ソラナチェーン上の分散型ストレージ・プラットフォーム、シャドウ・ドライブに関する記事
最高の分散型クラウド・コンピューティング・プラットフォームは?新しいプロジェクトは、ユーザーに新しい体験をもたらすかもしれない。
 JinseFinance
JinseFinance

出典:PermaDAO
現在市場で主流となっている分散型ストレージプラットフォームには、Arweave、Filecoin、Storjがあり、従来のクラウドストレージサービスとは対照的に、単一の中央管理ポイントに依存しないデータ保存方法を提供しています。Arweaveは1回限りの支払いモデルによる長期または永続的なストレージに重点を置いており、FilecoinとStorjはブロックチェーンベースのストレージ・マーケットプレイスを構築し、柔軟なストレージ・ソリューションを提供している。一方、FilecoinとStorjはブロックチェーンベースのストレージ市場を構築し、柔軟なストレージ・ソリューションを提供している。Arweaveは「効率的なデータマイニング」を利用してマイナーにインセンティブを与え、Filecoinはプルーフ・オブ・レプリケーションとプルーフ・オブ・タイムを通じてデータストレージを保証する。Arweaveのストレージはハンズオンイージーであり、FilecoinとStorjはそれぞれプロフェッショナル市場と従来のクラウドストレージユーザーを対象としている。分散型ストレージの将来は、特にデータの分散化、検閲への耐性、AIの分野で有望だ。
分散型ストレージは、単一の中央制御ポイントに依存しないデータストレージへのアプローチです。このアプローチは、Amazon S3やGoogle Cloudのような従来のクラウドストレージサービスなど、一般的に単一の企業や組織によって管理される従来の集中型ストレージとは対照的です。
現在市販されている分散型ストレージの主流は、Arweave、Filecoin、Storjです。
分散型ストレージの主流は、Arweave、Filecoin、Storjです。li>
Arweave 長期的または永続的なデータ保存に重点を置いています。
Filecoin 従来のクラウドストレージに似た分散型マーケットプレイスを提供し、柔軟なストレージニーズをサポートします。
Storj セキュリティとプライバシー保護を提供する分散型クラウドストレージサービスに注力。
これら3つのプラットフォームはすべてブロックチェーン技術を使用していますが、アプリケーションのシナリオ、技術的な実装、支払いモデルが異なっており、それぞれ異なるタイプのストレージニーズに適しています:
目的:長期的かつ永続的なデータストレージソリューションを提供すること
技術: ブロックウィーブと呼ばれる独自のブロックチェーン技術を使用しています。従来のブロックチェーンとは異なり、ブロックウィーブは新しいブロックごとに以前のランダムブロックへの参照を含み、データの長期保存を促すように設計されています。
支払いモデル:ユーザーはデータ保存のために1回限りの料金を支払う。
目標: 伝統的なクラウドストレージサービスと同様の分散型ストレージ市場を作ることを目指しています。分散型ストレージ市場の創設を目指す。
技術: FilecoinはIPFS(インターネット・ファイル・システム)のインセンティブ・レイヤーです。ストレージの証明」と「時間の証明」を使って、データが正しく保存されていることを保証します。
支払いモデル:ユーザーは、保存されたデータの量と期間に基づいてストレージプロバイダーに支払います。これは、より伝統的なリースモデルであり、ユーザーは必要に応じてストレージを追加または削除し、それに応じて支払うことができます。
目的: セキュリティとプライバシー保護に重点を置いた、分散型のクラウドストレージソリューションをユーザーに提供する。セキュリティとプライバシー保護に重点を置いています。
技術: Storjはデータのセキュリティとプライバシーを保護するために、暗号化とシャーディング技術を使用しています。データは暗号化され、アップロードされる前にクライアント側で複数のチャンクに分割され、世界中のノードに分散して保存されます。
支払いモデル: Storjの支払いモデルは、従来のクラウドストレージと同様で、使用したストレージ容量と帯域幅に基づいて課金されます。
対照的に、Arweaveは、検閲に強く永続的なデータに重点を置き、永続的なストレージに重点を置いている点が特徴的です。FilecoinとStorjはどちらも、ブロックチェーン技術を使ってストレージ市場を再構築することに重点を置いたストレージ市場を採用しています。
アーウィーブの永久データストレージの根拠は、ムーアの法則に似ています。1980年から現在までのデータストレージのコストに関する統計によると、ストレージのコストは年間20%の割合で減少している。この統計法則に基づけば、データ・ストレージのコストは無限の年数を経ると一定に収束し、Arweaveの永久ストレージでは200年間のデータ保存コストを計算している。ユーザーはデータを保存する際に1回限りの料金を支払う。
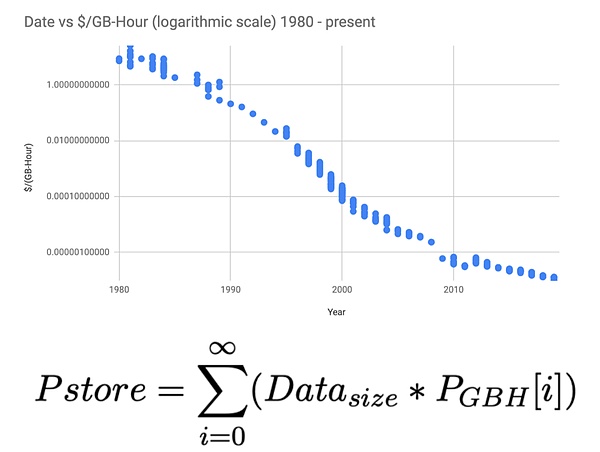
同時に、アーウィーブは非常にエレガントでシンプルなデータマイニングの仕組みを考案しました。私たちはこれを「効果的なデータマイニング」と名付けることができます。
有効なデータとは、過去にアーウィーブ・ネットワークに保存されたデータのことで、ユーザーは200年間の保存料を支払っている。ネットワーク内の別のアクターグループであるマイナーは、有効なデータでマイニングを行い、有効なデータを読み取るサービスを提供する者である。他のストレージ・ブロックチェーンとは異なり、Arweaveはマイナーにデータの保存を強制するのではなく、各マイナーが保存できる「有効データ」の量を最大化するインセンティブを生み出している。Arweaveネットワークでは、マイナーが保存する「有効データ」が多ければ多いほど、採掘できる「パワー」が増えます。
アーウィーブ・ネットワークに100TBの有効データがあると仮定すると、採掘者は100TBすべてのデータを保存する必要はありません。言い換えれば、採掘者は100MBのデータだけで採掘できるが、採掘者のパワーは非常に小さい。採掘者が100TBのデータをすべて保存することを選択した場合、採掘者の電力は最大になる。
「効率的なデータマイニング」メカニズムでは、Arweaveネットワークはマイナーにできるだけ多くのデータを保存するようインセンティブを与えますが、すべてのデータを保存するよう強制はしません。このインセンティブモデルでは、データ損失の可能性はあるのでしょうか?

1行目と2行目の0.5は、1つのノードがデータの50%を保存することを意味します。データを保存していることを意味します。ブロックネットワークに200,000のブロックがあり、ネットワークに200のノードがあり、各ノードがランダムに100,000のブロック(ブロックデータの50%)を保存すると仮定すると、1つのブロックがアクセスできない確率は確率論的に6.223^10-61と計算できます。 クラウドサービスによって提供されるデータの信頼性は、10の7乗である99.9999999%です。上記のArweaveアルゴリズムは、驚異的な61乗を与える。
FilcoinとStorjは、どちらもブロックチェーン技術を使ってデータストレージ市場を作っている。Storjの主な改善点はデータプライバシーだ。この記事では、ファイルコインの原則に焦点を当てます。
従来のオーダーブックと同様に、Filcoinを利用するには、ユーザーはまずマーケットプレイスに行き、保留中の注文に入札を行い、データ保存の時間とバックアップの数を指示する必要があり、採掘者は利益を得ることができる注文を受け取る。取引市場全体の公平性を確保するため、Filcoinは複雑な経済モデルを確立し、没収や少額の分割払いなどさまざまなルールを設定している。その中核技術は、複製証明と時間証明である。
Proof of Replication:採掘者は、データが専用の物理デバイスに保存されていることをユーザーに証明します。採掘者がユーザーのデータを保存する証明を行うたびに、ネットワークはその採掘者に報酬を支払います。
Spatial-Temporal Proofs:コピー証明だけではデータが常に保存されていることが保証されない場合、採掘者は証明提出時にデータのその部分のみを保存することができます。このため、Filecoin は時空間証明を追加しました。これは、採掘者がこのデータを継続的に保存できるように設計されています。
以上をまとめると、Arweaveの永久ストレージの根拠と、それを実装するためのソリューションは次のようになります:
永久ストレージのコストは年々減少しています
データ不滅のための「効率的なデータマイニング」によってマイナーにインセンティブを与える
FilcoinとStorjは以下の通りです。FilcoinとStorjはどちらもブロックテクノロジーを使って作られた分散型ストレージマーケットプレイスで、そのモデルは取引市場における伝統的なオーダーブックに似ており、注文を出す人が需要を提供し、採掘者がデータストレージのセキュリティのために注文を受け入れる。
Arweaveにデータを保存する方法は2つあります。1つ目は、データを直接Arweaveノードに送り、ARを支払う方法です。2つ目は、ANS-104(Bundled)データバインディングプロトコルを使って、データをArweaveに一括パックする方法です。
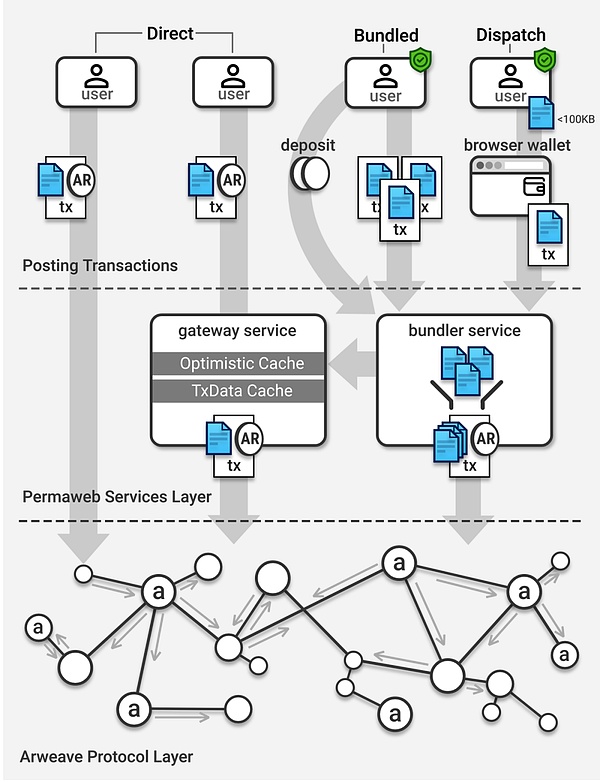
ユーザーは、アクションを完了するためにウォレットに保持ARを準備するだけです。以下のコードを使用して、名前付きfile.pdfをArweaveに保存します:

For more documentation references:
https://github.com/ArweaveTeam/arweave-js
を使用してArweaveにデータを保存します。Arweaveのブロックはブロックレートが低く、通常2分程度で、1ブロックは1000トランザクションしか扱えないため、Arweaveに保存できるトランザクション数が大幅に制限されます。Arweaveのトランザクションの保存量は無制限で、ユーザーは1つのトランザクションで最大100MB、あるいは10GBのデータをArweaveに直接保存できます。トランザクション数のスケールアップの問題を解決するために、ANS-104が開発されました。
ANS-104は、何万もの異なるデータ・エンティティを単一のArweaveトランザクションにバインドすることができるマルチ・トランザクション・バインディング技術です。EthereumからLayer2へのロールアップ・ソリューションと比較することができますが、ANS-104はデータのセキュリティを失わず、バインドされたデータは100%そのままArweaveに保存されるという違いがあります。
データストレージにANS-104を使用することを実証するコードは以下の通りです:

コードはarseeding lightノードを使用しています。データ・バインディング・サービスとして、arseeding light nodeは完全にオープンソースのArweaveデータノードで、すべてのArweaveネイティブ・ノード・インタフェースをサポートし、ANS-104インタフェースを拡張します。arseedingはまた、クロスチェーン決済プロトコルであるeverPayを統合しているため、ARを使用してストレージに支払うだけでなく、ユーザーや開発者はETH、BNB、USDT、USDCなどの様々なアセットをデータストレージに使用することができます。
現在、アーウィーブに1GBのデータを保存する場合、7.50ドルです。strong>
Arweaveには標準化されたGraphQLサービス・インターフェイスがあり、個人や組織でも標準に従ってArweaveインデックスを実装することができます。
ArweaveNet ゲートウェイは、最も完全なインデックスを持っています。
リンク:https://arweave.net/graphql
KNN3 gatewayは、Arseedingノードのデータをリアルタイムで高速に取得します。
Link: https://knn3-gateway.knn3⇄.xyz/ars⇄eeding/graphql
Arweaveのデータをダウンロードするには、データのARIDまたはItemIDを知る必要があります。コード例:

Arweaveのデータをダウンロードするには、データのARIDかItemIDを知るだけです。"xiumi.us">残念ながら、Filcoinは一般ユーザーや開発者向けのストレージツールを提供しておらず、一般開発者にとってはFilcoinは利用できない状態です。散発的な技術文書から、サードパーティのサービスプロバイダを通じていくつかのFilecoinストレージソリューションを見つけることができますが、サービスプロバイダの文書を注意深く見てみると、それらのほとんどはIPFSストレージを提供するだけであり、これらのサービスプロバイダは必ずしもFilcoinにデータを保存するとは限らず、おそらく筆者のレベルが限られているため、本当にFilcoinにデータを保存するためのより良い方法を見つけることができず、Filcoinに直接データを保存するための対応するインターフェイスはありません。また、ファイルコインから直接データを取得するインターフェースもありません。
StorjのストレージメソッドはWeb2と同じで、開発者は公式サイトに行って登録し、API-KEYを取得する必要があります。 StorjのストレージはAWS S3インターフェースと互換性がありますが、ここでは説明しません。StorjのストレージはAWSのS3インターフェイスと互換性があるので、ここでは触れない。 Storjのストレージのコストは安く、1GBのストレージのコストは月額わずか0.004ドルだが、200年間のストレージのコストは9.60ドルとArweaveのものより少し高い。
ストレージの実践は、Arweaveのトランザクション処理モデルがビットコイン/イーサリアムなどのブロックチェーンと一致していることを示している。ファイルコインは使えるSDKやインターフェースを提供しておらず、いわゆるストレージのリーダーが開発者に利用できないのは残念だ。StorjのストレージはWeb2と同じだ。
注目に値するのは、Arweaveはネイティブ・ブロックチェーン・ストレージであり、いったんデータがArweaveに送られると、削除や改ざんができないことです。FilcoinとStorjはリースなので、プロジェクトはいつでもストレージのリースをやめることができ、データはブロックチェーンの特性を持ちません。そのため、プロジェクトはいつでもストレージのリースを止めることができる。
ArweaveとFilcoinをより明確に区別するために、Arweave上のデータを「コンセンサスデータ」と名付けることができ、これはBTCとイーサリアムの両方に属します。ファイルコインのストレージレンタル市場に保管されているデータは、コンセンサスデータとは呼べない。
分散型ストレージには、まったく異なる2つのビジネスラインが出現しています。1つは、Arweaveに代表されるビジネスラインで、コンセンサス・データが中心で、データの分散化、検閲への耐性、トレーサビリティなどに重点が置かれています。Filecoinに代表されるビジネスラインは、分散型市場を中心としたもので、ストレージリソースの割り当てとストレージの成功を証明することに重点が置かれている。DeFiの開発と類似しており、初期のIDEXはブロックチェーン技術を使用してオーダーブック市場を作り出しました。オーダーブックは、ハングアップ&イートイットモデルでチケットの償還を解決するように設計された、非常に伝統的なビジネスモデルでした。DeFiの爆発的な増加は、Uniswap AMM取引モデルによってもたらされた流動性マイニング技術の結果であり、AMMは流動性のコンビナトリアルな性質を実現するために注文の完全自動操作を可能にし、最終的にDeFiの爆発的な増加をもたらしました。夏の爆発をもたらした。現在の分散型ストレージのトラックでは、ファイルコインはオーダーブック市場を作るのと同じブロックチェーン技術を表している。一方、ArweaveはAMMに似た統一モデルを使ってデータの需要と供給を管理している。Arweaveの統一モデルはデータの価格設定と処理に便利であり、Arweaveを使うことで通常のデータを「コンセンサス」データへの変換をより簡単に完了することができる。コンセンサスデータの上にあるデータは、「データの組み合わせ可能性」の爆発的な増加をもたらすかもしれない。
同時に、SCP理論(Storage-based Consensus Paradigm)にも触れなければならない。 SCPはオフチェーンコンピューティングを重視しており、データはBTC、イーサリアムなどのさまざまなチェーンに保存することができ、ブロックチェーン上のデータを集約することで固有の状態を形成することができる。これらの状態は、どの計算機で実行しても同じ結果が得られるのだから、なぜチェーン上で演算する必要があるのだろうか?多くの計算資源を浪費しているのでしょうか?
今話題のBRC20、Bitcoin Inscriptionはどちらもオフチェーン計算のコンセンサスを利用しています。BRC20プロトコルとArweave SCPが強調するストレージコンセンサスは同じで、どちらもデータ層としてブロックチェーンを通じて不変で追跡可能な取引データを提供し、状態の計算は完全にオフチェーンで行われます。Arweaveのストレージ機能により、SCP理論はより強固なコンセンサスデータセットにアクセスできるようになり、Arweave SCP理論はすでに完全なエンジニアリングを施したアプリケーションであるPermawebを開発している。Permawebはビットコインインデクサーの究極版であり、アセットだけでなく、テキスト、画像、動画までも扱うことができる。Permawebは資産だけでなく、テキスト、画像、そして動画さえも扱うことができる。近い将来、メディアをストリーミングできる超強力なインデクサが登場し、完全に分散化されたJitterbugが誕生することを想像してみてほしい。
Permawebソリューションは、ウェブホスティングからコンテンツ共創、ゲームなど、アーキテクチャを使って簡単に開発できる幅広いアプリケーションをサポートしています。例えば、ある作家がコンテンツ共創を通じてテキストと著作権をArweaveにアップロードした場合、ゲームの開発者は作家のコンテンツを直接参照し、プレイヤーが著作権料を作家に支払うことができます。
現在、DePINにとって最大のジレンマは、ブロックチェーンの性能です。 DePINデバイスは何百万もの家庭に普及する予定ですが、これほど膨大な量のユーザーとのやり取りを担えるブロックチェーンはありません。ほとんどのDePINはいまだにデータ処理に中央集権的なアプローチを使っており、これではDePINの分散的な性質を奪うことになる。コンセンサス・データは、DePINにより強力なエンパワーメントをもたらすことができる。例えば、グリーンエネルギー証書は、ブロックチェーンのPoW運用中のエネルギー消費を相殺したり、コンテンツ作成のロゴになったり、ゲームのバッジになったりする。データと価値はあらゆるところに流れる。
コンセンサス・データはAI人工知能の分野にも当てはまる。人間の知識や歴史は永遠に生き続けるべきであり、コンセンサスデータはAIが人間の知識や歴史を汚染したり改ざんしたりできないことを保証することができる。同様に、コンセンサスデータはAIにとって最良のデータソースとなり、AIが有効な情報を学習し、処理することを可能にする。
最高の分散型クラウド・コンピューティング・プラットフォームは?新しいプロジェクトは、ユーザーに新しい体験をもたらすかもしれない。
JinseFinanceあなたが今日、家族旅行の写真アルバムをネットワーク・ストレージにアップロードしたとしよう。
JinseFinanceこの旧正月、アーウィーヴ・エコに大きな出来事が起こりました。
JinseFinanceファイルコイン財団とロッキード・マーチン、ダボス会議で宇宙通信のマイルストーンを達成。分散型システムが遅延や放射線の課題を克服、IPFSが安全な宇宙データ伝送の効率性と検証可能性を確保。
 Huang Bo
Huang BoAIデピンの台頭により、我々は分散型ストレージの将来について明るい見通しを維持している。
JinseFinanceティーンCEOのアルバロ・ピンタド・サンタウラリアが、データストレージの現状を破壊することを目指し、「hello.app」ドメインを115,000ドルで取得。この新しいプラットフォームは、モバイル、iPad、PCと互換性のある世界初の分散型ストレージ・ネットワークとなることを約束する。
 YouQuan
YouQuan従来のストレージは中央集権的な企業のようなもので、ブロックチェーンを利用した分散型ストレージは、安全な個人のロックボックスのようなもので、個人の安全が確保される。
 CoinBold
CoinBoldブロックチェーンは、コミットメントを行うことができるコンピューターです。 [https://cdixon.org/2020/01/26/computers-that-can-make-commitments](https://cdixon.org/2020/01/26/computers-that-can-make-commitments) このプロパティのパフォーマンス オーバーヘッドが発生します。
 Cdixon
Cdixon分散ストレージは Web3 にとって不可欠なインフラストラクチャです。しかし現段階では、ストレージの規模にしてもパフォーマンスにしても、分散型ストレージはまだ初期段階にあり、集中型ストレージからは程遠いです。この記事では、いくつかの代表的なストレージ プロジェクト (Storj、Filecoin、Arweave、Stratos Network、Ceramic) を選択し、それらのパフォーマンス、コスト、市場での位置付け、市場価値などの情報を要約および比較し、技術原則を分析し、エコロジーの進歩を要約します。
 链向资讯
链向资讯分散型ストレージ プロバイダーは Web3 のバックボーンであることが証明されていますが、これは集中型 Web サービス プロバイダーにとって何を意味するのでしょうか?
 Cointelegraph
Cointelegraph