エヌビディアの市場価値がアップルを上回る前に書かれた、黄健薰の1兆ドルAI帝国のパノラマ。
今週月曜日、エヌビディアの株価は再び史上最高値を更新し、時価総額は3兆5000億ドルを超え、世界ナンバーワンのアップルと肩を並べた。
 JinseFinance
JinseFinance

出典: Tencent Technology
NVIDIA 共同創立者兼 CEO の Jen-Hsun Huang 氏は、Computex 2024 (台北国際コンピュータ見本市) で基調講演を行い、人工知能の時代が新たなグローバル産業革命をどのように促進しているかについて語りました。
スピーチのハイライトは以下の通りです:
1)Jen-Hsun Huangは、最新の量産版Blackwellチップのデモを行い、2025年にBlackwell Ultra AIチップを発表し、次世代AIプラットフォームはRubinと名付けられ、Rubin Ultraは2027年にプッシュされると述べました。アップデートのペースはムーアの法則を破る「年1回」になるという。
② Jen-Hsun Huang氏は、NVIDIAが2012年以降にGPUアーキテクチャを変更し、すべての新技術を1台のコンピュータに統合したビッグ言語モデルの誕生を推進したと主張した。
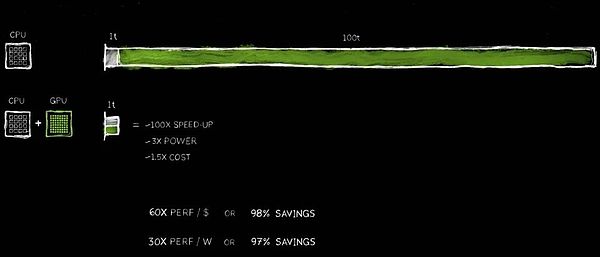
3& NVIDIAの加速コンピューティング技術は、100倍の速度向上を達成するのに役立ち、消費電力は元のわずか3倍に増加し、コストは1.5倍になりました。
④ Jen-Hsun Huang氏は、次世代のAIは物理世界を理解する必要があると予測しています。これを実現する方法として、彼はAIにビデオや合成データを通じて学習させること、そしてAI同士に学習させることを挙げている。
5 Jen-Hsun Huangは、彼のPPTの中で、トークン(語彙要素)の中国語訳まで完成させました。
6 Jen-Hsun Huangは、ロボット工学の時代が到来し、将来的にはすべての動く物体が自律的に動作するようになると述べています。

Tencent Technologyがまとめた2時間のスピーチの全記録は以下の通りです:
ご列席の皆様、この場に再び立つことができて大変光栄です。この場に再び立つことができ、大変光栄に思います。まずは、この体育館を会場として提供してくださった国立台湾大学に感謝いたします。前回ここに来たのは、私が国立台湾大学で学位を取得したときでした。今日は、これから探求していくことがたくさんあるので、ペースを上げて、情報を素早くわかりやすく伝えていかなければなりません。話したいことはたくさんあるし、エキサイティングな話もたくさんある。
多くのパートナーがいる中国の台湾に来られて、とても興奮しています。実際、台湾はNVIDIAの歩みに不可欠な部分であるだけでなく、私たちがパートナーと協力して世界にイノベーションをもたらす重要なポイントでもあります。多くのパートナーとともに、私たちは世界規模でAIインフラを構築しています。
1)私たちの共同作業ではどのような進展があり、その意義は何でしょうか?
2)ジェネレーティブAIとは一体何なのか?私たちの業界、いや、あらゆる業界にどのような影響を与えるのでしょうか?
3)私たちがどのように前進し、この素晴らしい機会をどのようにつかむかについての青写真は?
次に何が起こるのか?ジェネレーティブAIとそれがもたらす遠大な影響、私たちの戦略的青写真、これらはすべて私たちがこれから探求するエキサイティングなトピックです。私たちは、コンピューター業界の再始動の始まりに立っています。皆さんによって鍛えられ、創造された新しい時代が始まろうとしているのです。さあ、次の大きな旅への準備は整いました。
しかし、その議論に飛び込む前に、1つ強調しておきたいことがあります。NVIDIAは、コンピュータグラフィックス、シミュレーション、人工知能の交差点に位置しており、これらは当社の魂を形成しています。今日お見せするものはすべてシミュレーションに基づいています。これらは単なるビジュアルではなく、最高の数学、科学、コンピューターサイエンス、そして息をのむようなコンピューターアーキテクチャーに裏打ちされています。どのアニメーションも事前に制作されたものではなく、すべてが私たち自身のチームの作品です。それがNVIDIAの評価であり、私たちが誇りに思うOmniverseの仮想世界にそのすべてを組み込んでいます。とりあえず、ビデオをお楽しみください!
世界中のデータセンターにおける電力消費は、コンピューティングのコストとともに急増しています。私たちは、長期的には明らかに持続不可能な、コンピュート肥大化という困難な課題に直面しています。データは指数関数的に増え続ける一方で、CPUの性能はかつてほどのスピードで拡張することは難しい。しかし、より効率的なアプローチが浮上しています。
私たちは20年近く、CUDAテクノロジーによってCPUを補強し、特別なプロセッサーがより効率的に実行できるタスクをオフロードして加速する、アクセラレーテッド・コンピューティングに取り組んできました。実際、CPUの性能スケーリングが鈍化、あるいは停滞するにつれ、アクセラレーテッド・コンピューティングのメリットはますます大きくなっている。私は、すべての処理集約型アプリケーションがアクセラレーションされ、近い将来、すべてのデータセンターが完全にアクセラレーションされると予測しています。

加速コンピューティングが賢い選択であることは、今や業界のコンセンサスです。100単位で完了するアプリケーションを想像してみてください。それが100秒であろうと100時間であろうと、AIアプリケーションを何日も、あるいは何ヶ月も実行する余裕はないことがよくあります。
この100単位の時間の1つには、シングルスレッドCPUが不可欠な、逐次実行が必要なコードが含まれます。オペレーティングシステムの制御ロジックは不可欠であり、命令のシーケンスに厳密にしたがって実行されなければなりません。しかし、コンピュータグラフィックス、画像処理、物理シミュレーション、組合せ最適化、グラフ処理、データベース処理、特にディープラーニングで多用される線形代数など、並列処理による高速化に適したアルゴリズムは数多く存在する。これを実現するために、私たちはGPUとCPUをシームレスに組み合わせた革新的なアーキテクチャを考案しました。
専用プロセッサーは、そうでなければ時間のかかるタスクを驚くほど高速化することができる。2つのプロセッサーは並列に動作するため、独立しており、自律的です。つまり、100単位で完了するタスクを、わずか1単位で完了させることができるのです。この加速は信じられないように聞こえるかもしれないが、今日は一連の例でこの主張を検証してみよう。

このパフォーマンス向上のメリットは驚異的で、わずか約3倍の電力増加で100倍の加速を実現し、コストは約50%しか増加しません。PC業界では、長い間この戦略を実践してきました。PCに500ドルのGeForce GPUを追加することで、全体的な価値を1,000ドルに高めながら、性能を大幅に向上させることができます。データセンターにおいても、私たちは同じアプローチを使っている。10億ドル規模のデータセンターが、5億ドル相当のGPUを追加することで、瞬時に強力なAI工場に生まれ変わる。今日、この変革は世界規模で起こっています。
コスト削減も同様に驚異的です。1ドル投資するごとに、最大60倍の性能向上が得られます。わずか3倍の消費電力と1.5倍のコスト上昇で、100倍まで加速させることができます。この節約は本物です!
多くの企業がクラウドでのデータ処理に何億ドルも費やしていることは明らかです。データが加速度的に処理されれば、数億ドルの節約は合理的になります。それはなぜか?単純な理由として、私たちは汎用コンピューティングにおいて効率のボトルネックを長い間経験してきたからです。
今、私たちはようやくこのことを認識し、加速することに決めました。専用プロセッサを採用することで、これまで見過ごされていた膨大な量の性能向上を取り戻すことができ、その結果、多くの費用とエネルギーを節約することができます。だから私は、買えば買うほど節約になると言っているのです。
さて、数字をお見せしました。小数点以下の桁数は違いますが、事実を正確に表しています。これは「CEOの数学」と呼ばれるもので、CEOの数学は極端な正確さを追求するものではありませんが、その背後にある論理は健全なものです。
2. 新しい市場を開拓するのに役立つ350の関数ライブラリ
高速化されたコンピューティングは本当に並外れた結果をもたらしますが、それを達成するプロセスは簡単ではありません。なぜ、これほど多くの費用を節約できるのに、人々はすぐにテクノロジーを採用しないのでしょうか?その理由は、導入が非常に難しいからである。
単に高速化コンパイラを通すだけで、アプリケーションが瞬時に100倍速くなるような既製のソフトウェアは存在しない。それは論理的でも現実的でもありません。そんなに簡単なら、CPUメーカーがすでにやっているはずです。
実際、高速化を実現するには、ソフトウェアを完全に書き換える必要がある。これが最も難しい部分です。ソフトウェアを再設計し、再コード化することで、CPU上で実行されるアルゴリズムを、アクセラレータ上で並列実行できる形式に変換する必要があります。
このコンピューターサイエンスの研究は難しいですが、私たちは過去20年間で大きな進歩を遂げました。例えば、ニューラルネットワークのアクセラレーションに特化した、人気の高いcuDNNディープラーニングライブラリを導入しました。また、流体力学のような物理法則の遵守が必要なアプリケーション向けに、AI物理シミュレーション用のライブラリも提供しています。さらに、CUDAを使用して5G無線技術を高速化するAerialという新しいライブラリもあり、ソフトウェアがインターネット・ネットワークを定義するのと同じように、ソフトウェアで通信ネットワークを定義し、高速化することができます。

これらのアクセラレーション機能は、パフォーマンスを向上させるだけでなく、通信業界全体をクラウドに似たコンピューティング・プラットフォームに変えるのに役立ちます。さらに、Coolithoのコンピュテーショナル・リソグラフィ・プラットフォームは、チップ製造プロセスの中で最も計算量の多い部分であるマスク作成の効率を劇的に改善するプラットフォームの好例です。TSMCのような企業はすでにCoolithoを製造に使用し始めており、大幅なエネルギー削減を達成するだけでなく、コストを劇的に削減しています。彼らの目標は、テクノロジー・スタックを加速させることで、より深く狭いトランジスタを作るために必要なアルゴリズムと膨大な計算能力のさらなる開発に備えることです。
Pair of Bricksは遺伝子シーケンスライブラリーで、遺伝子シーケンスのスループットでは世界トップクラスであると自負しています。一方、Co OPTは、ルート計画、旅程の最適化、旅行代理店問題などの複雑なパズルを解くことができる、魅力的な組み合わせ最適化ライブラリです。これらの問題を解くには量子コンピューターが必要だと広く信じられていますが、私たちは加速コンピューティング技術を使って極めて高速に動作するアルゴリズムを作成することで、23の世界記録を塗り替えることに成功し、現在でもすべての主要な世界記録を保持しています。
Coup Quantumは、我々が開発した量子コンピューターシミュレーションシステムです。量子コンピューターや量子アルゴリズムを設計したい研究者にとって、信頼できるシミュレーターは不可欠です。実際の量子コンピューターがない場合、私たちが世界最速のコンピューターと呼んでいるNVIDIA CUDAが、彼らの選択ツールとなります。私たちは、量子コンピュータの動作をエミュレートできるシミュレータを提供し、研究者が量子コンピュータで飛躍的な進歩を遂げるのを支援しています。このシミュレータは、世界中の何十万人もの研究者に広く利用されており、すべての主要な量子コンピューティングフレームワークに統合され、世界中の科学スーパーコンピュータセンターに強力なサポートを提供しています。
さらに、データ処理プロセスを高速化するために特別に設計されたデータ処理ライブラリであるKudieffを発表しました。QDFは、Spark、Pandas、Polar、NetworkXのようなグラフ処理データベースなど、世界をリードするデータ処理ライブラリのパフォーマンスを劇的に向上させるために開発した高速化ツールです。
これらのライブラリは、アクセラレーテッド・コンピューティングを広く利用できるようにするエコシステムの重要な構成要素です。cuDNNのような慎重に作られたドメイン固有のライブラリがなければ、CUDAとTensorFlow、PyTorchなどのディープラーニングフレームワークで使用されるアルゴリズムとの間に大きな違いがあるため、世界中のディープラーニングの科学者はCUDAの可能性だけを十分に活用できないかもしれません。OpenGLなしでコンピューターグラフィックスを設計したり、SQLなしでデータを処理したりするのと同じくらい非現実的でしょう。
このようなドメイン固有のライブラリは当社の宝であり、現在350以上のライブラリを保有しています。これらのライブラリがあるからこそ、私たちはオープンで、市場の最先端を走り続けることができるのです。今日は、もっとエキサイティングな例をお見せしましょう。
つい先週、GoogleはQDFをクラウドに導入し、Pandasの高速化に成功したと発表しました。Pandasは世界で最も人気のあるデータサイエンスライブラリで、世界中の1,000万人のデータサイエンティストに利用され、毎月1億7,000万回ダウンロードされています。データサイエンティストにとってのExcelのようなもので、データを扱うための右腕なのです。
今、GoogleのクラウドベースのデータセンタープラットフォームであるColabをワンクリックするだけで、QDFによって加速されたPandasのパワーを体験することができます。このアクセラレーションは本当に素晴らしく、先ほどのデモのように、データ処理タスクをほぼ瞬時に完了します。
CUDAは転換点と呼ばれるものに達しましたが、現実はそれ以上です。歴史を振り返り、さまざまなコンピューティング アーキテクチャとプラットフォームの発展を見ると、このようなサイクルは一般的ではないことがわかります。たとえば、マイクロプロセッサCPUは60年前から存在していますが、その長い間、計算を加速する方法は根本的に変わっていません。
新しいコンピューティングプラットフォームを作ることは、しばしば鶏と卵のジレンマです。開発者のサポートがなければユーザーを引き付けることは難しく、広く普及しなければ開発者を引き付けるための大規模なインストールベースを構築することは難しい。このジレンマは、過去20年にわたって複数のコンピューティング・プラットフォームの開発を悩ませてきました。
しかし、私たちは一貫してドメインに特化し、高速化されたライブラリを発表することで、このジレンマから抜け出すことに成功しました。現在、世界中で500万人の開発者がCUDAテクノロジーを使用しており、ヘルスケアや金融サービスからコンピュータ産業や自動車産業まで、事実上すべての主要な産業および科学分野に貢献しています。
当社の顧客基盤が拡大し続けるにつれて、OEMやクラウドサービスプロバイダーも当社のシステムに関心を持ち始め、さらに多くのシステムを市場に投入しています。この好循環は、当社が規模を拡大し、研究開発投資を増やして、より多くのアプリケーションの高速化を推進するための大きなチャンスを生み出します。
すべてのアプリケーションの高速化は、コンピューティング・コストの大幅な削減を意味します。以前にもお見せしたように、100倍のアクセラレーションは、最大97.96%、ほぼ98%のコスト削減を実現します。コンピュート・アクセラレーションを100倍から200倍、そして1,000倍へと引き上げるにつれて、コンピュートの限界コストは下がり続け、説得力のある経済性を示しています。
もちろん、コンピューティングのコストを劇的に削減することで、市場、開発者、科学者、発明家は、より多くのコンピューティングリソースを消費する新しいアルゴリズムを発見し続けると信じています。ある時点まで、深い変革が静かに起こるだろう。コンピューティングの限界コストが非常に低くなったとき、まったく新しいコンピュータの使用方法が出現するでしょう。
実際、この変化は目の前で起こっている。過去10年間で、私たちは特定のアルゴリズムを使って、コンピューティングの限界コストを驚異的な100万分の1に削減しました。今日、大きな言語モデルを訓練するためにインターネット上のすべてのデータを使用することは、論理的で自然な選択であり、もはや疑問の余地はありません。
膨大な量のデータを処理できるコンピュータを構築し、それ自体をプログラミングするというこのアイデアは、まさにAIの台頭の礎となっている。AIの台頭が可能になったのは、コンピューティングをどんどん安くすれば、必ず誰かがその巨大な用途を見つけるという確信があったからにほかなりません。今日、CUDAの成功は、この好循環の実行可能性を証明しています。
インストールベースが拡大し続け、コンピューティングのコストが下がり続けるにつれて、より多くの開発者が創造的な可能性を実現し、より多くのアイデアやソリューションを考え出すことができるようになりました。この革新的なパワーが、市場の需要を急増させている。私たちは今、大きな転換点に立っている。しかし、これ以上先に進む前に、CUDAと最新のAI技術、特にジェネレーティブAIのブレークスルーがなければ、これから紹介することは不可能であったことを強調しておきたい。
これはEarth-2プロジェクトで、地球のデジタルツインを作るという野心的なビジョンです。将来の変化を予測するために、地球全体の動作をシミュレートします。このようなシミュレーションを通じて、災害をよりよく予防し、気候変動の影響をより深く理解することで、私たちはこれらの変化によりよく適応し、さらには今すぐ私たちの行動や習慣を変え始めることができるのです。
Earth-2プロジェクトは、おそらく世界で最も挑戦的で野心的なプロジェクトの1つです。私たちは毎年この分野で大きな進歩を遂げていますが、今年の成果は特に素晴らしいものでした。このエキサイティングな進展の一部をお見せしましょう。
そう遠くない将来、私たちは地球上のすべての平方キロメートルをカバーする継続的な気象予報能力を持つようになるでしょう。気候がどのように変化するかを常に知ることができ、人工知能を訓練することでこの予測は常に実行される。これは信じられないような偉業になるでしょう。そしてさらに重要なのは、この予測は私ではなくジェンセンのAIが行ったということです。私が設計しましたが、最終的な予想はジェンセンAIが発表したものです。
継続的にパフォーマンスを向上させ、コストを下げるという当社のコミットメントのおかげで、研究者たちは2012年にCUDAを発見し、それがNVIDIAのAIとの最初の関わりとなりました。ディープラーニングを可能にするために科学者と緊密に協力するという賢明な選択をし、AlexNetの登場によってコンピュータビジョンにおける大きなブレークスルーが可能になったからです。
しかし、より重要な知恵は、私たちが一歩引いて、ディープラーニングの本質を深く理解したことにあります。その基礎は何か?その長期的な意味は何か?その可能性は何か?私たちは、この技術が数十年前に発明・発見されたアルゴリズムを拡張し続ける巨大な可能性を秘めていること、そして、より多くのデータ、より大きなネットワーク、重要な計算リソースと組み合わさることで、ディープラーニングは人間のアルゴリズムが到達できなかったタスクを突然達成できるようになることに気づきました。
今、このアーキテクチャをさらに拡大し、より大きなネットワーク、より多くのデータ、計算資源を導入したらどうなるか、想像してみてください。
だからこそ、私たちはすべてを再発明することに全力を注いでいるのです。2012年以来、私たちはGPUのアーキテクチャを変更し、テンソルコアを追加し、NV-Linkを発明し、cuDNN、TensorRT、Nickelを導入し、メラノックスを買収してTriton Inference Serverを立ち上げました。
これらのテクノロジーは、当時誰もが想像していたものを凌駕する、まったく新しいコンピューターに統合されました。誰もそれを期待せず、誰もそれを要求せず、誰もその可能性を完全に理解してさえいませんでした。実際、私自身も誰も買いたくなかっただろう。
しかしGTCカンファレンスで、私たちはこの技術を正式に発表した。サンフランシスコのOpenAIというスタートアップは、すぐに私たちの成果に注目し、ユニットを要求してきました。
2016年、私たちは研究開発の規模を拡大し続けました。単一のAIアプリケーションを搭載した1台のAIスーパーコンピューターから、2017年にはさらに大規模で強力なスーパーコンピューターを発表するまでに拡大しました。技術の進歩が進むにつれ、世界はトランスフォーマーの台頭を目の当たりにしました。このモデルの出現により、大量のデータを処理し、長い時間スパンで連続するパターンを認識・学習できるようになった。
今日、私たちは自然言語理解における大きなブレークスルーを達成するために、これらの大きな言語モデルを訓練する能力を持っている。しかし、我々はそこで止まらず、さらに大きなモデルを構築しました。2022年11月までに、非常に強力なAIスーパーコンピューター上で、何万ものNVIDIA GPUをトレーニングに使用しています。
そのわずか5日後、オープンAIはChatGPTのユーザー数が100万人に達したと発表した。この驚異的な成長率は、わずか2ヶ月で1億ユーザーまで上昇し、アプリ史上最速の成長記録を打ち立てました。その理由はとてもシンプルで、ChatGPTの体験が簡単で魔法のようだからです。
ユーザーは、まるで本物の人間とコミュニケーションしているかのように、自然で流れるような方法でコンピューターと対話することができます。ChatGPTは、面倒な指示や明確な説明を必要とすることなく、ユーザーの意図やニーズを理解します。
ChatGPTの登場は画期的な変化をもたらしましたが、このスライドはまさにその重要なひねりを捉えたものです。お見せしましょう。
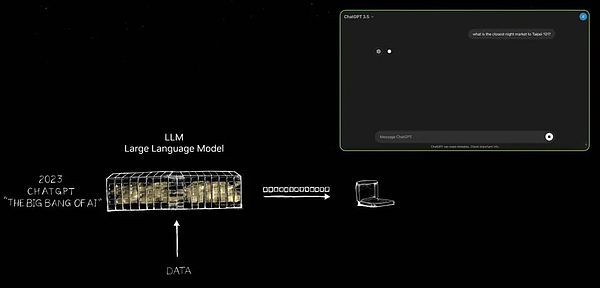
ChatGPT が登場するまで、生成AIの無限の可能性が真に世界に明らかになることはありませんでした。長い間、AIの焦点は、自然言語理解、コンピュータビジョン、音声認識など、人間の知覚能力を模倣することに特化した技術である知覚領域が中心でした。しかしChatGPTは、知覚を超え、初めて生成的AIの力を実証することで、質的な飛躍を遂げました。
それはトークンによってトークンを生成します。トークンは、単語、画像、グラフ、表、あるいは歌、テキスト、音声、動画であってもかまいません。トークンは、化学物質であれ、タンパク質であれ、遺伝子であれ、あるいは先ほど述べたように天候パターンであれ、明確な意味を持つものであれば何でも表すことができます。
このような生成AIの台頭は、物理現象を学習し、シミュレートできることを意味し、AIモデルが物理世界から現象を理解し、生成することを可能にします。私たちはもはやフィルタリングのための絞り込みに限定されず、生成的な手段によって無限の可能性を探求しているのです。
今日、私たちは、自動車のハンドル操作であろうと、ロボットアームの関節の動きであろうと、現在学習可能なものであろうと、ほとんどすべての価値あるものに対してトークンを生成することができます。その結果、私たちはもはや単なるAIの時代ではなく、ジェネレーティブAIが主導する新しい時代に生きている。
しかも、スーパーコンピューターとして登場したこの装置は、効率的に機能するAIデータセンターへと進化している。トークンを生成するだけでなく、価値を創造するAI工場も常に生産している。このAI工場は、巨大な市場ポテンシャルを持つ新しい商品を生み出し、創造し、生産している。
ニコラ・テスラが19世紀末にオルタネーターを発明し、私たちに電子の絶え間ない流れをもたらしたように、エヌビディアのAIジェネレーターは、無限の可能性を秘めたトークンを絶え間なく生成している。これはまさに新たな産業革命である!
私たちは今、あらゆる産業にとって前例のない価値を持つ新商品を生産できる、まったく新しい工場の到来を告げているのです。このアプローチは非常にスケーラブルであるだけでなく、完全に再現可能である。多種多様なAIモデル、特にジェネレーティブAIモデルが、今や日常的に出現していることに注目してほしい。今日、あらゆる業界がこの動きに乗ろうと競い合っているが、これは前例のないことだ。
3兆ドルのIT産業は、100兆ドルの産業に直接役立つイノベーションを生み出そうとしている。ITはもはや単なる情報ストレージやデータ処理のツールではなく、あらゆる産業においてインテリジェンスを生み出すエンジンとなる。これは新しいタイプの製造業になるだろうが、従来のコンピューター製造業ではなく、コンピューターを使ったまったく新しい製造業モデルである。このような変化はこれまで起こったことがなく、まさに驚くべき驚くべきことなのです。
これにより、コンピュートアクセラレーションの新時代が到来し、AIの急成長に拍車がかかり、ジェネレーティブAIの台頭が生まれました。そして今日、私たちは産業革命の真っ只中にいる。その意味についてもう少し深く掘り下げてみよう。
我々の業界にとっても、この変化の意味は同様に深い。以前にも申し上げたように、過去60年間で初めて、コンピューティングのあらゆるレイヤーが変革されつつあります。CPUによる汎用コンピューティングからGPUによるアクセラレーション・コンピューティングまで、あらゆる変化がテクノロジーの飛躍を意味します。
かつてのコンピューターは命令に従って演算を行う必要がありましたが、現在ではLLM(大規模言語モデル)やAIモデルを扱うことが多くなっています。
かつてのコンピューティング・モデルは主に検索に基づいており、携帯電話を使用するたびに、あらかじめ保存されたテキストや画像、動画を検索し、推薦システムに基づいてそれらを組み合わせて表示していました。
しかし将来的には、コンピュータはできるだけ多くのコンテンツを生成し、必要な情報のみを取得するようになるでしょう。そして、生成されたデータはより文脈に関連し、あなたのニーズをより正確に反映します。答えが必要なとき、コンピュータに「あの情報をくれ」「あのファイルをくれ」と明示的に指示する必要はなくなり、単に「答えをくれ」と言うだけでよいのです。
さらに、コンピューターはもはや単なる道具ではなく、スキルを生み出し始めている。タスクを実行し、もはやソフトウェアを生産する産業ではなくなっている。覚えているだろうか?マイクロソフトはパッケージ・ソフトウェアというアイデアでPC業界に革命を起こした。パッケージ・ソフトウェアがなければ、私たちのPCはほとんどの機能を失っていただろう。この革新は業界全体を前進させた。
今、私たちは新しい工場、新しいコンピュータを手に入れ、その上で新しい種類のソフトウェア--私たちはそれをNim(NVIDIA Inference Microservices)と呼んでいる--を動かしている。この新しい工場で稼働しているNimは、AIである事前に訓練されたモデルです。

AI自体は非常に複雑ですが、AIを実行する計算スタックはさらに信じられないほど複雑です。ChatGPTのようなモデルを使う場合、その背後には巨大なソフトウェアスタックがあります。このスタックが複雑で大規模なのは、モデルには数十億から数兆のパラメーターがあり、1台のコンピューター上だけでなく、複数のコンピューターが連携して動作しているからです。
効率を最大化するために、システムはテンソル並列処理、パイプライン並列処理、データ並列処理、エキスパート並列処理など、さまざまな並列処理を行う複数のGPUにワークロードを割り当てる必要があります。工場では、スループットが収益、サービスの質、サービスを提供できる顧客数に直結するため、このような割り振りは、作業が可能な限り迅速に行われるようにするためです。今日、私たちはデータセンターのスループット利用が重要な時代に入っています。
以前は、スループットは重要視されていましたが、決定的な要因ではありませんでした。しかし現在では、データセンターが真の「工場」となったため、稼働時間、稼働率、スループットからアイドル時間まで、あらゆるパラメーターが正確に測定されるようになっています。この工場では、運用効率が企業の財務業績に直結している。
このような複雑性を考えると、AIを導入する際にほとんどの企業が直面する課題を理解しています。そこで私たちは、導入と管理が容易なボックスにAIをカプセル化した、統合AIコンテナ・ソリューションを開発しました。このボックスには、CUDA、CUDACNN、TensorRT、Triton推論サービスなどの膨大なソフトウェアが含まれています。クラウドネイティブ環境をサポートし、Kubernetes(コンテナ技術に基づく分散アーキテクチャ・ソリューション)環境での自動スケーリングを可能にし、AIサービスの運用状況を簡単に監視できるマネージド・サービスを提供する。
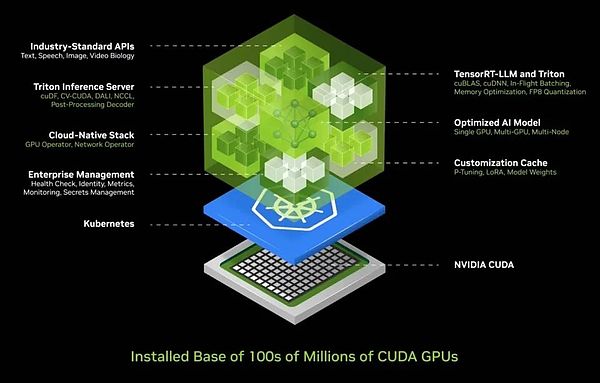
さらにエキサイティングなのは、このAIコンテナが共通の標準APIインタフェースを提供し、ユーザーが直接 "箱"と対話することができる。ユーザーは、NimをダウンロードしてCUDA対応コンピューター上で実行するだけで、AIサービスを簡単に展開・管理できる。今日、CUDAはユビキタスであり、主要なクラウドサービスプロバイダーがサポートし、事実上すべてのコンピューターメーカーがCUDAをサポートし、さらに何億台ものPCに搭載されています。
Nimをダウンロードすれば、ChatGPTとの会話のようにスムーズにコミュニケーションできるAIアシスタントを即座に手に入れることができる。現在、すべてのソフトウェアは合理化され、単一のコンテナに統合されており、以前は面倒だった400の依存関係はすべて一元管理され最適化されています。Pascal、Ampere、さらには最新のHopperなど、GPUの異なるバージョンを含むクラウドインフラで、すべての事前学習済みモデルを徹底的にテストし、Nimを厳密にテストしました。
ニムの発明は間違いなく偉業であり、私の最も誇れる業績のひとつです。今日、私たちは、言語、視覚、画像などの幅広い領域をカバーする、大きな言語モデルやさまざまな事前学習済みモデルを構築する能力を持っており、ヘルスケアやデジタル生物学などの特定の業界向けにカスタマイズされたバージョンもあります。

ai.nvidia.comにアクセスするだけで、これらのリリースの詳細を確認したり、試したりすることができます。本日、私たちはHugging Face上で完全に最適化されたLlama 3をリリースします!ニムで、すぐに体験することも、無料で持ち帰ることもできます。どのクラウドプラットフォームを選んでも、簡単に実行できます。もちろん、このコンテナをあなたのデータセンターにダウンロードし、セルフホストして顧客に提供することもできます。
先ほど、物理学、意味検索、視覚言語など、さまざまな領域をカバーするバージョンのNimを複数の言語で提供していると述べました。これらのマイクロサービスは、大規模なアプリケーションに簡単に統合することができ、最も有望なアプリケーションの1つは、顧客サービスエージェントです。これはほとんどすべての業界で標準となっており、何兆ドルもの価値がある世界的なカスタマーサービス市場を代表するものです。
小売、ファーストフード、金融サービス、保険などの業界で、看護師が顧客サービスの中核として重要な役割を果たしていることは注目に値する。今日、何千万人ものカスタマーサービス担当者が、言語モデリングと人工知能技術によって大幅に強化されています。
推論エージェント(Reasoning Agent)と呼ばれるものもあり、タスクを与えられると、目標を明確にして計画を立てることができる。情報を検索するのが得意な者もいれば、検索に長けている者もいる。また、Coopのようなツールを使ったり、ABAPのようなSAP上で動作する特定の言語を学ぶ必要があったり、SQLクエリを実行したりする者もいる。これらのいわゆるスペシャリストは、現在では高度に協力的なチームにグループ化されている。
その結果、アプリケーションレイヤーは変貌を遂げた。かつてはアプリケーションは指示書によって書かれていたが、今ではAIチームを編成することによって構築される。プログラムを書くには専門的なスキルが必要ですが、問題を分解してチームを組み立てる方法は、ほとんどの人が知っています。その結果、将来はどの企業もニムを大量に抱えるようになると私は確信している。必要に応じて専門家を選び、チームにつなげることができる。
さらに驚くべきことに、彼らをどのようにつなげるかを考える必要さえない。タスクをエージェントに割り当てるだけで、ニムはタスクをどのように分解し、最も適切な専門家に割り当てるかをインテリジェントに判断します。エージェントは、アプリケーションやチームの中心的なリーダーとして、チームメンバーの作業を調整し、最終的に結果をあなたに提示することができる。
プロセス全体は、人間のチームワークのように効率的で柔軟です。これは単なる未来のトレンドではなく、私たちの身の回りで現実になろうとしている。これがアプリの未来の姿なのです。
大規模なAIサービスとの対話について言えば、今のところ、私たちはすでにテキストや音声プロンプトでそれを行うことができます。しかし、将来を見据えると、私たちはより人間的な方法、つまりデジタルな人間との対話を好みます。NVIDIAはすでにデジタルヒューマン技術の分野で大きな進歩を遂げている。

デジタルピープルは、優れた対話エージェントになる可能性があるだけでなく、より魅力的で、より大きな共感を示す可能性があります。しかし、この信じられないような溝を越え、デジタルピープルをより自然に見せ、感じさせるようにするには、まだ膨大な作業が必要です。これは私たちのビジョンであるだけでなく、絶え間なく追い求める目標なのです。
私たちがこれまでに達成したことをお見せする前に、中国・台湾への温かいご挨拶をさせてください。夜市の華やかさを掘り下げる前に、デジタルピープル・テクノロジーの最先端を一緒に見てみましょう。
ACE(アバター・クラウド・エンジン)がクラウド上で効率的に動作するだけでなく、PC環境にも対応していることは本当に素晴らしいことです。すべてのRTXシリーズにTensor Core GPUを統合したことは、AI GPUの時代が到来したことを示すものであり、その準備は万端です。
この背後にある論理は明確です。新しいコンピューティング・プラットフォームを構築するには、まずしっかりとした基礎を築く必要があります。強固な基盤があれば、アプリケーションは自然に後からついてきます。そのような基盤がなければ、アプリの居場所はない。つまり、アプリのブームは、我々がそれを構築して初めて可能になるのです。
私たちがすべてのRTX GPUにTensor Coreプロセッシング・ユニットを統合したのはそのためです。現在、世界中で1億台のGeForce RTX AI PCが使用されており、その数は増え続け、2億台に達する見込みです。先日のComputexショーでは、4つの新しいAIラップトップも発表しました。
これらのデバイスはすべて、AIを実行する機能を備えています。未来のラップトップやPCはAIの乗り物となり、バックグラウンドで静かにあなたを助け、サポートしてくれるでしょう。同時に、これらのPCはAIによって強化されたアプリも実行するため、写真編集や執筆、その他のツールの使用にかかわらず、AIがもたらす利便性と強化を享受することができる。

さらに、PCはAIを搭載した人間のデジタルアプリをホストできるようになり、PC上でAIをより多様な方法で提示し、使用できるようになります。PCが重要なAIプラットフォームになることは明らかです。では、私たちはここからどこへ向かうのでしょうか?
前回、データセンターの拡張についてお話ししましたが、拡張のたびに新たな変化が訪れます。DGXから大規模なAIスーパーコンピューターにスケールアップしたとき、巨大なデータセットでTransformerの効率的なトレーニングを達成しました。これは大きな変化をもたらしました。当初、データには人間の監視が必要で、AIは人間のラベリングによって訓練されていました。しかし、人間がラベル付けできるデータ量には限界があった。現在では、Transformerによって教師なし学習が可能になった。
今日、Transformerは膨大な量のデータ、ビデオ、画像を独自に探索し、それらから学習し、隠れたパターンや関係を発見することができる。AIを次のレベルに引き上げるためには、次世代AIは物理法則の理解に根ざしている必要がありますが、ほとんどのAIシステムは物理世界に対する深い理解に欠けています。写実的な画像、動画、3Dグラフィックスを生成し、複雑な物理現象をシミュレートするためには、物理法則を理解し、適用できる物理ベースのAIを開発することが急務です。
この目標を達成するためには、主に2つのアプローチがあります。1つ目は、動画から学習することで、AIは物理世界の知識を徐々に蓄積することができます。第二に、合成データを使用することで、AIシステムに豊かで制御された学習環境を提供することができます。さらに、模擬データとコンピューターの相互学習も効果的な戦略だ。このアプローチは、AlphaGoの自己対局モードと似ており、同じ能力を持つ2つの実体が長期間にわたって互いに学習することで、継続的に知能を向上させることができる。したがって、この種のAIは将来、徐々に本領を発揮するようになるだろうと予測できる。
AIデータを合成的に生成し、強化学習技術と組み合わせると、データ生成の速度は大幅に向上する。データ生成量が増えれば、それに応じてコンピューティング・パワーに対する需要も高まる。AIが物理法則を学習し、物理世界からのデータを理解し、判断や行動の根拠とすることができるようになる新たな時代が訪れようとしている。その結果、AIモデルは拡大し続け、GPU性能がますます要求されるようになると予想されます。
この需要に応えるために、Blackwellが作られました。次世代のAIをサポートするように設計されたこのGPUは、いくつかの主要なテクノロジーを備えています。
このチップの圧倒的なサイズは、業界でも他に類を見ません。私たちは可能な限り大きなチップを2つ用意し、世界最先端のSerDes(高性能インターフェースまたは接続技術)と組み合わせた毎秒10テラバイトの高速リンクを通じて、それらを緊密にリンクさせました。さらに、2つのチップを1つのコンピュータノードに配置し、グレースCPUと効率的に連携させています。
グレイスCPUは多機能で、トレーニングシナリオだけでなく、高速チェックポイントや再起動といった推論や生成プロセスでも重要な役割を果たします。加えて、AIシステムがユーザーの対話の文脈を記憶し理解することを可能にし、対話の継続性と円滑性を高めるために重要です。
私たちは、AIの計算効率をさらに高めるために、第2世代のTransformerエンジンを導入しました。このエンジンは、計算レイヤーの精度と範囲の要件に基づいて低精度に動的に調整するため、パフォーマンスを維持しながら消費電力を抑えることができます。また、Blackwell GPUにはセキュリティAI機能が搭載されており、ユーザーがサービスプロバイダーに盗難や改ざんから保護するよう依頼できるようになっています。
GPUの相互接続に関しては、複数のGPUを簡単に接続できる第5世代のNVリンク技術を使用しています。また、Blackwell GPUには、チップ上のすべてのトランジスタ、フリップフロップ、RAM、オフチップメモリをテストする革新的な技術である第1世代の信頼性・可用性エンジン(Ras System)が搭載されており、特定のチップが現場で問題なく動作しているかどうかを正確に判断できるようにしています。この革新的な技術では、チップ上のすべてのトランジスタ、フリップフロップ、メモリ、およびオフチップ・メモリをテストし、特定のチップが平均故障間隔(MTBF)基準を満たしているかどうかをその場で正確に判断できるようにしています。
信頼性は、大規模なスーパーコンピューターにとって特に重要です。10,000個のGPUを搭載したスーパーコンピューターのMTBFは数時間かもしれませんが、GPUの数が100,000個に増えると、MTBFは数分に減少します。したがって、数ヶ月かかるような複雑なモデルを学習させるために、スパコンを長時間安定して稼働させるためには、技術革新によって信頼性を向上させる必要がある。そして信頼性の向上は、システムの稼働時間を延ばすだけでなく、効果的にコストも削減します。
最後に、先進的な解凍エンジンもBlackwell GPUに統合しました。データ処理に関しては、解凍速度が非常に重要です。このエンジンを統合することで、既存の技術よりも最大20倍速くストレージからデータを引き出すことができ、データ処理効率が劇的に向上しました。
以上のようなBlackwell GPUの特徴により、魅力的な製品となっています。前回のGTCカンファレンスでは、プロトタイプのBlackwellをお見せしました。

みなさん、これが信じられないようなテクノロジーを使ったBlackwellです。私たちの最高傑作であり、現在世界で最も洗練され、最も高性能なコンピューターです。特に特筆したいのは、膨大な計算能力を持つグレースCPUです。ほら、この2つのブラックウェル・チップ、密接につながっているでしょ。お気づきですか?これは世界最大のチップで、2つのチップを1つに融合させるために、毎秒最大A10TBのリンクを使用しています。
では、Blackwellとは一体何なのか?それは信じられないほど強力です。この数字をよく見てください。わずか8年間で、コンピューティング・パワー、浮動小数点コンピューティング、AI浮動小数点コンピューティング・パワーは1,000倍になりました。これは、ムーアの法則の成長をほぼ凌ぐ速度です。
ブラックウェルの計算能力の伸びは驚異的というほかありません。そしてさらに注目に値するのは、我々のコンピューティングパワーが向上するたびに、コストが下がり続けていることです。お見せしましょう。GPT-4モデル(2兆のパラメータと8兆のトークン)を訓練するために使用したエネルギー量は、計算能力を上げることで350分の1になりました。
同じトレーニングをPascalを使って行ったとすると、1,000ギガワット時のエネルギーを消費することになります。これは、それをサポートするためにギガワットのデータセンターが必要であることを意味しますが、そのようなデータセンターは世界には存在しません。仮にあったとしても、1カ月間連続稼働させる必要がある。また、100メガワットのデータセンターであれば、トレーニングには1年はかかるだろう。
明らかに、誰もそのようなデータセンターを作ろうとしないし、作ることもできない。だからこそ8年前、ChatGPTのような大きな言語モデルは、私たちにとってまだ遠い夢だったのです。しかし今日、私たちはパフォーマンスを向上させ、エネルギー消費を削減することで、それを実現しています。
私たちはBlackwellを使って、1,000ギガワット時までかかっていたエネルギーをわずか3ギガワット時まで削減しました。1,000個のGPUを使用して、コーヒー1杯のカロリーと同程度のエネルギーしか消費しないことを想像してみてほしい。万個のGPUを使えば、同じタスクをわずか10日ほどで達成できる。この8年間の進歩は信じられないほどだ。

Blackwell は推論だけでなく、トークン生成性能の向上もさらに素晴らしいものです。Pascal時代には、各トークンは17,000ジュールものエネルギーを消費していましたが、これは電球2個を2日間動かすのにほぼ相当します。一方、GPT-4トークンを生成するには、200ワットの電球2個分を2日間連続使用する必要がある。単語を生成するのに約3個のトークンが必要なことを考えると、これは実に大きなエネルギーの消耗です。
しかし、Blackwellは、トークン1つあたりわずか0.4ジュールのエネルギーを消費するだけで、驚くほど高速かつ非常に低いエネルギー消費でトークンを生成することを可能にしたため、状況は大きく変わりました。これは確かに大きな飛躍である。しかし、それでも私たちは満足しなかった。さらに大きな飛躍のためには、さらに強力なマシンを作る必要があった。
これがBlackwellチップが組み込まれるDGXシステムです。これらのGPUのヒートシンクを見てください、驚くほど大きいです。システム全体の消費電力は約15kWで、完全に空冷されている。このバージョンはX86互換で、すでに出荷したサーバーに搭載されています。
しかし、液冷をお好みであれば、このマザーボードの設計をベースとし、「モジュラー」システムと呼んでいるMGXと呼ばれる全く新しいシステムがあります。MGXシステムの心臓部には2つのBlackwellチップがあり、各ノードには4つのBlackwellチップが統合されています。効率的で安定した動作を保証するため、液冷技術を採用しています。
このようなノードがシステム全体で9つあり、合計72個のGPUが巨大なコンピューティング・クラスターを構成している。これらのGPUは、技術的に驚異的な新しいNVリンク技術を通じて、シームレスなコンピューティング・ネットワークを形成するためにリンクされています。NVリンクスイッチは、現在世界で最も先進的なスイッチであり、そのデータ転送速度は驚異的です。これらのスイッチにより、各Blackwellチップは効率的に接続され、巨大な72 GPUクラスターを形成することができます。
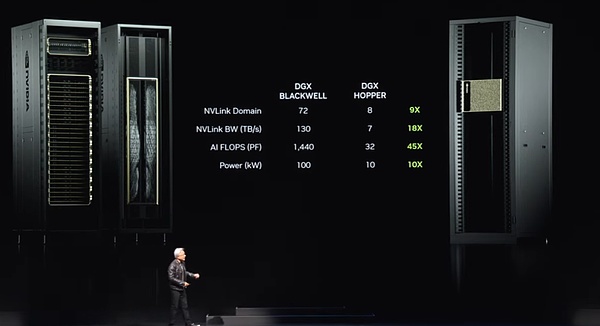
このクラスターの利点は何でしょうか?第一に、GPU領域において、単一の超大型GPUのように動作するようになりました。この「スーパーGPU」は72GPUのコアパワーを持ち、前世代の8GPUと比較して9倍の性能向上を実現しています。同時に、帯域幅は18倍、AI FLOPS(1秒あたりの浮動小数点演算数)は45倍になったが、電力は10倍にしかなっていない。つまり、このようなシステム1台で、前世代ではわずか10キロワットだったのに対し、100キロワットの強力な電力を供給できることになる。
もちろん、これらのシステムをより多く接続して、さらに大規模なコンピューティング・ネットワークを形成することもできます。しかし、本当の奇跡はこのNVリンク・チップであり、このチップは、大きな言語モデルがますます大きくなるにつれて、ますます重要になってきています。このような大きな言語モデルは、もはや1つのGPUやノードだけでは実行できないため、ラック全体のGPUの共同作業が必要になります。先ほど述べた新しいDGXシステムのように、数十兆のパラメーターを持つ大きな言語モデルを収容することができます。
NVリンク・スイッチ自体は、500億個のトランジスタ、74個のポート、1ポートあたり最大400GBのデータ転送速度を持つ、技術的に驚異的なものです。
しかしさらに重要なのは、このスイッチには数学的アルゴリズムも統合されており、ディープラーニングにおいて非常に重要な、直接還元不条理演算が可能なことです。これは現在、DGXシステムの新しい顔となっている。
多くの人が私たちに好奇心を示しています。彼らは質問をし、NVIDIAのビジネスの範囲を誤解しています。人々は、NVIDIAがGPUを作るだけで、どうしてこれほど巨大になることができたのかと。その結果、多くの人がGPUはある特定の方法で見えることになっているという印象を形成してしまった。
しかし、これからお見せするのは、これは確かにGPUですが、あなたが思っているようなものではないということです。これは世界で最も先進的なGPUの1つですが、主にゲームで使用されています。しかし、私たちがよく知っているように、GPUの真のパワーはそれをはるかに超えるものなのです。
皆さん、これを見てください。これがGPUの真の姿です。これはディープラーニング用に設計されたDGX GPUです。このGPUの背面は、長さ3キロメートルの5,000本のワイヤーで構成されるNVリンク・バックボーンに接続されています。NVリンク・バックボーンであるこれらのワイヤーは、70個のGPUを接続し、強力なコンピューティング・ネットワークを形成している。トランシーバーによって、銅線の全長にわたって信号を駆動できる電気機械的な驚異です。
そのため、このNVリンク・スイッチは、NVリンク・トランクを介して銅線でデータを伝送することで、1つのラックで20キロワットの電力を節約することができます。これがNVリンク・バックボーンの力です。
しかし、それだけでは需要を満たすには不十分であり、特に大規模なAI工場には不十分であるため、別の解決策があります。高速ネットワークを使用して、これらのAI工場を接続する必要があります。InfiniBandとイーサネットです。このうち、InfiniBandはすでに世界中のスーパーコンピューティングやAI工場で広く使われており、急速に成長している。しかし、すべてのデータセンターがすぐにInfiniBandを使えるわけではありません。イーサネットのエコシステムに多大な投資をしてきたため、InfiniBandのスイッチとネットワークを管理するには、一定レベルの専門知識と技術が必要です。
ですから、私たちのソリューションは、InfiniBandのパフォーマンスをイーサネット・アーキテクチャに導入することです。その理由は、各ノード(各コンピュータ)は通常、インターネット上の異なるユーザーに接続されていますが、通信のほとんどは実際にはデータセンター内で行われるため、つまりデータセンターとインターネットの向こう側にいるユーザーとの間でデータを転送するためです。しかし、AIファクトリーのディープラーニングシナリオでは、GPUはインターネット上のユーザーと通信しているのではなく、頻繁に、集中的にデータを交換しています。
互いに通信するのは、どちらも部分的な結果を収集しているからです。そして、これらの部分的な結果を制定(縮小)し、再配布(再分配)しなければなりません。この通信パターンは、非常にバースト的なトラフィックによって特徴付けられます。重要なのは平均スループットではなく、最後に到着するデータだ。なぜなら、あなたが全員から部分的な結果を集めていて、私があなたの部分的な結果をすべて受信しようとしている場合、最後のパケットの到着が遅れると、全体の動作が遅れてしまうからだ。待ち時間はAI工場にとって重要な問題です。
ですから、焦点は平均スループットではなく、最後のパケットが時間通りに間違いなく到着することなのです。しかし、従来のイーサネットは、この高度に同期した低遅延の要件に最適化されていません。このニーズに応えるため、私たちはNIC(ネットワーク・インターフェイス・カード)とスイッチが通信できるエンド・ツー・エンドのアーキテクチャを創造的に設計しました。
まず、NVIDIAは業界をリードするRDMA (Remote Direct Memory Access) テクノロジーを備えています。現在では、イーサネット・ネットワークレベルのRDMAがあり、非常に優れたパフォーマンスを発揮しています。
次に、輻輳制御メカニズムを導入しました。スイッチにはリアルタイムの遠隔測定機能があり、ネットワークの輻輳(ふくそう)を素早く特定して対応します。GPUやNICのデータ送信量が多すぎる場合、スイッチは即座に送信レートを落とすよう信号を送り、ネットワークのホットスポットの発生を効果的に回避します。
第三に、アダプティブ・ルーティング技術を使用しています。従来のイーサネットは固定された順序でデータを送信しますが、私たちのアーキテクチャでは、リアルタイムのネットワーク状況に柔軟に対応することができます。輻輳が検出されたり、特定のポートがアイドル状態になると、そのアイドル状態のポートにパケットを送信し、相手側のブルーフィールドデバイスが正しい順序でデータが返されるようにパケットの順序を変更します。このアダプティブ・ルーティング技術は、ネットワークの柔軟性と効率を大幅に向上させます。
第4に、ノイズ分離技術を実装しました。データセンターでは、同時にトレーニングされた複数のモデルによって生成されたノイズやトラフィックが互いに干渉し、ジッターの原因となることがあります。私たちのノイズ分離技術は、このノイズを効果的に分離し、重要なパケットの伝送が影響を受けないようにします。
これらの技術を採用することで、当社はAI工場向けに高性能かつ低遅延のネットワーキング・ソリューションを提供することに成功しました。数十億ドル規模のデータセンターにおいて、ネットワークの利用率を40%向上させ、トレーニング時間を20%短縮することは、事実上、50億ドルのデータセンターが60億ドルのデータセンターと同等の性能になることを意味し、ネットワーク性能が全体的なコスト効率に与える影響が大きいことを明らかにしています。
幸いなことに、Spectrum Xを搭載したイーサネットは、ネットワークパフォーマンスを劇的に向上させ、データセンター全体に対してネットワークコストを事実上無視できるようにし、この目標を達成するための鍵となります。これは、ネットワーク技術の分野で私たちにとって大きな成果であることは間違いありません。
当社には堅牢なイーサネット製品ラインがあり、特にSpectrum X800は、256パス(基数)をサポートし、毎秒51.2TBで数千のGPUに効率的なネットワーク接続を提供します。次に、1年後にX800 Ultraを発売する予定ですが、これは512パスで最大512基軸をサポートし、ネットワーク容量と性能をさらに向上させます。一方、X 1600はさらに大規模なデータセンター向けに設計されており、何百万ものGPUの通信ニーズを満たすことができます。

テクノロジーの進歩に伴い、数百万GPUのデータセンターの時代がすぐそこまで来ています。このトレンドの背景には深い理由があります。一方では、私たちはより大規模で複雑なモデルを訓練することを熱望していますが、より重要なのは、インターネットとコンピュータ対話の未来は、クラウド上の生成AIにますます依存するようになるということです。これらのAIは、ビデオ、画像、テキスト、さらにはデジタル人物を生成するために、私たちと一緒に働き、対話する。その結果、私たちがコンピューターと行うほとんどすべてのインタラクションは、ジェネレーティブAIの関与なしには成り立たなくなる。そして、常に生成AIが接続されており、ローカルで実行されるものもあれば、デバイス上で実行されるものもあり、クラウド上で実行されるものも多いかもしれない。
これらの生成AIは、強力な推論ができるだけでなく、答えを反復的に最適化して、その質を向上させることができます。これは、将来的にデータ生成の需要が大量に発生することを意味します。今夜、私たちはこの技術革新の力を目の当たりにした。
エヌビディア・プラットフォームの第一世代であるBlackwellは、発売以来、脚光を浴びてきました。今日、ジェネレーティブAIの時代が世界的に到来し、まったく新しい産業革命の幕開けとなり、各所でAI工場の重要性が認識されています。私たちは、あらゆるOEM(相手先ブランド製造)、コンピューターメーカー、CSP(クラウドサービスプロバイダー)、GPUクラウド、ソヴリンクラウド、通信会社など、幅広い業界から幅広い支持を得ていることを光栄に思っています。
Blackwellの成功、広範な採用、そして業界の熱意は、史上最高の状態にあります。しかし、私たちはその地位に甘んじるつもりはありません。この急速に進化する時代において、私たちは製品のパフォーマンスを向上させ、トレーニングと推論にかかるコストを削減する努力を続けるとともに、あらゆる組織がAIの恩恵を受けられるよう、AIの能力を常に拡大していきます。性能が向上すれば、コストはさらに削減されると確信しています。そしてHopperプラットフォームは、間違いなく、歴史上最も成功したデータセンター・プロセッサーになるかもしれません。
これはまさに度肝を抜くサクセスストーリーです。Blackwell プラットフォームは、ご覧の通り、単一のコンポーネントのスタックの結果ではありません。CPU、GPU、NVLink、NICK(技術固有のコンポーネント)、およびNVLinkスイッチの複数の要素を組み合わせた完全なシステムです。世代が進むごとに、大規模で超高速のスイッチを使用してすべてのGPUを緊密に接続し、大規模で効率的なコンピュート・ドメインを形成することを目指しています。
私たちは、プラットフォーム全体をAIファクトリーに統合していますが、より重要なのは、このプラットフォームをモジュール形式で世界中の顧客に提供することです。その理由は、各パートナーが、異なるスタイルのデータセンター、異なる顧客セグメント、多様なアプリケーション・シナリオに合わせて、それぞれのニーズに合ったユニークで革新的な構成を構築することを期待しているからです。エッジコンピューティングからテレコムまで、システムがオープンである限り、あらゆる種類のイノベーションが可能になります。
イノベーションを起こす自由を与えるために、私たちはオールインワンのプラットフォームを設計しましたが、モジュール式のシステムを簡単に構築できるように、分解された形で利用できるようにしました。Blackwellプラットフォームは現在完全に利用可能です。
NVIDIAは常に年次更新のペースを維持してきました。1)データセンターの規模全体をカバーするソリューションを構築すること、2)それらのソリューションを個々のコンポーネントに分解し、1年に1度の頻度で世界中の顧客に展開すること、3)究極のパフォーマンス性能を追求するために、TSMCのプロセス技術、パッケージング技術、メモリ技術、光学など、あらゆる技術を極限まで高めるために手を抜かないこと、です。
ハードウェアの極限への挑戦を完了した後、すべてのソフトウェアがこの完全なプラットフォーム上でスムーズに動作できるように最善を尽くします。コンピューター技術では、ソフトウェアの慣性が重要です。既存のソフトウェアと後方互換性があり、アーキテクチャ的にも互換性のあるコンピュータ・プラットフォームがあれば、市場投入までのスピードは飛躍的に向上します。ですから、Blackwellプラットフォームが登場したとき、私たちはこれまで築いてきたソフトウェア・エコシステムを活用して、驚くべき市場投入スピードを実現することができました。来年、私たちはBlackwell Ultraを迎えます。
H100およびH200シリーズと同様に、Blackwell Ultraは前例のないイノベーションを実現する新世代の製品への道を切り開くでしょう。同時に、業界初となる次世代スペクトラム・スイッチの導入により、技術の限界に挑み続けます。私は今、この決定を公表することを少しためらっていますが、この大きなブレークスルーはすでに成功裏に達成されています。
NVIDIA内部では、コードネームを使用し、一定のレベルの機密性を維持することに慣れています。多くの場合、社内のほとんどの従業員でさえ、これらの秘密をよく知りません。しかし、私たちの次世代プラットフォームは「Rubin」と名付けられ、ここではRubinについてあまり詳しくは触れません。皆さんの好奇心はわかりますが、少しミステリアスにしておきましょう。おそらく写真を撮ったり、小さな活字を調べたりするのが待ちきれないでしょうから、ご自由にどうぞ。
Rubinプラットフォームだけでなく、1年後にはRubin Ultraプラットフォームも登場します。ここにあるチップはすべて、細部まで磨き上げられた完全な開発中です。私たちのアップデートのペースは年1回で、すべての製品が100%のアーキテクチャ互換性を維持することを保証しながら、常に最高の技術を目指しています。

Imagenetが誕生した瞬間から、過去12年間を振り返ってみて、私たちはコンピューティングの未来が劇的に変化することを思い描いていました。今日、それはすべて、私たちが思い描いたとおりに実現しています。2012年以前のGeForceから今日のNVIDIAに至るまで、当社はとてつもない変貌を遂げてきました。その道のりを支え、伴走してくれたすべてのパートナーに感謝したいと思います。
今回はNVIDIAのBlackwellプラットフォームということで、人工知能とロボット工学を組み合わせた未来についてお話ししましょう。
物理的AIは、物理法則を理解し、それを日常生活に快適に統合するAIの新しい波をリードしています。そのためには、物理AIは、周囲の世界をどのように解釈し認識するかを理解するために、世界の正確なモデルを構築するだけでなく、私たちのニーズを深く理解し、タスクを効率的に実行するための優れた認知能力を持つ必要があります。
将来を見据えると、ロボット工学はもはや突飛な概念ではなく、私たちの日常生活にますます溶け込んでいくだろう。ロボット技術というと、人型ロボットを連想しがちですが、実際にはその応用範囲ははるかに超えています。機械化が当たり前になり、工場は完全に自動化され、ロボットは連動して機械化されたさまざまな製品を生み出すようになるだろう。ロボット同士はより密接に相互作用し、協力して高度に自動化された生産環境を作り出すだろう。
これを実現するためには、いくつもの技術的課題を克服する必要がある。これらの最先端技術をビデオでお見せします。
これは単なる未来のビジョンではなく、現実になりつつあります。
私たちはさまざまな方法で市場に貢献していきます。まず、私たちはさまざまなタイプのロボットシステム用のプラットフォームの構築に取り組んでいます。ロボット工場や倉庫用のプラットフォーム、物体操作ロボット用のプラットフォーム、移動ロボット用のプラットフォーム、人型ロボット用のプラットフォームなどです。これらのロボティクス・プラットフォームは、当社の他の多くの事業と同様に、コンピュータで高速化されたライブラリと事前に訓練されたモデルに依存しています。
Omniverseでは、コンピュータアクセラレートされたライブラリ、事前に訓練されたモデル、そしてテスト、トレーニング、統合のすべてを使用しています。ビデオにあるように、Omniverseはロボットが現実世界によりよく適応する方法を学ぶ場所です。もちろん、ロボット倉庫のエコシステムは非常に複雑であり、最新の倉庫を構築するためには、多数の企業、ツール、テクノロジーが結集する必要がある。今日、倉庫は完全な機械化に向かっており、いつか完全に自動化されるだろう。
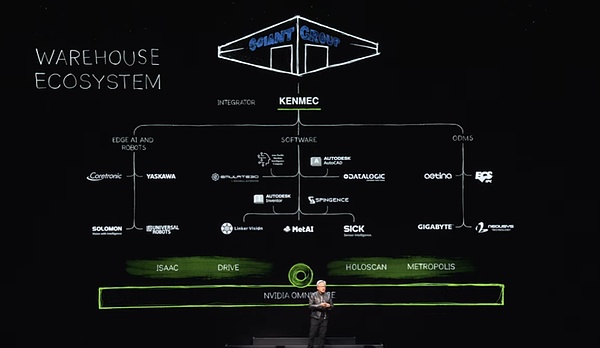
このようなエコシステムにおいて、私たちはソフトウェア業界、エッジAI業界、企業にSDKやAPIインターフェースを提供するとともに、国防省などの特定領域のニーズに対応するため、PLCやロボットシステムに特化したシステムを設計しています。これらのシステムはインテグレーターを通じて統合され、最終的には顧客のために効率的でインテリジェントな倉庫を構築する。一例として、ケン・マックはジャイアント・ジャイアント・グループのためにロボット倉庫を構築しています。
次に工場部門に注目してみよう。工場には非常に異なるエコシステムがあります。例えばフォックスコンは、世界で最も先進的な工場を建設している。これらの工場のエコシステムには、エッジ・コンピューター、工場のレイアウトを設計し、ワークフローを最適化し、ロボットをプログラミングするためのロボティクス・ソフトウェア、デジタル工場やAI工場をオーケストレーションするためのPLCコンピューターも含まれています。私たちは同様に、これらのエコシステムそれぞれにSDKインターフェースを提供しています。
このような変化は世界的に起こっています。FoxconnとDeltaは、現実とデジタルの完璧な融合を達成するために、工場用にデジタルツインを構築しており、Omniverseはこれにおいて重要な役割を果たしています。また、PEGATRONとWistronがこの流れに乗り、それぞれのロボット工場のためにデジタルツインを構築していることも注目に値します。
これは本当にエキサイティングなことです。次に、Foxconnの新しい工場の素晴らしいビデオをお楽しみください。
ロボット工場は3つの主要なコンピューターシステムで構成されており、NVIDIAのAIプラットフォームでAIモデルをトレーニングすることで、ロボットがローカルシステム上で効率的に動作し、工場のプロセスを振り付けできるようにしています。同時に、シミュレーション・コラボレーション・プラットフォームであるOmniverseを使用して、ロボットアームやAMR(自律移動ロボット)を含むすべての工場要素をシミュレートしています。これらのシミュレーションはすべて、シームレスな相互作用とコラボレーションのために同じ仮想空間を共有しています。
ロボットアームやAMRがこの共有仮想空間に入ると、Omniverseで実際の工場環境をシミュレートすることができ、実際の配備前に完全な検証と最適化を行うことができます。
ソリューションの統合と適用範囲をさらに強化するために、アクセラレーションレイヤーと事前に訓練されたAIモデルを備えた3台の高性能コンピュータを提供しました。さらに、NVIDIA ManipulatorとOmniverseをシーメンスの産業オートメーション・ソフトウェアおよびシステムと組み合わせることに成功しました。このコラボレーションにより、シーメンスは世界中の工場でより効率的なロボット操作と自動化を実現することができました。
シーメンス以外にも、私たちは多くの有名企業とパートナーシップを結んでいます。例えば、Symantec Pick AIはNVIDIA Isaac Manipulatorを統合しており、Somatic Pick AIはABB、KUKA、Yaskawa Motomanといった有名ブランドのロボットの稼働と操作に成功しています。
ロボット工学とフィジカルAIの時代が到来し、それらがSFとしてではなく、現実として、あらゆる場所で利用されていることを知るのはエキサイティングなことだ。未来に目を向けると、工場でのロボットが支配的となり、あらゆる製品を作るようになるだろうが、特に2つの大量ロボット製品がある。1つ目は自動運転車、あるいは高度な自律性を持つ車であり、今回もエヌビディアは包括的な技術スタックによってこの分野で中心的な役割を果たしています。来年にはメルセデス・ベンツのチームと、次いで2026年にはジャガー・ランドローバー(JLR)のチームと手を組む予定です。私たちは完全なソリューションスタックを提供しますが、ドライブスタック全体がオープンでフレキシブルであるため、顧客は必要に応じてどの部分や階層も選択することができます。
ロボット工場で大量生産できる次の製品は、人型ロボットです。近年、認知能力と世界理解の飛躍的な進歩により、この分野の将来は有望です。私が特にヒューマノイドロボットに期待しているのは、我々が人間のために築いてきた世界に適応できる可能性が最も高いからです。
ヒューマノイドロボットのトレーニングには、他のタイプのロボットと比べて多くのデータが必要です。私たちは似たような体型をしているため、デモンストレーションやビデオ機能を通じて得られる大量のトレーニングデータは非常に貴重なものになるでしょう。その結果、この分野での大きな進歩が期待されます。

さて、特別なロボットの仲間を迎えましょう。ロボット工学の時代が到来し、人工知能の次の波が押し寄せています。中国・台湾は、キーボードを備えた伝統的なモデルから、小型軽量で持ち運び可能なモバイル機器、さらにはクラウドベースのデータセンターに強力なコンピューティング・パワーを提供する特殊機器まで、幅広いコンピュータを製造している。しかしこの先、私たちはさらにエキサイティングな時代に立ち会おうとしている。つまり、歩いたり転がったりするコンピューター、つまりインテリジェント・ロボットの製造だ。
このようなスマートロボットは、先進的なハードウェアとソフトウェア技術の上に構築された、私たちが知っているコンピュータと技術的によく似ています。だから、これは本当に驚くべき旅になると信じる理由がある!
今週月曜日、エヌビディアの株価は再び史上最高値を更新し、時価総額は3兆5000億ドルを超え、世界ナンバーワンのアップルと肩を並べた。
JinseFinanceしかし、億万長者がたびたび謎の失踪を遂げるこの国で、コリン・ホアンはいつまで持ちこたえることができるだろうか。ルネッサンスCEOのバオ・ファン、不動産王の任志強、そして最も著名なアリババ創業者のジャック・マーは、いずれも全盛期に地球上から姿を消した。
 XingChi
XingChi人工知能,メタ,黄健賢、ザッカーバーグのピーク対談書き起こし:1万字の長文記事でメタのAI未来像が明らかに ゴールデンファイナンス,黄健賢、ザッカーバーグはAIの未来をどう見るか?
JinseFinanceゴールデンファイナンスは、朝の暗号通貨・ブロックチェーン業界ニュースレター「Golden Morning 8, Issue 2340」を創刊し、最新・最速のデジタル通貨・ブロックチェーン業界ニュースをお届けします。
JinseFinanceエヌビディアの株価は昨日、史上最高値を更新し、終値は7%高の1139.01ドルだった。現在台湾にいるジェンセン・フアン氏は、台湾はAIの中心であり、台湾のAI産業の発展をさらに促進することを楽しみにしているとインタビューで述べた。
 Sanya
SanyaHuang Licheng氏のMemecoin Bobaoppaは、ステーキングと送金で19万5000SOL(3600万ドル)を集めたが、MithrilやFormosaを含む彼の過去のプロジェクトは、怪しげな慣行を懸念させる。
 Alex
AlexLICHENG HUANGのBlurとの2500万ドルの紛争とBlastへの3000ETHの入金は、暗号世界に波紋を広げ、激しい憶測とドラマの展開への期待を呼び起こす。
 Cheng Yuan
Cheng YuanHuang氏は、Zach氏の暗号コミュニティへの貢献を認め、法的措置は最後の手段であると表明した。
 Davin
Davin近年、仮想通貨の訴訟が爆発的に増加しています。
 Beincrypto
Beincrypto6月17日のニュースによると、暗号化されたKOL zachxbtが発行した記事によると、Jeffrey Huang(ジェフリー・ファン)は、Mithril(MITH)、Formosa Financial(FMF)、Machi X、Cream Finance(CREAM)などの数十のトークンを連続して発行しました。 、および Swag Finance (SWAG) のゴミアイテム。
 链向资讯
链向资讯