アルウィーヴの仕組みとその意味
Arweave,Arweaveの仕組みと存在意義 Golden Finance,この記事では、Arweaveの仕組みと存在意義について簡単に説明します。
 JinseFinance
JinseFinance

著者:Arweave Source:X、@ArweaveOasis
アーウィーブ・エコシステムは、2018年の立ち上げ以来、分散型ストレージ回路で最も価値のあるネットワークの1つとみなされてきた。しかし、5年が経過した現在、そのテクノロジー主導の属性により、多くの人々がArweave/ARをよく知っているようで知らない。この記事では、まずArweaveの深い理解を深めるために、Arweaveの創業以来の技術開発の歴史を振り返ります。
Arweaveは5年間で10回以上の大きな技術アップグレードを経ており、その主な反復の中心的な目標は、計算機主導の採掘メカニズムからストレージ主導の採掘メカニズムに移行することでした。
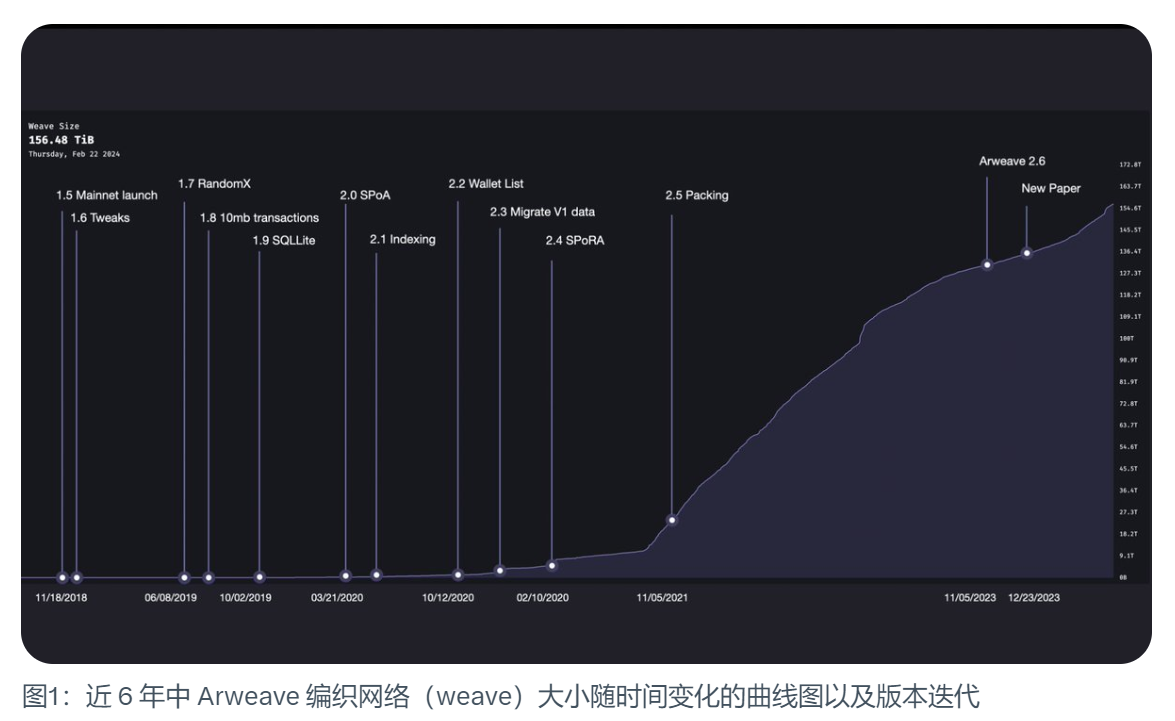
Arweave 1.5: メインネットワーク立ち上げ
Arweaveのメインネットワークは2018年11月18日に立ち上げられました。当時、織物ネットワークのサイズはわずか177MiBでした。初期のArweaveは、ブロックアウト時間が2分、1ブロックの上限が1,000ストロークと、現在と似ている部分もありました。それ以外には、1トランザクションあたりのサイズ制限がわずか5.8MiBであることや、Proof of Accessと呼ばれるマイニングメカニズムが使われていたことなど、より多くの違いがあった。
問題は、アクセス証明(PoA)とは何かということだ。
簡単に言えば、新しいブロックを生成するために、マイナーはブロックチェーンの履歴にある他のブロックにアクセスできることを証明しなければならないということです。そのため、アクセス証明はチェーンからランダムに過去のブロックを選び、その過去のブロックをリコールブロックとして、生成しようとしている現在のブロックに入れるようマイナーに要求します。そしてそれは、そのリコール・ブロックの完全なバックアップとなる。
採掘者はすべてのブロックを保存する必要はなく、それらにアクセスできることさえ証明できれば、採掘で競争できるというものだった。(Dmac氏はビデオでカーレースに例えてわかりやすくしているので、ここに引用します)。
まず、このレースにはゴールがあり、参加者の人数や採掘のスピードに応じてゴールが移動し、常に2分程度でレースが終了するようになっています。これが2分間のブロックタイムの理由である。
次に、このコンテストは2つのパートに分かれている。
-予選と呼ばれる第1部では、採掘者は過去のブロックにアクセスできることを証明しなければならない。指定されたブロックを手にすれば、決勝ラウンドに進むことができる。もしマイナーが保管ブロックを持っていなくても、仲間からアクセスすることができ、同じように競争に参加することができる。
採掘者がゴールラインを超えると、レースは終了し、次のレースが始まる。そして、採掘報酬はすべて1人の勝者に支払われるため、採掘は信じられないほど激しくなる。その結果、Arweaveは急速に成長し始めた。

Arweave 1.7: RandomX
初期のArweaveの原理は非常にシンプルで理解しやすいメカニズムでしたが、研究者が1つの望ましくない結果に気づくのに時間はかかりませんでした。すなわち、採掘者がネットワークにとって有害な戦略(私たちはこれを「退化戦略」と呼んでいます)を採用するかもしれないということです。
主に、一部の採掘者は、指定された高速アクセスブロックを保存していないときに、他の人のブロックにアクセスしなければならないため、ブロックを保存している採掘者よりも一歩遅くなり、スタートラインで負けてしまうのだ。しかし、解決策も簡単で、GPUを大量に積み上げ、大きな演算能力と多くのエネルギーを消費することでこれを補うだけで、ブロックを保存して高速アクセスを維持するマイナーを上回ることもできる。この戦略が主流になれば、マイナーはブロックの保存と共有をやめ、代わりに演算装置を最適化し続け、競争に勝つために大量のエネルギーを消費するようになるだろう。その結果、ネットワークの実用性は著しく低下し、データは徐々に中央集権化されていくだろう。これは明らかに、ストレージネットワークの退化的な出発です。
この問題に対処するために、Arweaveバージョン1.7が登場しました。
このバージョンの最大の特徴は、RandomXと呼ばれるメカニズムの導入です。これはGPUやASICデバイスで実行するのが非常に困難なハッシュ式で、マイナーはGPUパワーを積み重ねるのをあきらめ、汎用CPUだけでハッシュパワー競争を競うようになります。
Arweave1.8/1.9:SQLライトによる10MiBトランザクションサイズ
マイナーにとって、過去のブロックへのアクセス権を持っていることを証明することよりも重要な事柄があり、それはユーザーによってArweaveに投稿されたトランザクションの処理です。
新しいユーザーの取引データはすべて新しいブロックにパッケージされなければならず、これはパブリックチェーンの最低条件です。Arweaveネットワークでは、ユーザーがトランザクションをマイナーに提出すると、そのマイナーはそのデータを自分の次のブロックにパッケージするだけでなく、他のマイナーと共有し、すべてのマイナーがそのトランザクションを次のブロックにパッケージできるようにする。なぜこのようなことをするのでしょうか。
-取引データがブロックに含まれるごとにそのブロックの報酬が増加するためである。マイナー同士が取引データを共有することで、ブロックを作る権利を獲得した人が最大の報酬を得られるようになる。
-ネットワーク発展のデス・スパイラルを防ぐ。もしユーザーの取引データが随時ブロックに詰め込まれなければ、ユーザーはますます少なくなり、ネットワークは価値を失い、マイナーは誰も望まない稼ぎを減らしてしまうだろう。
そこでマイナーたちは、このような相互に有益な方法で利益を最大化することを選択する。しかし、これは逆にデータ伝送の問題を引き起こし、ネットワークのスケーラビリティのボトルネックとなる。トランザクションが多ければ多いほどブロックは大きくなり、5.8メガバイトのトランザクション制限は何の役にも立たなかった。その結果、Arweaveはハードフォークによってトランザクションサイズを10メガバイトに増やすことで、いくらかの救済を得た。
しかし、それでも伝送のボトルネックはまだ解決されていません。Arweaveはマイナーのグローバル分散ネットワークであり、すべてのマイナーが状態を同期する必要があります。そして、各マイナーは異なる速度の接続を持ち、ネットワークに平均接続速度を与える。ネットワークが2分ごとに新しいブロックを生成するためには、その2分間に保存したいデータをすべてアップロードできるだけの接続速度が必要だ。ユーザーがネットワークの平均接続速度を上回るデータをアップロードすると、輻輳が発生し、ネットワークの実用性が低下する可能性がある。これは、Arweaveの発展の妨げになる可能性がある。そのため、1.9以降のアップデートでは、SQL liteのようなインフラを使用してネットワークのパフォーマンスを向上させています。
Arweave2.0:SPoA
2020年3月のArweave2.0へのアップデートは、ネットワークに2つの重要なアップデートを導入し、その結果、ネットワークのスケーラビリティの束縛を解き、Arweaveにデータを保存する能力の限界を打ち破りました。
最初のアップデートは「簡潔な証明」です。これはメルケル・ツリー暗号構造に基づいており、採掘者は単純なメルケル・ツリー化された圧縮分岐パスを提供することで、ブロック内のすべてのバイトを保存したことを証明することができます。この変更により、採掘者は1KiB未満の簡潔な証明をブロックに詰め込むだけでよくなり、潜在的に10GiBの後ろ向きブロックを詰め込む必要がなくなりました。
2つ目のアップデートは「Format 2 Transactions」です。このバージョンでは、ノード間で共有されるデータ転送ブロックをスリム化するために、トランザクションの形式を最適化している。トランザクションのヘッダーとデータを同時にブロックに追加する必要があるフォーマット1トランザクションとは対照的に、フォーマット2トランザクションではヘッダーとデータを分離することができます。つまり、採掘者ノード間のブロック情報データ共有転送では、簡潔な証明を持つバックトラックブロックを除き、トランザクションのヘッダーのみをブロックに追加する必要があり、トランザクションのデータはレースの最後にブロックに追加することができます。これにより、マイナーノード間でブロック内トランザクションを同期させる際の伝送要件が大幅に削減される。
これらの更新の結果、従来よりも軽量で送信しやすいブロックが作成され、ネットワークの余剰帯域幅が解放されます。マイナーはこの時点でこの余剰帯域幅を使用して、将来バックトラックされたブロックとなる「フォーマット2トランザクション」のデータを送信する。こうしてスケーラビリティの問題は解決される。
Arweave2.4:SPoRA
これまでのところ、Arweaveネットワークの問題はすべて解決されているのでしょうか?答えは明らかに違う。新しいSPoAメカニズムでは、別の問題が生じています。
採掘者がGPUパワーを積み重ねる方法に似た採掘戦略が再び出現したのです。今回は、GPUスタッキングにおけるパワーの集中化ではなく、よりコンピュート中心になるかもしれない主流の戦略をもたらしている。それは、高速アクセス可能なストレージプールの出現だ。過去のブロックはすべてこのストレージ・プールに保持され、アクセス証明によってランダムなバックトラック・ブロックが生成されると、素早く証明を生成し、それを超高速でマイナー間で同期させることができる。
このような戦略でも、データは十分すぎるほどバックアップされ、保存される。
しかし問題なのは、このような戦略は無意識のうちに採掘者の焦点をずらすということです。採掘者はもはやデータへの高速アクセスを得るインセンティブを持たず、プルーフの転送が非常に簡単かつ高速になったため、データを保存する代わりにプルーフ・オブ・ワークロードのハッシュに労力の大半を費やすようになります。これもまた、退化した戦略の一種ではないだろうか?

そのため、Arweaveはデータインデックスの反復(Indexing)、ウォレットリストの圧縮(Wallet List)、V1トランザクションデータの移行など、いくつかの機能アップグレードを経てきました。最後に、もう一つの大きなリリースの反復--SPoRA(Succinct Proof of Random Access)です。
SPoRAは、マイナーがハッシュ計算からデータストレージに注意を移すことを可能にするメカニズムを反復することで、Arweaveを全く新しい時代に導入します。
それでは、ランダムアクセスの簡潔な証明はどのように違うのでしょうか?
それは2つの前提条件、
インデックスされたデータセットから始まります。バージョン2.1の反復インデックス機能により、
ネットワーク上の各データチャンク(Chunk)にグローバルオフセットを付け、このグローバルオフセットによって各チャンクに素早くアクセスできるようにします。これがSPoRAのコアメカニズムであるデータチャンクの逐次検索につながる。 ここで言うチャンクとは、パーティション分割後の大容量ファイルにおけるデータの最小単位であり、256KiBサイズであり、ブロックの概念ではないことを思い出していただきたい。
-スローハッシュ。このハッシュはランダムにチャンク候補を選択するために使用されます。バージョン1.7で導入されたRandomXアルゴリズムのおかげで、マイナーはパワースタッキングを使って先に進むことができず、CPUを使って計算することしかできない。
これら2つの前提条件に基づき、SPoRAメカニズムは4ステップのプロセスである
最初のステップでは、乱数が生成され、この乱数はRandomXを介して前のブロックの情報を持つスローハッシュを生成するために使用される。
2番目のステップでは、このスローハッシュはブロックのグローバルオフセットであるユニークリコールバイトを計算するために使用される。採掘者は、このリコールバイトを使用して、自身のストレージから 対応するデータブロックを見つける。採掘者がデータブロックを保存していない場合、最初のステップに戻り、再度開始する。
第4のステップでは、最初のステップで生成された低速ハッシュが、ちょうど見つかったデータブロックで高速ハッシュを実行するために使用される。
第5のステップでは、計算されたハッシュ結果が現在の採掘難易度値よりも大きい場合、ブロックの採掘と配布が完了する。その代わり、最初のステップに戻ってやり直します。
このように、採掘者にとっては、遠くのストレージプールではなく、非常に高速なバスでCPUに接続できるハードドライブにできるだけ多くのデータを保存する大きなインセンティブとなります。計算機重視からストレージ重視へのマイニング戦略の逆転が完成した。
アーウィーブ2.5:パッキングとデータサージ
SPoRAは、採掘効率を向上させるための最も低いぶら下がり果実であったため、マイナーが狂ったようにデータを保存し始めるようにしました。では、次に何が起こったのか?
一部の賢い採掘者は、この仕組みのボトルネックは、実はハードドライブからどれだけ速くデータをフェッチできるかであることに気づきました。ハードドライブからフェッチできるデータのチャンクが多ければ多いほど、計算できる証明も簡潔になり、実行できるハッシュ演算も増え、マイニングのチャンスも増える。
つまり、ある採掘者がハードディスクに10倍のコストをかけると、例えばデータの保存に読み書きの速度が速いSSDを使えば、その採掘者は10倍のハッシュ演算能力を持つことになる。もちろん、これはGPUコンピューティング・パワーと同様の軍拡競争になるだろう。SSDよりも高速なストレージ、例えば転送速度の速いエキゾチックなストレージであるRAMドライブも登場するだろう。しかし、すべては入出力比に依存する。
現在、採掘者がハッシュを生成できる最速の速度は、SSDハードドライブの読み書き速度であり、PoWのようなモードではエネルギー消費の上限が低くなるため、より環境に優しい。
それは完璧か? もちろんそうではない。技術者たちは、それよりもさらに良くなると考えている。
より大きなデータのアップロードを可能にするために、Arweave 2.5はデータバンドルを導入しています。これは実際にはプロトコルのアップグレードではなかったが、常にスケーラビリティ計画の大きな部分を占めていた。というのも、冒頭で話した1ブロックあたり1,000トランザクションという上限が破られるからだ。データ・バンドルはその1000トランザクションのうちの1つだけを占める。これがArweave 2.6の基礎となった。
Arweave 2.6
Arweave 2.6は、SPoRA以来のメジャーバージョンアップです。
Arweave 2.6は、SPoRA以来のメジャーバージョンアップとなります。
では、具体的に何が違うのでしょうか?スペースの都合上、ここでは簡単な概要を説明し、Arweave 2.6の仕組みについては今後より具体的に説明したいと思います。
簡単に言うと、Arweave 2.6は速度制限されたバージョンのSPoRAで、1秒に1回刻む検証可能な暗号クロックをSPoRAに導入しています。
- ハッシュチェーンは1秒ごとにマイニングハッシュを生成し、
- マイナーは自分の保存データパーティションのインデックスを選択してマイニングに参加します。これは、採掘者が採掘に使用できるブロックである。このバックトラックの範囲に加えて、ウィーブネットワーク(Weave)に別のバックトラックの範囲2もランダムに生成され、マイナーに十分なデータパーティションが保存されていれば、最終的な勝利のチャンスを増やすために、この範囲2、つまり別の400バックトラックブロックの採掘機会を得ることができる。これはマイナーにとって、データパーティションの十分なコピーを保存する良いインセンティブとなる。
- マイナーはバックトラック範囲内のブロックを使って1つずつテストし、その結果が現在の与えられたネットワーク難易度よりも大きければマイニングの権利を獲得し、それが満たされなければ次のブロックのデータを使ってテストします。
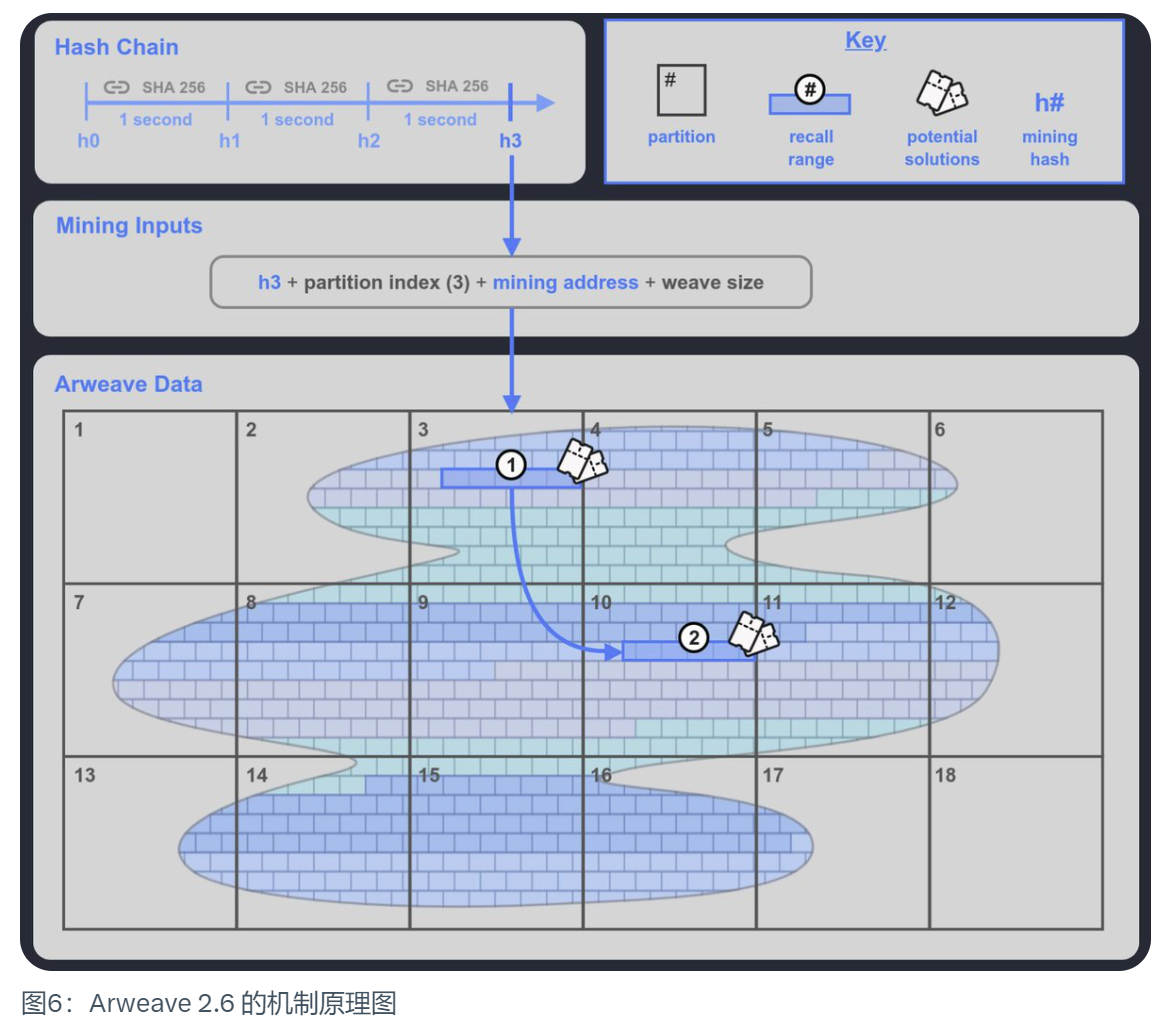
これは、1秒あたりに生成されるハッシュの最大数が固定されていることを意味し、バージョン2.6では、通常の機械式ハードドライブでも処理できる範囲内に維持されています。これにより、SSDベースのハードディスク・ドライブが最大で毎秒何千、何十万ものハッシュを生成する能力は影を潜め、毎秒数百のハッシュしか生成できない機械式ハードディスク・ドライブと競合することになります。制限速度が時速60キロメートルのレースで、ランボルギーニがトヨタのプリウスと競争するようなもので、ランボルギーニの優位性はかなり限られている。そのため、現在マイニングの性能に最も貢献しているのは、マイナーが保存しているデータセットの数である。
以上が、Arweaveの進化における重要な反復のマイルストーンである。2023年12月26日、Arweaveはホワイトペーパー2.7を正式にリリースしました。このホワイトペーパーでは、これらのメカニズムに大幅な調整を加え、コンセンサスメカニズムをSpoResの単純な複製証明へと進化させています。
Arweave,Arweaveの仕組みと存在意義 Golden Finance,この記事では、Arweaveの仕組みと存在意義について簡単に説明します。
JinseFinanceこの論文では、保存された寄付がどのように機能するのかを詳しく説明し、マルコフ連鎖を使ってその実行をモデル化することで、その特性とリスクプロファイルを検証する。
JinseFinanceこの記事では、ArweaveとIPFSの冗長性メカニズム、そしてどちらのオプションがデータにとってより安全かを見ていきます。
JinseFinanceWhatsAppのメッセージは毎日1000億通送信されている。ほとんどのブロックチェーンは保存用に設計されていない。1000億件のWhatsAppメッセージをイーサや他のブロックチェーンに保存しようと思ったら、そのコストは法外なものになるだろう。
JinseFinance本稿では、ArweaveとIPFSがどのようにファイルを保存、維持、アクセスし、それがデジタル資産の信頼性と永続性にどのような影響を与えるかを探る。
JinseFinanceArweaveは分散型データ・ストレージ・ソリューションで、Blockweaveテクノロジーとネイティブ暗号通貨ARトークンを通じて、永続的で不変のデータ・ストレージ・サービスを提供する。
JinseFinanceArweaveがファイルコインの代替ではなく、もっと注目されるべき大きなイノベーションである理由。
JinseFinanceIrysはArweaveをフォークし、トークンの供給をリセットする計画だが、Arweaveの創設者はこの動きを近視眼的で貪欲だと批判している。
 BerniceJinseFinance
BerniceJinseFinanceこのイベントには100人以上のArweaveエコシステムの開発者や投資家が参加する予定で、参加者には製品テストの機会、ARエアドロップの報酬、実用的な商品などの限定特典が提供される。
 Samantha
Samantha