
GTC 컨퍼런스 이후 작성된 글 Web3가 AI 컴퓨팅 성능을 향상시킬 수 있을까요?
웹 3.0,인공지능,산술,GTC 컨퍼런스 이후 작성된 글 웹3.0이 인공지능 산술을 구할 수 있을까요? 골든 파이낸스,패션은 순환이며 웹 3.0도 마찬가지입니다.
 JinseFinance
JinseFinance

저자 |: Frank-Zhang.eth, Twitter : @dvzhangtz
저자는 인공지능 자체가 새로운 유형의 생산성을 대표하며 인류 발전의 핵심이라고 믿습니다. center">
저자는 인공지능 자체가 새로운 유형의 생산성을 나타내며 인류 발전의 방향이라고 믿으며, Web3와 A의 결합은 Web3는 새로운 시대의 새로운 유형의 생산 관계가 될 것이며, 미래 인류 사회를 조직하고 AI 거인의 절대 독점 형성을 피하는 구원의 길이 될 것입니다.
웹3.0 일선 투자에서 장기적으로 싸우고 전직 AI 연구원이자 트랙 매핑을 작성하기 위해 형제는 자신이 의무가 있다고 믿습니다.

A를 더 완벽하게 이해하려면 다음을 알아야 합니다.
1. A의 기본 개념: 머신러닝이란 무엇인가, 왜 우리는 대규모 언어 모델이 필요합니다.
2. 데이터 수집, 모델 사전 학습, 모델 미세 조정, 모델 사용 등 AI 개발의 단계와 수행 중인 작업.
3. 외부 지식 기반, 연합 학습, ZKML, FHEML, 프롬프트 학습, 능력 뉴런 등 새롭게 떠오르는 방향.
4. A-체인에서 Web3에 해당하는 프로젝트는 무엇인가요?
5. 전체 AI 체인에서 어떤 링크가 더 가치가 있거나 대형 프로젝트에 해당되는 경향이 있나요?
이러한 개념을 설명할 때 저자는 공식이나 정의를 사용하지 않고 비유를 사용하여 설명하려고 노력합니다.
이 글은 가능한 한 많은 새로운 용어를 다루고 있으며, 저자는 독자의 마음에 인상을 남겨 나중에 이 글을 접하게 되면 다시 돌아와서 지식 구조에서 해당 용어가 어디에 있는지 확인할 수 있기를 희망합니다.
1부
오늘날 우리에게 익숙한 웹3+AI 프로젝트는 인공지능의 기계 학습에서 신경망이라는 개념에 속하는 기술입니다.
다음 단락에서는 인공지능, 머신러닝, 신경망, 훈련, 손실 함수, 경사 하강, 강화 학습, 전문가 시스템 등 몇 가지 기본 개념에 대해 정의합니다.
2부
인공지능
정의: 인공 지능이란 인간 정신의 능력을 시뮬레이션하고 확장, 확장할 수 있는 기술을 연구하고 개발하는 것입니다. 인공지능은 인간의 지능을 시뮬레이션하고, 확장하고, 확장할 수 있는 이론, 방법, 기술 및 응용 시스템을 개발하는 새로운 기술 과학입니다. 인공지능 연구의 목적은 듣고, 보고, 말하고, 생각하고, 배우고, 행동할 수 있는 지능적인 기계를 개발하는 것입니다
내 정의: 인간과 동일한 결과를 내기 때문에 무엇이 참이고 거짓인지 구분하기 어려운 기계(튜링 테스트)
파트 3
전문가 시스템
명확한 단계가 있는 경우 사용할 수 있는 지식: 전문가 시스템

4부
방법을 설명하기 어려운 경우 :
할 수 없다면 해야 합니다. align: left;">1. 주석이 달린 데이터 보유:머신 러닝, 예: 텍스트의 감정 분석
예시:학습 데이터 필요
키 메이커가 저에게 물었습니다." 당신은 일치합니까?"-중립
옆집의 매우 강한 왕이 나에게 물었다."당신은 일치합니까?"-부정
2. 거의 레이블이 없는 데이터: 강화 학습, 예: 체스

신경망이 기계에 무언가를 가르치는 방법
머신러닝은 오늘날 광범위한 지식과 범위를 다루고 있으며, 여기서는 단지 가장 고전적인 머신러닝인 신경망에 대해서만 설명하겠습니다.
신경망은 어떻게 기계에 무언가를 가르칠까요? 우리에게 비유할 수 있습니다.
강아지에게 매트 위에서 오줌 누는 법을 가르치고 싶다면(고전적인 예, 나쁜 지적은 없음) - (기계에 지식을 가르치고 싶다면)
방법 1: 개가 매트에 오줌을 싸면 고기 조각으로 보상하고, 안 싸면 회초리
방법 2: 개가 매트에 오줌을 싸면 고기 조각으로 보상하고, 안 싸면 회초리; 매트에서 멀리 떨어질수록 더 세게 회초리(손실 함수 계산)
방법 3: 개가 걸을 때마다 판단을 내립니다 :
매트 쪽으로 오줌을 싸면 고기 한 조각을 보상하고, 그렇지 않으면 매를 때립니다
(모든 훈련 세션, 손실 함수가 계산됨)
방법 4: 개가 걸을 때마다 판단을 내립니다
매트를 향해 있으면 고기 한 조각을 보상하고 그렇지 않으면 매를 때립니다
개에게 처음으로 훈련하는 것이므로 개가 훈련받는 데 좋은 방법입니다. "text-align: left;">걷기, 때리기
그리고 가리키는 매트 방향으로 고기 조각을 주어 개가 매트를 향해 걷도록 유도
(손실 계산하기 함수를 계산한 다음 손실 함수를 가장 잘 줄이는 방향으로 경사 하강을 수행합니다)

제6부
지난 10년 동안 신경망이 급증한 이유는 무엇일까요?
지난 10년 동안 인간의 능력, 데이터, 알고리즘이 폭발적으로 증가했기 때문입니다.
계산 능력: 신경망은 사실 지난 세기에 제안되었지만 당시에는 이를 실행하기 위한 하드웨어가 너무 오래 걸렸습니다. 하지만 금세기 들어 칩 기술이 발전하면서 컴퓨터 칩의 연산 능력은 18개월에 두 배씩 증가했습니다. 심지어 병렬 컴퓨팅에 특화된 GPU와 같은 칩도 등장하여 컴퓨팅 시간 측면에서 신경망을 "수용 가능한" 수준으로 만들었습니다.
데이터: 소셜 미디어, 인터넷, 인터넷에 축적된 방대한 양의 학습 데이터도 대기업의 자동화 요구와 관련이 있습니다.
모델: 컴퓨팅 성능과 데이터를 통해 연구자들은 보다 효율적이고 정확한 다양한 모델을 개발했습니다.
계산, 데이터, 모델은 인공 지능의 세 가지 요소라고도 합니다.
제7부
대규모 언어 모델(LLM)과 이것이 중요한 이유
왜 중요한가
왜 신경 써야 하는가? ">관심해야 하는 이유: 사람들이 Al+ web3에 대해 궁금해하기 때문에 오늘 이 자리에 모였고, ChatGPT 때문에 A가 뜨거워졌으며, ChatGPT는 대규모 언어 모델의 일부입니다.
왜 빅 언어 모델인가: 앞서 말했듯이 머신 러닝에는 학습 데이터가 필요하지만 대규모 데이터 주석은 너무 비싸며, 빅 언어 모델은 이 문제를 현명한 방법으로 해결합니다.

Part8
Bert - 최초의 빅 언어 모델
학습 데이터가 없으면 어떻게 할까요? 사람의 문장은 그 자체로 하나의 주석입니다. 완성주의 방법을 사용하여 데이터를 생성할 수 있습니다.
문단 중간을 파고 몇 개의 단어를 퍼낸 다음, 트랜스포머 아키텍처의 모델이 그 자리에 어떤 단어를 채워야 하는지 예측하도록 할 수 있습니다(그리고 개가 패드를 찾도록 할 수 있습니다).
모델이 모델이 잘못 예측하면 손실 함수, 경사 하강(개가 매트를 향해 걸어가면 고기 조각을 보상으로 주고, 그렇지 않으면 매트를 가리키는 방향으로 포즈를 취하도록 고기 조각을 주어 개가 매트 쪽으로 걸어가도록 유도)
인터넷의 모든 텍스트 구절이 훈련 데이터가 될 수 있도록 합니다.
사전 훈련에 대한 이해: 사전 훈련을 통해 기계는 말뭉치에서 인간에게 공통적인 것을 학습하고 '언어 감각'을 개발할 수 있습니다.

제9부
빅 언어 모델에 대한 후속 조치
Bert의 제안 이후, 모두가 이 방법이 효과가 있다는 것을 깨달았습니다!
모델을 더 크게 만들고, 훈련 데이터를 더 크게 만들면 결과는 점점 더 좋아집니다. 무턱대고 서두르는 것이 아닙니다.
학습 데이터 급증: Bert는 모든 위키백과와 도서 데이터를 학습에 사용한 다음, 웹의 영어 데이터로 확장하고 웹의 모든 언어로
모델 파라미터 수 급증
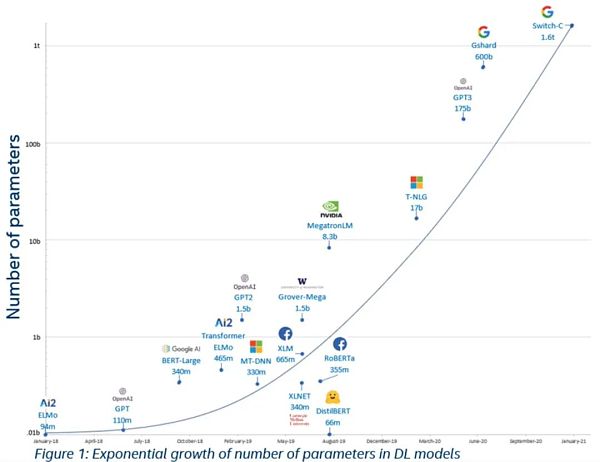
1부
학습 전 데이터 수집
(이 단계는 보통 대기업/연구소에서만 수행) 사전 학습에는 일반적으로 방대한 양의 데이터가 필요하며, 전체 네트워크의 모든 종류의 웹 페이지를 크롤링하여 테라바이트 단위로 데이터를 축적하고 전처리해야 합니다
모델 사전 학습(이 단계는 보통 대기업/연구소에서만 수행)
. 이 단계는 대기업/연구기관에서만 수행) 데이터 수집 완료 후 대량의 컴퓨팅 파워를 동원해야 하며, 사전 학습을 위해 수백 개의 A100/TPU급 컴퓨팅 파워가 필요합니다
2부
모델의 두 번째 사전 학습
(옵션) 사전 학습을 통해 기계가 인간에게 공통적인 것을 말뭉치에서 학습하고 '언어 감각'을 개발할 수 있지만, 모델에 특정 도메인에 대한 지식을 더 제공하려는 경우 다음과 같이 할 수 있습니다. 그러나 모델에 특정 도메인에 대한 더 많은 지식을 제공하려면 해당 도메인에서 말뭉치를 가져와 두 번째 사전 학습 세션을 위해 모델에 제공할 수 있습니다.
예를 들어 케이터링 및 테이크아웃 플랫폼인 Meituan은 케이터링과 테이크아웃에 대해 더 많이 알고 있어야 하는 큰 모델이 필요합니다. 그래서 메이퇀은 2차 사전 학습을 위해 메이퇀 디안핑 비즈니스 코퍼스를 가져와 MT-Bert를 개발했습니다. 이렇게 얻은 모델은 관련 현장에서 더 나은 결과를 가져왔습니다.
2차 사전 학습에 대한 나의 이해: 2차 사전 학습을 통해 모델이 특정 장면의 전문가가 될 수 있도록
제3부
모델 미세 조정 훈련
(옵션)모델 사전 훈련감정 분류, 주제 추출, 독해와 같은 특정 작업에 대한 전문가가 되고 싶다면 작업의 데이터를 사용하여 수행 할 수 있습니다. 미세 조정할 수 있습니다.
하지만 여기서는 데이터에 주석을 달아야 합니다. 예를 들어 감정 분류 데이터가 필요한 경우 다음과 유사한 데이터가 필요합니다.
키 커팅의 대가가 저에게 물었습니다."일치합니까? "중립
옆집의 매우 강한 왕이 나에게 물었다: "당신은 일치합니까?" 부정
내
나의 2차 사전 훈련에 대한 나의 이해: 미세 조정을 통해 모델을 주어진 작업의 전문가로
모델을 훈련하려면 그래픽 카드 간에 많은 양의 데이터를 전송해야 한다는 점에 유의해야 합니다. 현재 Al+ web3에서 진행 중인 프로젝트의 큰 범주 중 하나는 전 세계 사람들이 자신의 유휴 컴퓨터를 특정 작업에 기여하는 분산 연산입니다. 하지만 이런 종류의 산술로 완전한 분산 사전 훈련을 하는 것은 매우 어렵고, 분산 미세 조정 훈련을 하려면 매우 영리한 설계가 필요합니다. 그래픽 카드 간에 정보를 전송하는 데 걸리는 시간이 계산하는 시간보다 더 길어지기 때문입니다.
4부
모델 훈련에는 그래픽 카드 간에 많은 데이터 전송이 필요하다는 점에 유의하세요. 현재 Al+web3에서 진행 중인 주요 프로젝트 유형 중 하나는 전 세계 사람들이 자신의 유휴 컴퓨터를 기여하여 무언가를 수행하는 분산 연산(Distributed Arithmetic)입니다. 하지만 이런 종류의 산술로 완전한 분산 사전 훈련을 하는 것은 매우 어렵고, 분산 미세 조정 훈련을 하려면 매우 영리한 설계가 필요합니다. 그래픽 카드 간에 정보를 전송하는 데 걸리는 시간이 계산하는 시간보다 더 길어지기 때문입니다.
제 5부
모델 사용법
모델 사용법, 모델이라고도 알려진 모델 추론이라고도 합니다. 모델이 학습을 완료한 후 한 번 사용되는 프로세스를 말합니다.
모델 추론은 훈련에 비해 그래픽 카드가 많은 양의 데이터를 전송할 필요가 없으므로 분산 추론은 비교적 쉽게 수행할 수 있습니다.
1부 왼쪽;">방법: 대량의 PDF 데이터를 벡터 데이터베이스에 패킹하고 이를 입력으로 배경 정보로 활용
예시: Baidu Cloud, Myshell
프롬프트 학습
이유: 외부 지식 기반이 모델의 사용자 지정 요구 사항을 충족하기에 충분하지 않다고 생각하지만 전체 모델에 매개 변수화 학습에 대한 부담을 주고 싶지 않음
방법: 모델을 학습시키지 않고 학습 데이터만 사용합니다. 학습 데이터만 사용하여 어떤 종류의 프롬프트를 작성할지 학습
예시: 오늘날 널리 사용되는 방법
2부
모델 학습에 가장 일반적인 방법입니다.
연합 학습(FL)
출현 이유: 학습 모델을 사용할 때 개인 정보가 노출되는 자체 데이터를 제공해야 하는데 일부 금융 및 의료 기관에서는 이를 허용할 수 없음
출현 이유: 학습 모델을 사용할 때 개인 정보가 노출되는 자체 데이터를 제공해야 하는데 일부 금융 및 의료 기관에서는 이를 허용할 수 없음. 허용할 수 없음
방법론: 각 기관이 로컬에서 데이터를 사용하여 모델을 학습시킨 다음, 모델 융합을 위해 모델을 한곳에 모아
예시: Flock
FHEML
출현 이유: 연합 학습은 각 참가자가 로컬에서 모델을 훈련해야 하지만 이는 각 참가자에게 너무 높은 임계치
방법론: 사용 FHE는 완전 동형 암호화를 의미하며, 암호화된 데이터로 모델을 직접 훈련할 수 있음
단점: 매우 느리고 비용이 많이 듦
사례: ZAMA, Privasea
제3부
ZKML
이유:다른 사람이 제공하는 모델링 서비스를 사용할 때 우리는 다음을 수행합니다. 작은 모델을 사용하여 엉뚱한 작업을 하는 것이 아니라 실제로 우리가 원하는 모델링 서비스를 제공하고 있는지 확인하고 싶습니다
방법:ZKML을 사용하여 그들이 주장하는 작업을 실제로 수행하고 있다는 증명을 생성하도록 합니다
. 단점: 느리고 비싸
사례: 모듈러스
스킬뉴런
이유: 오늘날의 모델은 블랙박스와 같아서 많은 학습 데이터를 제공하지만 실제로 무엇을 학습하는지 알 수 없습니다. 모델이 특정 방향으로 최적화할 수 있는 방법(예: 더 강한 감정 인식, 더 높은 도덕성 등)을 원합니다
방법: 모델은 마치 뇌, 뉴런의 일부 영역은 감정을 관리하고 일부 영역은 도덕성을 관리하며 이러한 노드를 찾아내면 최적화를 목표로 할 수 있습니다
사례:향후 방향
제1부
저자는 다음과 같이 나뉩니다. 세 가지 카테고리 :
인프라: 탈중앙화를 위한 인프라
미들웨어: 인프라가 애플리케이션 레이어에 더 나은 서비스를 제공할 수 있도록 지원
애플리케이션 레이어: 인프라가 애플리케이션 레이어에 더 나은 서비스를 제공할 수 있도록 지원
앱플리케이션 레이어
">인프라. ">애플리케이션 레이어: C-엔드/B-엔드를 직접 마주하는 일부 애플리케이션
2부
인프라 계층: AI의 인프라는 항상 데이터 파워, 알고리즘(모델), 데이터 처리 파워의 세 가지 주요 범주에 속합니다. 알고리즘(모델)
분산형 알고리즘(모델):
@TheBittensorHub Research:x.com/dvzhangtz/stat... @flock_ io
탈중앙화 산술:
일반 목적 산술: @akashnet_, @ionet
전용 연산: @rendernetwork(렌더링), @gensynai(AI), @heuris_ai(Al) @exa_bits(A) (AD,
탈중앙화 데이터:
데이터 어노테이션:@PublciAl_,QuestLab
스토리지:IPFS, FIL
Oracle: Chainlink
Index:그래프
3부
미들웨어:제작 방법
미들웨어:제작 방법 인프라는 애플리케이션 레이어에 더 나은 서비스를 제공할 수 있습니다
개인정보 보호: @zama fhe, @Privasea_ai
인증: EZKL, @ModulusLabs , @...
인증. gizatechxyz
애플리케이션 계층: 애플리케이션은 사실 모두 분류하기 매우 어렵고, 가장 대표적인 몇 가지만 나열할 수 있습니다
데이터 분석
@_kaitoai,@DuneAnalytics ,Adot
Agent
Market: @myshell_ai
Web3 지식 챗봇:@qnaweb3
작업 지원:@autonolas
우선 다른 분야와 마찬가지로 인프라는 대형 프로젝트, 특히 한계 비용이 낮은 탈중앙화 모델, 탈중앙화 산술에 취약한 경향이 있습니다.
그런 다음, @owenliang60으로부터 영감을 받아 애플리케이션 계층도 킬러 애플리케이션이 있다면 최고의 프로젝트가 될 수 있을 것이라고 생각합니다.
대형 모델의 역사를 되돌아보면, 폐쇄 물결의 끝으로 밀어붙인 킬러 앱은 ChatGPT였으며, 이는 기술의 큰 반복이 아니라 채팅이라는 작업에 최적화되어 있었습니다. 앞으로 A+Web3 영역에서도 Stepn/Friendtech와 같은 경이로운 애플리케이션이 등장할지 지켜볼 일입니다.
웹 3.0,인공지능,산술,GTC 컨퍼런스 이후 작성된 글 웹3.0이 인공지능 산술을 구할 수 있을까요? 골든 파이낸스,패션은 순환이며 웹 3.0도 마찬가지입니다.
JinseFinance출시 100일 후, 셀레스티아의 창립자가 셀레스티아의 등장이 앱과 개발자에게 어떤 변화를 가져왔는지 되돌아봅니다.
JinseFinance비트코인, ETF, 10년 만에 탄생 미국 비트코인 현물 ETF 골드 파이낸스의 승인으로 비트코인은 공식적으로 글로벌 금융 시스템에 연결될 예정입니다.
JinseFinanceJinseFinanceJinseFinanceJinseFinance近期是高校学生提交课程论文、进行毕业论文答辩和审核的高峰期。记者调查发现,部分高校学生在悄悄利用ChatGPT等AI(人工智能)写作软件代写论文,或者用AI辅助论文写作,如罗列提纲、润色语言、降低重复率等。 AI写作软件是否会助长学术造假?该不该管?
 8btc
8btc이 앱은 Z세대를 염두에 두고 설계되었으며 플랫폼 외부 전송 금지를 비롯한 다양한 안전 기능을 포함합니다.
 Beincrypto
Beincrypto아침에 저는 ETH Shanghai에서 V God의 라이브 방송을 보았고, 여러분과 새로운 통찰력을 공유하고 싶습니다.
 链向资讯
链向资讯나는 여전히 DAO를 매우 사랑하고 당신과 함께 성장하는 남은 인생을 보낼 것입니다. 그러나 지금은 집이라고 부르는 DAO에 더 집중할 것입니다.
 Ftftx
Ftftx