追加されました。これは、1秒ごとにSHA-256マイニングハッシュを生成する、前述の暗号アルゴリズムクロックです。
採掘者は、自分の保存しているデータパーティション内のパーティションのインデックスを選択し、採掘ハッシュと採掘アドレスとともに採掘入力として使用して採掘を開始します。
採掘者が選択したパーティションにバックトラック範囲1を生成し、ウィーブネットワークのランダムな位置に別のバックトラック範囲2を生成する。
バックトラック範囲1のバックトラックチャンク(Chunks)を順番に使用して計算し、ブロックソリューションかどうかを判断しようとする。計算結果が現在のネットワーク難易度よりも大きい場合、マイナーにブロックを終了する権利が与えられ、失敗した場合、後方範囲内の次の後方ブロックが計算される。
範囲2のバックトラックブロックも計算によって検証される可能性があるが、そこでの解は範囲1からのハッシュを必要とする。
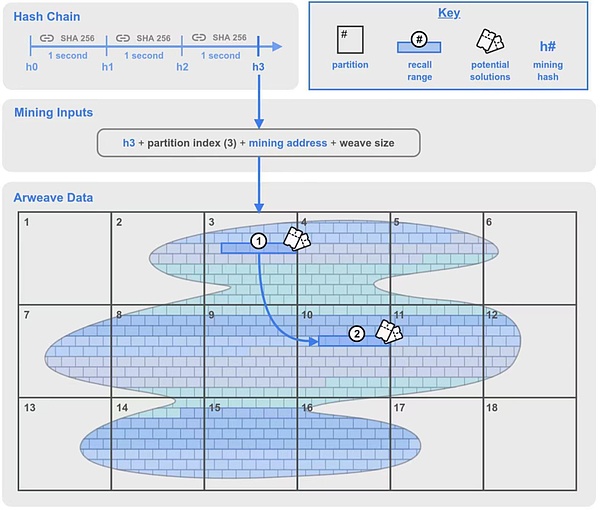
Fig.
Arweave Data:編まれたデータは、「編まれたネットワーク」とも呼ばれる。編まれたネットワーク」とも呼ばれる。ネットワーク内のデータはすべてチャンクと呼ばれる塊に分割される(上の写真のチャンクは「レンガの壁」のようなもの)。これらのチャンクはアーウィーブ・ネットワーク全体に均等に分散させることができ、メルケル・ツリーによって各チャンクにアドレッシング・スキーム(グローバル・オフセットとも呼ばれる)が確立され、ネットワーク内の任意の場所でチャンクを識別することができます。
チャンク:各チャンクのサイズは通常256KBで、チャンクを獲得するには、採掘者は対応するチャンクをパックしてハッシュ化し、SPoRA採掘プロセス中にデータのコピーを保存したことを証明しなければなりません。
パーティション:「パーティション」はバージョン2.6の新しい概念です。3.6TBごとにパーティションがあります。パーティションはネットワークの先頭(インデックス0)から、ネットワーク全体をカバーするパーティションの数まで番号が振られています。
リコール範囲: リコール範囲もバージョン2.6の新しい概念です。これは、特定のオフセットから開始される、ウォーブン・ネットワーク内の一連の連続した100MBのチャンクです。チャンクあたり256KBで、バックホール範囲には400チャンクがある。このメカニズムでは、以下で詳しく説明するように、2つのバックホール範囲があります。
潜在的なソリューション:バックトラッキング範囲内の各256KBブロックは、ブロックから抜け出すための潜在的なソリューションとなります。マイニングプロセスの一環として、各ブロックはハッシュ化され、ネットワークの難易度要件を満たしているかどうかテストされます。もし満たしていれば、採掘者はブロックを抜ける権利を獲得し、採掘の報酬を得ます。そうでない場合、採掘者は次の256KBのブロックまでバックトラックを続けます。
Hash Chain:ハッシュチェーンはバージョン2.6の重要なアップデートで、ハッシュの最大量を制限するレートリミッターとして機能する暗号クロックを以前のSPoRAに追加しました。ハッシュ・チェーンは、SHA-256関数を使用してデータの一部を連続してハッシュすることで生成される。このプロセスは並列で行うことはできず(コンシューマーグレードのCPUであれば簡単に行える)、ハッシュチェーンは一定回数の連続ハッシュを行うことで1秒の遅延を実現する。
マイニングハッシュ:十分な数の連続したハッシュの後(つまり1秒間の遅延の後)、ハッシュチェーンはマイニングに有効だと考えられるハッシュ値を生成します。マイニングハッシュはすべてのマイナーの間で一貫性があり、すべてのマイナーによって検証できることに注意することが重要です。
必要な命名法の概念をすべて紹介した後、私たちはバージョン2.6がどのように機能するのか、どのように最良の戦略を得るのかをよりよく理解するために集まることができます。
これまで何度も取り上げてきたArweaveの全体的な目標は、ネットワーク上に保存されるデータのコピー数を最大化することです。しかし、何を保存するのか?そしてどのように?かなり多くの要件と入り口があります。ここでは、最適な戦略を採用する方法について説明します。
レプリカとコピー
バージョン2.6以降、さまざまな技術資料でレプリカやコピーという用語を頻繁に目にするようになりました。これは、メカニズムを理解する上で大きな障害になっています。理解しやすいように、私はレプリカを「コピー」、コピーを「バックアップ」と訳す傾向があります。
コピーとは、単にデータのコピーであるバックアップのことで、同じデータのバックアップ間で違いはありません。
レプリカ・コピーは一意性のことで、一意性のために一度処理されたデータを保存する行為です。アーウィーブ・ネットワークでは、バックアップの保存だけでなく、レプリカの保存も奨励しています。
注:バージョン2.7でコンセンサスメカニズムはSPoResになりました。これはSuccinct Proofs of Replications(レプリカの簡潔な証明)であり、今後説明するように、これがレプリカの保管です。
一意のレプリカをパッキングする
一意のレプリカはArweaveメカニズムにおいて非常に重要であり、採掘者がブロックを取り出せるようにするためには、自分自身の一意のレプリカを形成するために、すべてのデータを特定の形式でパッケージ化することが前提条件となります。
新しいノードを稼働させたい場合、他の採掘者がすでにパッケージ化したデータをコピーするだけではいけません。まずArweaveウィーブネットワークから生データをダウンロードして同期させる必要があり(もちろんすべてをダウンロードする必要はありませんが、一部だけでも問題ありませんし、危険なデータをフィルタリングするために独自のデータポリシーを設定することもできます)、次にRandomX関数を使ってその生データの各チャンクをパックし、潜在的なマイニングソリューションにします。
パッキングプロセスは、RandomX関数にパッキングキーを提供し、未加工データの塊をパッキングするために使用される結果を生成するために、RandomX関数にいくつかの処理を実行させることから構成されます。パックされたデータのブロックをアンパックするプロセスは同じで、パックキーを提供し、パックされたデータのブロックをアンパックするために複数の操作の結果を使用します。
バージョン2.5では、パッキングキーのバックアップは、chunk_offset(チャンクのオフセット、チャンクの位置パラメーターとも解釈できる)とtx_root(トランザクションルート)に関連付けられたSHA256ハッシュです。これにより、各マイニングソリューションが特定のブロックのデータブロックの一意のコピーから得られることが保証されます。データブロックの複数のバックアップが破壊的ネットワーク内の異なる場所に存在する場合、各バックアップは一意のコピーとして別々にバックアップされる必要があります。
バージョン2.6では、このバックアップキーは、chunk_offset、tx_root、miner_addressの関連付けのSHA256ハッシュに拡張されました。これは、各コピーが各マイナーのアドレスに対しても一意であることを意味する。
完全なコピーを保存する利点
このアルゴリズムは、採掘者が複数回複製された部分的なコピーではなく、一意の完全なコピーを構築することを提案しています。
この部分をどのように理解すればよいのでしょうか?下の2つの図を比較して理解しましょう。
まず、アーウィーブ骨折ネットワーク全体が合計16のデータパーティションを生成すると仮定してみましょう。
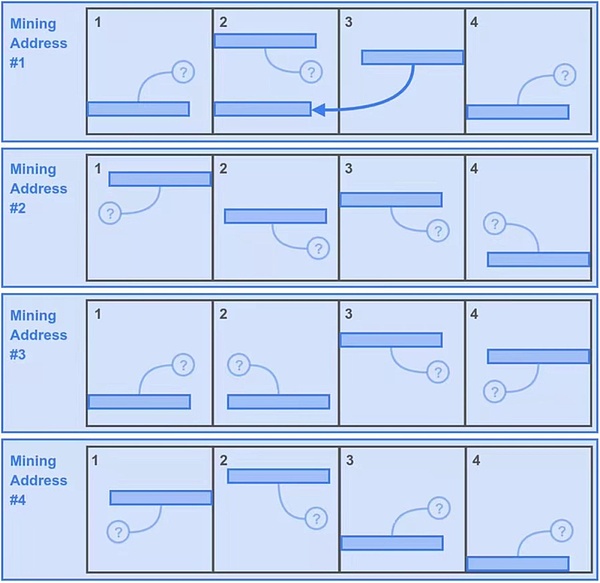
最初のシナリオ:
Bob the minerはデータをダウンロードするのは時間がかかりすぎると考え、破砕ネットワークの最初の4つのパーティションからしかデータをダウンロードしませんでした。
これら4つのパーティションの採掘コピーを最大化できるように、Bobはこれら4つのパーティションからデータのコピーを4つ作成し、それぞれ異なる4つの採掘アドレスを持つ4つのユニークなコピーリソースに形成することで、自分のストレージを4つのユニークなコピーリソースで満たすという素晴らしいアイデアを思いつきました。これは問題なく、ユニークコピーのルールに適合しています。
次に、Bobは1秒ごとにMining Hashを取得する際に、各パーティションに対して後方範囲の資料を生成することができます。これにより、Bobは1秒間に400* 16=6400の潜在的なマイニングソリューションを得ることができます。
しかし、Bobはその小さな工夫のために、2つ目の代償も支払いました。この「小さな疑問符」は、問題の2つ目の後方範囲がボブのハードドライブにないことを表しており、ボブが保存していないデータのパーティションを示しています。もちろん運が良ければ、ボブが保存している4つのパーティションを象徴する下側のライトもあり、これはちょうど25%、つまり1600の潜在的な解決策となります。
つまりこの戦略では、ボブは1秒間に6400+1600=8000の潜在的な解を得ることができます。
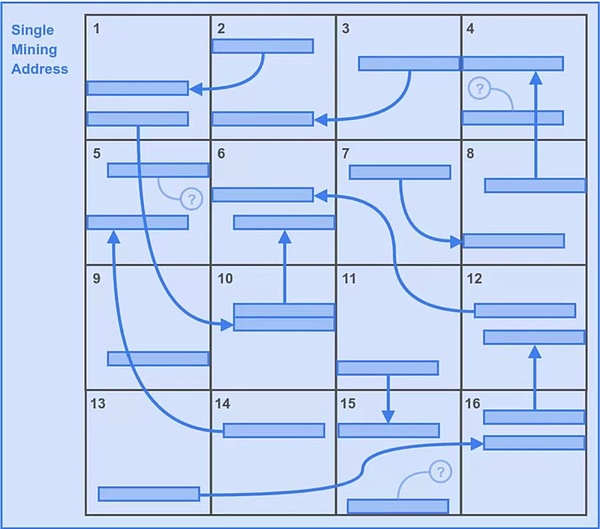
2つ目のシナリオ:
では、2つ目のシナリオを見てみよう。2つの後方範囲のメカニズムの配置により、優れた戦略は、問題のある複数のユニークなコピーを保存することです。これを図3に示す。
採掘者であるAliceは、Bobほど「スマートで賢い」わけではありません。彼女は本能的に16個のパーティションすべてのパーティションデータをダウンロードし、1つの採掘アドレスだけで16個のバックアップの一意のコピーを作成します。
アリスも16パーティションなので、バックトラックの最初の範囲の潜在的な解の総数はボブと同じで、6400になります。
しかしこの場合、アリスは2番目の後方範囲の潜在的な解をすべて手に入れます。これはさらに6400です。
つまり、これによってアリス戦略は1秒間に6400+6400=12800の潜在的な解を得ることになります。有利なのは自明だ。
バックトラック範囲の役割
おそらくあなたは、採掘者が2.5まで保管の証明を見つけて与えることができる関数で、個々のバックトラックブロックのオフセットをランダムにハッシュ化することがなぜそんなに重要なのか疑問に思っているでしょう。2.6ではなぜバックトラックの範囲をハッシュアウトしているのでしょうか?
その理由は簡単に理解できます。バックトラック範囲は連続したデータブロックで構成されており、機械式ハードディスク(HDD)の読み取りヘッドの動きを最小化するような構造になっているからに他なりません。このアプローチによってもたらされた物理的最適化によって、HDDの読み取り性能は、より高価なSSDハードディスク・ドライブ(SSD)と並ぶことができる。SSDに片手と片足を縛り付けているようなもので、もちろん、1秒間に4つの後方範囲を転送できる高価なSSDには、依然としてわずかな速度上の優位性がある。しかし、より安価なHDDに対するカウント数は、採掘者の選択を後押しする重要な指標となるでしょう。
次に、次の新しいブロックの検証について説明します。
新しいブロックを受け入れるには、バリデータはブロックプロデューサーによって同期された新しいブロックを検証する必要があります。
検証者がハッシュチェーンの現在の先頭にいない場合、各採掘ハッシュは25個の40ミリ秒のチェックポイントで構成されます。これらのチェックポイントは、連続する40ミリ秒のハッシュの結果であり、合わせて前の採掘ハッシュの開始からの1秒間隔を表します。
ベリファイアは、新しく受信したブロックを他のノードに伝播する前に、最初の25個のチェックポイントの検証を40ミリ秒で素早く完了させ、検証が成功すると、ブロックの伝播をトリガーし、残りのチェックポイントの検証の完了に進みます。完全なチェックポイントは、残りのすべてのチェックポイントを検証することで達成される。最初の25個のチェックポイントの後に、500個の検証済みチェックポイントが続き、さらに500個の検証済みチェックポイントが続きます。
マイニングハッシュを生成する際、ハッシュチェーンは1行でシーケンシャルでなければならない。しかし、チェックポイントを検証するベリファイアはハッシュ検証を行うことができるため、ブロックの検証をより短く効率的に行うことができます。
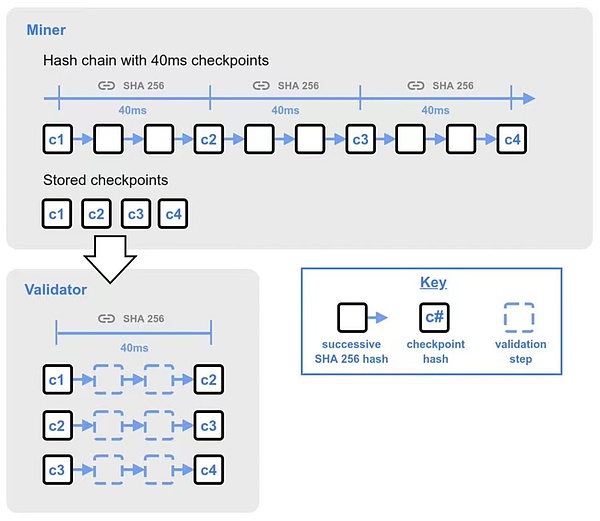
図4:ハッシュチェーンの検証プロセス
ハッシュチェーンのシード
マイナーまたはプールがより高速なSHA256ハッシュ計算能力を持っている場合、そのハッシュチェーンはネットワーク内の他のノードより先に進む可能性があります。時間が経つにつれて、このブロック速度の優位性が蓄積され、ハッシュチェーンのオフセットが大きくなり、他の検証者と同期していないマイニングハッシュが生成される可能性があります。これは一連の制御不能なフォークや再編成につながる可能性があります。
このようなハッシュチェーンのオフセットの可能性を減らすため、Arweaveは一定の間隔で過去のブロックのトークンを使用することで、グローバルなハッシュチェーンを同期させます。これにより、ハッシュチェーンに定期的に新しいトークンがシードされ、個々のマイナーのハッシュチェーンが検証済みブロックと同期されます。
ハッシュチェーンは、50 * 120の採掘ハッシュごとに新しいシードブロックが選択される間隔でシードされます(50はブロック数、120はブロック生成サイクルの2分以内の採掘ハッシュ数)。これにより、シードブロックは~50Arweaveブロックに1回出現することになりますが、ブロックのタイミングに多少のばらつきがあるため、シードブロックは50ブロックより少し早く出現することがあります。
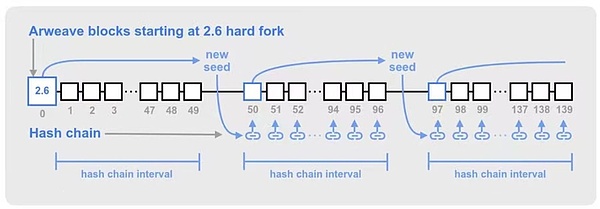
Figure 5: How hash chain seeds are generated
上記は著者が時間をかけて作成した2.6仕様からの抜粋であり、これらからArweaveが2.6以降、ネットワーク全体を運営するために、低消費電力で、その下にはより分散化された思想的メカニズムを実装していることがわかります。サトシ・ナカモトのビジョンはArweaveに生きている。
Arweave 2.6:
https://2-6-spec.arweave.dev/https://2-6-spec.arweave.dev
この論文では、保存された寄付がどのように機能するのかを詳しく説明し、マルコフ連鎖を使ってその実行をモデル化することで、その特性とリスクプロファイルを検証する。
JinseFinanceこの記事では、ArweaveとIPFSの冗長性メカニズム、そしてどちらのオプションがデータにとってより安全かを見ていきます。
JinseFinanceWhatsAppのメッセージは毎日1000億通送信されている。ほとんどのブロックチェーンは保存用に設計されていない。1000億件のWhatsAppメッセージをイーサや他のブロックチェーンに保存しようと思ったら、そのコストは法外なものになるだろう。
JinseFinance本稿では、ArweaveとIPFSがどのようにファイルを保存、維持、アクセスし、それがデジタル資産の信頼性と永続性にどのような影響を与えるかを探る。
JinseFinanceArweaveは分散型データ・ストレージ・ソリューションで、Blockweaveテクノロジーとネイティブ暗号通貨ARトークンを通じて、永続的で不変のデータ・ストレージ・サービスを提供する。
JinseFinanceArweaveがファイルコインの代替ではなく、もっと注目されるべき大きなイノベーションである理由。
JinseFinanceJinseFinanceこのイベントには100人以上のArweaveエコシステムの開発者や投資家が参加する予定で、参加者には製品テストの機会、ARエアドロップの報酬、実用的な商品などの限定特典が提供される。
 Samantha
Samantha Nulltx
Nulltx「今四半期、ビットコインマイニングのエネルギー効率と持続可能性が大幅に改善されました。この傾向は今後も続くでしょう」とMicroStrategyの創設者兼最高経営責任者(CEO)のマイケル・セイラー氏は述べた。
 Cointelegraph
Cointelegraph