ArweaveとIPFSのデータ冗長性の比較
この記事では、ArweaveとIPFSの冗長性メカニズム、そしてどちらのオプションがデータにとってより安全かを見ていきます。
 JinseFinance
JinseFinance

私たちは、AIとWeb3が、コンピュート・ネットワーク、エージェント・プラットフォーム、コンシューマー・アプリケーションなどの垂直的な分野にわたって、それぞれの強みをどのように生かすことができるかについて議論してきました。互いに補完し合う。データリソースの垂直統合に注目すると、Web Emergenceは、データへのアクセス、共有、活用のための新しい可能性を提供するプロジェクトを表しています。
従来のデータプロバイダーは、AIやその他のデータ駆動型産業において、高品質でリアルタイムの検証可能なデータの需要を満たすのに苦労しています。
Web3ソリューションは、データエコシステムの再構築に取り組んでいます。MPC、Zero Knowledge Proof、TLS Notaryなどのテクノロジーは、データが複数のソースにまたがって流れる際に、真正性とプライバシーの保護を保証し、分散ストレージとエッジコンピューティングは、リアルタイムのデータ処理に柔軟性と効率性を提供します。
分散型データネットワークの新たなインフラストラクチャは、OpenLayer(モジュール式の実世界データ層)、Grass(モジュール式の実世界データネットワーク)、Grid(モジュール式の実世界データネットワーク)といった象徴的なプロジェクトを生み出しました。データレイヤー)、Grass(ユーザーのアイドル帯域幅と分散化を利用するクローラーノードのネットワーク)、Vana(ユーザーデータ主権のためのレイヤー1ネットワーク)などがあり、AIのトレーニングや異なる技術的経路を持つアプリケーションなどの分野で新たな展望を開いている。
クラウドソーシングされた容量、信頼性のない抽象化レイヤー、トークン・ベースのインセンティブにより、分散型データ・インフラは、Web2のハイパースケールよりもプライベートで、安全で、効率的かつ経済的なソリューションを提供することができます。Web2のハイパースケーラーよりも経済的なソリューションを提供し、ユーザーが自分のデータとその関連リソースをコントロールできるようにすることで、よりオープンでセキュアで相互運用可能なデジタルエコシステムを構築することができます。
1.UBSの予測によると、世界のデータ量は2020年から2030年の間に10倍以上の660 ZBに成長し、2025年には世界で1人1日あたり463EB(エクサバイト、1EB=10億GB)のデータが生成されるという。Grand View Research社のレポートによると、DaaS(Data-as-a-Service)市場は急速に拡大しており、2023年の世界DaaS市場規模は143億6000万ドル、2030年までの年平均成長率は28.1%で、最終的には768億ドルに達すると予測されている。このような高成長の背景には、複数の産業部門にわたって、高品質でリアルタイムの信頼できるデータが求められていることがあります。
AIモデルのトレーニングは、パターンを認識し、パラメータを調整するための多数のデータ入力に依存しています。また、モデルの性能と汎化能力をテストするために、トレーニング後のデータセットも必要です。さらに、AIエージェントは、新たなインテリジェンス・アプリケーションの予見可能な将来の形態として、正確な意思決定とタスクの実行を保証するために、リアルタイムの信頼できるデータソースを必要とします。
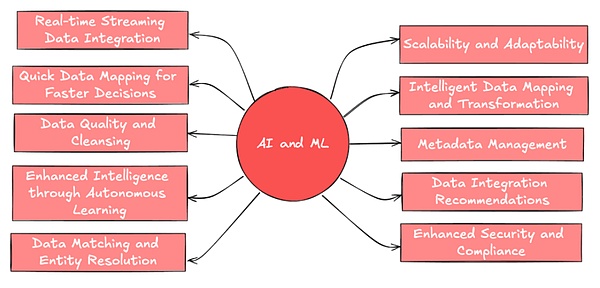
(英語)。出典:Leewayhertz)
ビジネスアナリティクスのニーズも多様化・広範化しており、組織のイノベーションを推進する中核ツールとなっている。例えば、ソーシャルメディアプラットフォームや市場調査会社は、戦略を策定し、トレンドに対する洞察を得るために、また、より包括的なイメージを構築するために、複数のソーシャルプラットフォームからの複数のデータセットを統合するために、信頼できるユーザー行動データを必要としています。
ウェブ3のエコシステムにとって、チェーンはまた、新しい金融商品をサポートするために、信頼できる本物のデータを必要としています。パススルーされる新しいタイプの資産が増えるにつれ、革新的な商品開発とリスク管理をサポートし、検証可能なリアルタイムのデータに基づいてスマートコントラクトを実行できるようにする、柔軟で信頼性の高いデータインターフェースが必要とされています。
上記以外にも、研究、モノのインターネット(IoT)などがあります。新しいユースケースは、業界全体で多様で実世界のリアルタイムデータに対する需要の急増を表面化しており、レガシーシステムは急速に増大するデータ量とニーズの変化に対応するのに苦労するかもしれません。
2. Limitations and problems of traditional data ecosystems
典型的なデータエコシステムには、データの収集、保存、処理、分析、応用が含まれる。集中型モデルの特徴は、データが一元的に収集・保存され、中核となる企業のITチームによって管理・維持され、厳格なアクセス制御が行われることです。
たとえば、グーグルのデータエコシステムは、検索エンジン、Gmail、Androidオペレーティングシステムなどからの複数のデータソースを包含しています。
例えば金融市場では、データおよびインフラストラクチャー企業であるLSEG(旧Refinitiv)が、グローバルな取引所、銀行、その他の主要金融機関からのリアルタイムおよび過去のデータと、独自のロイター・ニュース・ネットワークを使用して、市場関連のニュースを収集しています。
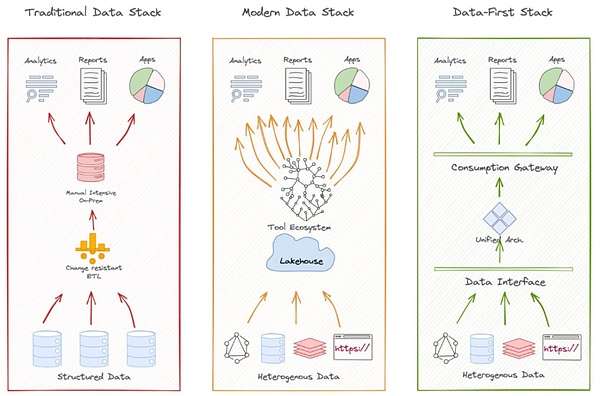
(出典:kdnuggets.com)
従来のデータアーキテクチャはプロフェッショナルサービスにとって効果的でしたが、集中型モデルの限界がますます明らかになってきています。特に、従来のデータ・エコシステムは、新たなデータ・ソースの網羅性、透明性、ユーザーのプライバシー保護という課題に直面しています。
Inadequate data coverage: 伝統的なデータ。プロバイダーは、ソーシャルメディアのセンチメントやIoTデバイスのデータなど、新たなデータソースを迅速に取り込み、分析することに課題を抱えています。集中型システムは、多数の小規模または非主流ソースからの「ロングテール」データを効率的に取り込み、統合するのに苦労しています。
例えば、2021年のGameStopのイベントでは、ソーシャルメディアのセンチメントを分析する際の従来の金融データプロバイダーの限界が明らかになりました。ブルームバーグやロイターは、こうした動きをタイムリーに捉えることができず、市場予測に遅れをとることになりました。
Constrained data accessibility: 独占はアクセシビリティを制限する。多くの伝統的なプロバイダーは、API/クラウドサービスを通じてデータの一部をオープンにしていますが、高いアクセス料と複雑な認証プロセスが、依然としてデータ統合を困難にしています。
オンチェーン開発者が信頼できるオフチェーンデータに素早くアクセスすることは難しく、高品質なデータは少数の大企業に独占されており、アクセスコストは高い。
データの透明性と信頼性の問題:中央集権的なデータ提供者の多くは、データの収集と処理方法について透明性を欠き、効果的なメカニズムがありません。大規模データの真正性と完全性を検証する効果的なメカニズムがない。大規模なリアルタイムデータの検証は依然として複雑な問題であり、中央集権という性質そのものが、データの改ざんや操作のリスクを高めています。
Privacy and Data Ownership: 大手ハイテク企業は、ユーザーデータを大規模に商業化しています。個人データの作成者であるユーザーは、見返りにふさわしい価値を得るのに苦労しています。自分のデータがどのように収集され、処理され、使用されているのか、利用者は知る術を持たないことが多く、データの使用場所や使用方法を決定することも難しい。過剰な収集と使用は、深刻なプライバシーリスクにもつながる。
例えば、フェイスブックのケンブリッジ・アナリティカの騒動は、従来のデータプロバイダーがデータ利用の透明性とプライバシー保護においていかに大きな隔たりがあるかを露呈した。
データのサイロ化:さらに、異なるソースやフォーマットのリアルタイムデータを迅速に統合することは難しく、包括的な分析の可能性に影響を与えています。多くのデータは組織内に閉じ込められていることが多く、業界や組織を超えたデータ共有やイノベーションが制限され、データのサイロ効果が領域を超えたデータ統合や分析を妨げています。
たとえば、消費者業界では、ブランドはeコマースプラットフォーム、実店舗、ソーシャルメディア、市場調査からのデータを統合する必要がありますが、これらは一貫性のない、あるいは分離されたプラットフォーム形式のために統合が難しい場合があります。別の例としては、UberやLyftのようなシェアードモビリティ企業が挙げられます。両社は、交通、ライダーのニーズ、地理的な位置に関する大量のリアルタイムデータをユーザーから収集していますが、これらのデータは競争のため、統合のために提示したり共有したりすることはできません。
それに加えて、コスト効率と柔軟性の問題もあります。従来のデータベンダーはこれらの課題に積極的に取り組んでいますが、Web3テクノロジーの出現は、これらの問題を解決するための新しいアイデアと可能性を提供してくれます。
2014年以来。2014年にIPFS(InterPlanetary File System)のような分散型ストレージ・ソリューションがリリースされて以来、業界では従来のデータ・エコシステムの限界に対処することに特化した一連の新興プロジェクトが見られるようになりました。私たちは、分散型データソリューションが、データの生成、保存、交換、処理と分析、認証とセキュリティ、プライバシーと所有権など、データライフサイクルのすべてのフェーズを包含する、多層で相互接続されたエコシステムを形成するのを見てきました。
データ・ストレージ: ファイルコインとArweaveの急成長は、分散型ストレージ(DCS)がストレージのパラダイムシフトとして台頭している証拠です。DCSソリューションは、分散アーキテクチャによって単一障害点のリスクを低減する一方、より競争力のある費用対効果で参加者を惹きつけています。DCSのストレージ容量は、一連のスケーリングされたユースケースによって爆発的に増加しています(例えば、Filecoinネットワークの総ストレージ容量は、2024年に22エクサバイトに達しました)。
処理と分析:Fluenceのような分散型データ・コンピューティング・プラットフォームは、エッジ・コンピューティング(Edge Computing)技術を通じて、データ処理のリアルタイム性と効率性を向上させます。これは、モノのインターネット(IoT)やAIの推論など、高いリアルタイム性が要求されるアプリケーション・シナリオに特に適しています。Web3プロジェクトは、連携学習、差分プライバシー、信頼された実行環境、完全同型暗号化を活用して、計算機レベルで以下を提供します。柔軟なプライバシー保護とトレードオフを提供します。
Data Marketplace/Exchange Platform: データの価値の定量化とその流通を促進するため、オーシャンプロトコルはトークン化とDEXメカニズムを通じて、効率的で効果的なデータ市場と交換プラットフォームを構築します。DEXメカニズムにより、オーシャン・プロトコルは効率的でオープンなデータ交換チャネルを構築し、例えば、伝統的な製造企業(メルセデス・ベンツの親会社であるダイムラー)が、サプライチェーン・マネジメントにおけるデータ共有を促進するために、データ交換マーケットプレイスの開発で協力することを支援している。一方、Streamr社は、IoTやリアルタイム分析シナリオのためのライセンスフリー、サブスクリプションベースのデータストリーミングネットワークを構築しており、輸送や物流プロジェクト(フィンランドのスマートシティプロジェクトなど)において大きな可能性を示している。
データの交換と活用が進むにつれ、データの真正性、信頼性、プライバシー保護は無視できない重要な課題となっています。このため、Web3のエコシステムはデータ検証とプライバシー保護にイノベーションを拡大し、一連の画期的なソリューションを生み出しました。
多くのWeb3テクノロジーとネイティブプロジェクトは、データの真正性とプライベートデータ保護に取り組んでいます。データの真正性と個人データ保護の問題に取り組んでいます。ZKに加えて、MPCのような技術開発は広く使用されており、トランスポート・レイヤー・セキュリティ・プロトコル・ノータリー(TLS Notary)は、新たな認証方法として特に注目されています。
TLS公証の紹介
トランスポート・レイヤー・セキュリティ(TLS)は、ネットワーク通信の暗号化プロトコルとして広く使われています。クライアントとサーバー間のデータ転送の安全性、完全性、機密性を保証するために設計されています。これは、最新のウェブ通信における一般的な暗号化規格であり、HTTPS、電子メール、インスタントメッセージなど、多くのシナリオで使用されています。
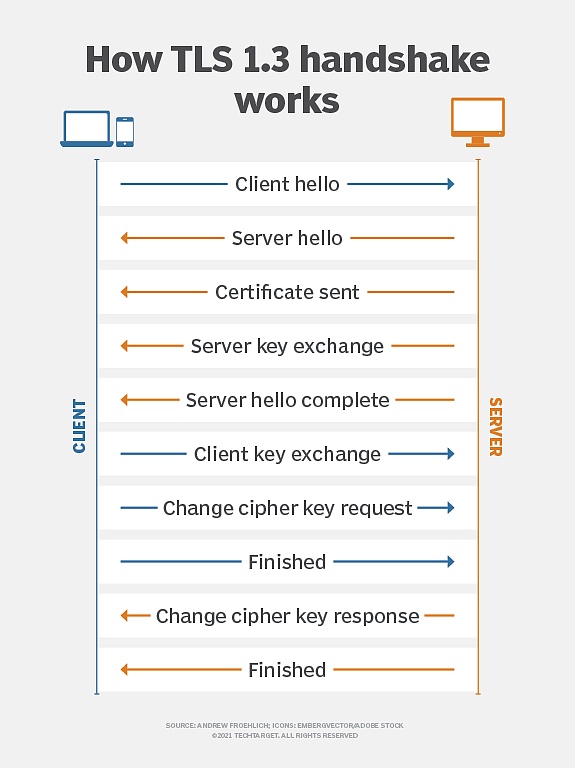
(TLS Encryption Principles, Source: TechTarget)
10年前に誕生したTLS Notaryの当初の目的は、クライアント(Prover)、サーバーの外部にサードパーティの "公証人 "を導入することで、サービスの品質を向上させることでした。"公証人 "がTLSセッションの真正性を検証する。
キースプリッティング技術を使って、TLSセッションのマスターキーは、クライアントと公証人が持つ2つの部分に分割されます。この設計により、公証人は信頼できるサードパーティとして認証プロセスに参加できるが、実際の通信コンテンツにはアクセスできない。この公証人メカニズムは、中間者攻撃を検出し、不正な証明書を防止し、通信データが転送中に改ざんされていないことを保証し、通信のプライバシーを保護しながら、信頼できる第三者が通信の正当性を確認できるように設計されています。
その結果、TLS Notaryは安全なデータ検証を提供し、認証とプライバシー保護の必要性のバランスを効果的にとります。
2022年、イーサネット財団のPSE(Privacy and Scaling Exploration)研究室によって、TLS Notaryプロジェクトが再構築されました。新バージョンのTLS NotaryプロトコルはRustで一から書き直され、MPCなどのより高度な暗号プロトコルが組み込まれ、ユーザーがサーバーから受信したデータの真正性を、データの内容を明かすことなく第三者に証明できる新しいプロトコル機能が追加された。オリジナルのTLS Notaryの中核となる認証機能を維持しながら、プライバシー保護機能は劇的に改善され、現在および将来のデータプライバシーのニーズにより適しています。
TLS Notaryテクノロジーは近年進化し続けています。
ZkTLS Notary Technology
ZkTLS Notary TechnologyzkTLS:プライバシーを強化したバージョンのTLS Notaryで、ZKP技術を組み込み、機密情報を公開せずにウェブデータの暗号化証明を生成できるようにします。非常に高度なプライバシー保護を必要とする通信シナリオに適しています。
3P-TLS (Three-Party TLS):クライアント、サーバー、監査人に対する3者間アプローチを導入し、通信内容を明らかにすることなく監査を可能にします。通信の内容を明らかにすることなく監査を可能にし、監査人が通信のセキュリティを検証できるようにする。このプロトコルは、コンプライアンス・レビューや金融取引の監査など、透明性は必要だがプライバシー保護も必要な場面で有用です。
Web3プロジェクトはこれらの暗号化技術を使用して、データ認証とプライバシー保護を強化し、データの独占を打破し、データのサイロ化と信頼できる転送に対処し、ユーザーがプライバシーを損なうことなく、ソーシャルメディアアカウントの所有権、金融融資のための購入履歴、銀行の信用履歴、職業履歴などを証明できるようにします。
Reclaimは、zkTLS技術を使用しています。プロトコルは、zkTLS技術を使用してHTTPSトラフィックのゼロ知識証明を生成し、ユーザーが機密情報を公開することなく、外部のサイトからアクティビティ、レピュテーション、およびIDデータを安全にインポートできるようにします。
zkPassは3P-TLS技術を組み合わせて、ユーザーが実世界の個人データを開示せずに検証できるようにします。ネットワークに対応しています。
Opacity Networkは、zkTLSをベースにしているため、ユーザーはプラットフォーム(Uber、Spotify、Netflixなど)を横断して、それらのプラットフォームに直接アクセスすることなく、自分の活動を安全に証明することができます。これらのプラットフォームのAPIに直接アクセスすることなく、クロスプラットフォームでの活動証明を可能にします。
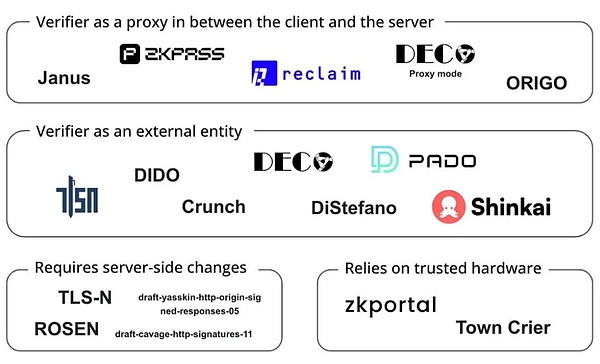
(TLSオラクルで活動するプロジェクト、出典:Bastian Wetzel)
Web3のデータ検証は、データエコシステムチェーンの重要なリンクとして、有望なアプリケーションを持っており、その生態学的なブームは、よりオープンでダイナミックでユーザー中心のデジタル経済につながっています。しかし、真正性検証技術の開発は、次世代データインフラ構築の始まりに過ぎません。
いくつかのプロジェクトは、上記のデータ検証技術を組み合わせています。上記のデータ検証技術は、データ・エコシステムの上流、すなわちデータのトレーサビリティ、分散データ収集、信頼された送信をより深く探求することと組み合わされている。以下の議論では、次世代データインフラを構築するためのユニークな可能性を示すいくつかの代表的なプロジェクト、OpenLayer、Grass、Vanaに焦点を当てます。
a16z Cryptoの2024年春のCrypto Startup Accelerator Programsの1つであるOpenLayerは、Web2とWeb3の両方の企業のニーズを満たす初のモジュラーリアルデータレイヤーとして、データの収集、検証、変換をオーケストレーションするための革新的なモジュラーソリューションを提供することに専念している。OpenLayerは、Geometry Ventures、LongHash Ventures、その他の大手ファンドやエンジェル投資家を含む多くの企業を惹きつけています。
従来のデータレイヤーは、信頼できる認証メカニズムの欠如、限られたアクセシビリティをもたらす集中型アーキテクチャへの依存、システム間のデータの相互運用性と可動性の欠如、データの価値を分配するための公正なメカニズムの欠如など、複数の課題に悩まされています。
より具体的な問題は、AIのトレーニングデータが今日ますます不足していることです。公共のインターネット上では、多くのサイトがクローラー対策規制によって、AI企業が大規模にデータをクロールできないようにし始めている。
private proprietary dataとなると状況はさらに複雑で、多くの貴重なデータが、その機密性の高さゆえにプライバシー保護された方法で保存され、効果的なインセンティブを欠いています。このような状態では、ユーザーはプライベートなデータを提供することから安全に直接的な利益を得ることができず、したがってこの機密データを共有することに消極的になります。
このような問題に対処するため、OpenLayerはデータ検証技術を組み合わせ、データ収集を組織化するための分散型+経済的インセンティブを備えたモジュール型オーセンティック・データ・レイヤーを構築します、データ収集、検証、変換プロセスを調整するための分散型+経済的インセンティブを持つ方法で認証および変換プロセスを構築し、Web2およびWeb3企業により安全で効率的かつ柔軟なデータインフラを提供します。
OpenLayerは、データ収集、検証、変換プロセスを調整するためのモジュラー・プラットフォームを提供します。OpenLayer はデータの収集、信頼できる検証、変換のプロセスを簡素化するモジュール式のプラットフォームを提供する。text-align: "left;">OpenNodesは分散型データ収集を担うOpenLayerエコシステムのコアコンポーネントで、ユーザーのモバイルアプリやブラウザ拡張機能、その他のチャネルを通じてデータを収集します。
OpenNodesは、さまざまなタイプのタスクのニーズを満たすために、3つの主要なデータタイプをサポートしています:
一般に公開されているインターネットデータ(例:金融データ、天気データ、スポーツデータ、ソーシャルメディアストリーム)
プライベートなユーザーデータ(例:Netflixの視聴履歴、Amazonの注文履歴など)
安全なソースからの自己報告データ(例:独自の所有者の署名によって検証されたデータや、特定の信頼できるハードウェアによって検証されたデータなど)。
開発者は新しいデータタイプを簡単に追加でき、新しいデータソース、要件、データ検索方法を指定でき、ユーザーは報酬と引き換えに非識別データを提供することを選択できます。この設計により、新しいデータ要件に対応するためにシステムを継続的に拡張することができ、データソースの多様性により、OpenLayerは様々なアプリケーションシナリオに包括的なデータサポートを提供し、データ提供の障壁を低くすることができます。
b) OpenValidators
OpenValidatorsは以下を担当します。データ収集後のデータ検証。データ利用者が、ユーザーが提供したデータがデータソースと完全に一致することを確認できるようにします。提供されるすべての検証方法は暗号的に証明することができ、検証結果は事後に検証することができる。同じタイプの証明は、多くの異なるプロバイダーから提供されている。開発者は、自分のニーズに最も適した検証プロバイダーを選ぶことができます。
初期のユースケースでは、特にインターネットAPIからの公開または非公開データに対して、OpenLayerはあらゆるウェブアプリケーションからデータをエクスポートし、プライバシーを損なうことなくその真正性を証明する検証ソリューションとしてTLSNotaryを使用します。プライバシーを損なうことなく真正性を証明します。
TLSNotaryに限らず、モジュール設計のおかげで、検証システムは他の検証方法を簡単にプラグインすることができ、さまざまなタイプのデータや検証要件に対応できます。paddingleft-2">
認証済みTLS接続:Trusted Execution Environment(TEE)を使用して認証済みTLS接続を確立し、転送中のデータの完全性と真正性を保証する。認証済みTLS接続:Trusted Execution Environment(TEE)を使用して認証済みTLS接続を確立し、転送中のデータの完全性と真正性を保証します。
セキュア・エンクレーブ:機密データの処理と検証にハードウェアレベルのセキュア・エンクレーブ(Intel SGXなど)を使用することで、より高度なデータ保護を提供します。
ZK Proof Generators: ZKP と統合することで、元のデータを明らかにすることなく、データの属性または計算の検証を可能にします。
c) OpenConnect
c) OpenConnect: OpenConnectはOpenConnectアプリケーションです。OpenConnectはOpenLayerエコシステムのコアモジュールで、ユーザビリティのためのデータ変換、様々なソースからのデータ処理、異なるアプリケーションのニーズを満たすための異なるシステム間の相互運用性の確保を担当します。例えば:
スマートコントラクトで直接使用するために、データをオンチェーンOracleフォーマットに変換します。
構造化されていない生データを、AIトレーニングなどの前処理のために構造化データに変換します。
ユーザーの個人アカウントから来るデータに対して、OpenConnectはプライバシーを保護するためのデータ非感覚化と、データ共有中のセキュリティを強化し、データの漏洩や悪用を減らすためのコンポーネントを提供します。AIやブロックチェーンなどのアプリケーションのためのリアルタイムデータの需要に応えるため、OpenConnectは効率的なリアルタイムデータ変換をサポートします。
現在、EigenLayerとの統合により、OpenLayer AVSオペレーターはデータ要求タスクを聞き、データのクロールと検証を担当し、その結果をシステムに報告し、EigenLayerを通じて資産を質入れまたは再質入れし、その経済的担保を提供します。EigenLayerはその振る舞いに経済的担保を提供するために、資産を質入れまたは再質入れする。悪意のある行動が確認された場合、差し入れた資産が没収されるリスクがある。EigenLayerメインネット上の最初のAVS(Active Verification Services)の1つとして、OpenLayerは50以上のオペレーターと40億ドルの再誓約資産を集めています。
全体として、OpenLayerは分散型データレイヤーを構築し、実用性と効率性を犠牲にすることなく、利用可能なデータの範囲と多様性を拡大するとともに、暗号技術と経済的インセンティブによってデータの真正性と完全性を確保しています。そのテクノロジーは、オフチェーン情報へのアクセスを求めるWeb3 Dapps、実際のインプットで学習・推論する必要のあるAIモデル、既存のアイデンティティや評判に基づいてユーザーをセグメント化し、ターゲットを絞ろうとする企業など、幅広い実用的なユースケースを持っている。また、ユーザーは自分のプライベートデータを価値化することもできる。
グラスは、ウィンド・ネットワークが開発した旗艦プロジェクトです。分散型ウェブクローラーとAIトレーニングデータプラットフォームを作るために開発されたネットワークの旗艦プロジェクト。2023年後半、GrassプロジェクトはPolychain CapitalとTribe Capitalが主導する350万ドルのシードラウンドをクローズした。その直後の2024年9月、プロジェクトはHackVCが主導する別のシリーズAラウンドの資金調達を行い、Polychain、Delphi、Lattice、Brevan Howardといった一流の投資組織が参加した。
私たちは、AIのトレーニングには新たなデータ露出が必要であり、データアクセスから抜け出してAIにデータを供給するために複数のIPを使用することが1つの解決策であると述べた。 Grassはそこから、検証可能なデータを収集し提供することに特化した分散クローラーノードネットワークは、ユーザーのアイドル帯域幅を利用して、AIトレーニング用の検証可能なデータセットを収集・提供する分散型物理インフラを構築することに着手した。ノードはユーザーのインターネット接続を通じてウェブリクエストをルーティングし、一般公開されているウェブサイトにアクセスし、構造化されたデータセットをコンパイルする。データ品質を向上させるために、最初のデータクレンジングとフォーマットにエッジコンピューティング技術を使用する。
Grassは、処理効率を向上させるためにSolanaの上に構築されたSolana Layer 2 Data Rollupアーキテクチャを採用し、バリデータを使用してノードからのウェブトランザクションを受信、検証、バッチ処理し、データの真正性を保証するZK証明書を生成します。はデータの真正性を保証する。検証されたデータは台帳(L2)に保存され、対応するL1のオンチェーン証明にリンクされる。
a) ;Grassノード
OpenNodesと同様に、C-suiteユーザーはGrassアプリまたはブラウザ拡張機能をインストールして実行し、アイドル帯域幅を利用してウェブクローラ操作を実行します。また、エッジコンピューティング技術を使って、最初のデータクレンジングとフォーマットのために構造化されたデータセットをコンパイルします。ユーザーは、貢献した帯域幅とデータ量に応じてGRASSトークンで報酬を得る。
b)ルーター
グラスノードとバリデーターを接続し、ノードネットワークと中継帯域幅を管理します。ルーターは運用にインセンティブが与えられ、経由して中継された認証帯域幅の合計に比例した報酬を受け取る。
c)バリデータ
ルーターからウェブトランザクションを受信、検証、バッチ処理し、ゼロ・パーセント(ZP)とゼロ・パーセント(ZP)を生成する。グラスは現在、集中型認証装置を使用しており、将来的には認証委員会に移行する予定です。
d)ZKプロセッサー
各ノードのセッションデータを生成する認証者から証明を受け取ります。ノードのセッションデータを生成する認証機能から証明を受け取り、すべてのウェブリクエストの有効性をバッチで証明し、レイヤー1(Solana)に送信します。
e) Grass Data Ledger (Grass L2)
完全なデータセットを保存し、対応するL1チェーン(Solana)にリンクします。対応するL1チェーン(Solana)にリンクします。
f)エッジ埋め込みモデル
非構造化ウェブデータを、構造化モデルでAIトレーニングに使えるように変換する役割を担います。構造化されたモデルに変換する役割を担っています。
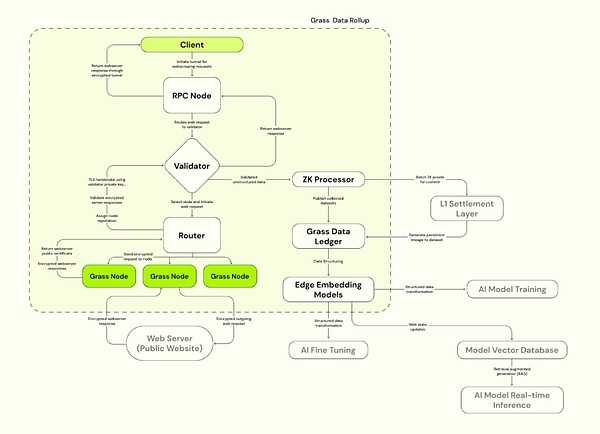
Source:Grass
GrassとOpenLayerは、どちらもOpenLayerを使用しています。OpenLayerとGrassはどちらも分散型ネットワークを使い、オープンなインターネットデータや認証を必要とするクローズドな情報へのアクセスを企業に提供します。データの共有と高品質なデータの作成は、インセンティブによって促進される。どちらもデータアクセスと認証の問題を解決する分散型データレイヤーを目指しているが、技術的な道筋やビジネスモデルは若干異なる。
技術アーキテクチャの違い
Grassは、現在中央集中型のデータレイヤーを使用しているSolanaのレイヤー2データロールアップアーキテクチャを使用しています。Solanaのロールアップアーキテクチャは、現在単一のバリデータを使用した集中型の検証メカニズムを採用している。Openlayerは最初のAVSの1つとしてEigenLayerをベースに構築されており、経済的インセンティブと没収メカニズムを用いて分散型検証メカニズムを実現している。また、データ検証サービスのスケーラビリティと柔軟性を重視したモジュール設計を採用しています。
製品の違い
両者とも、ユーザーがデータの価値を実現するためにノード化することを可能にする、同様のTo C製品を提供しています。をノード化することができます。To Bのユースケースに関しては、Grassは興味深いデータマーケットプレイスモデルを提供し、L2を使って完全なデータを検証可能に保存し、AI企業に構造化された高品質で検証可能なトレーニングセットを提供する。一方、OpenLayerは、一時的な専用データ・ストレージ・コンポーネントを持たないが、より広範なリアルタイム・データ・ストリーム検証サービス(Vaas)を提供しており、AIへのデータ提供に加え、RWA/DeFi/予測市場プロジェクトに価格を供給するオラクルとしての役割や、リアルタイムのソーシャル・データの提供など、迅速な対応を必要とするシナリオにも適している。
その結果、今日のGrassのターゲット顧客ベースは、主にAI企業やデータサイエンティストに向けられており、大規模で構造化されたトレーニングデータセットを提供し、大量のネットワークデータセットを必要とする研究機関や企業にもサービスを提供しています。Openlayerは一時的に、オンチェーン開発者向けのオフチェーンデータソース、リアルタイムの検証可能なデータストリームを必要とするAI企業、競合他社の利用履歴を検証するなどの革新的なユーザー獲得戦略をサポートするWeb2企業向けとなっています。
将来的な競合の可能性
しかし、業界の動向を考えると、2つのプロジェクトの機能が将来的に収束する可能性は十分にあります。Grassは近い将来、リアルタイムの構造化データも提供するかもしれない。OpenLayerはモジュラープラットフォームとして、将来的には独自のデータ台帳を持つデータセット管理へと拡大する可能性が高いため、両者の競争領域は徐々に重なっていくかもしれない。
また、両プロジェクトはデータのラベリングという重要な側面を追加することを検討するかもしれない。この利点により、グラスはAIモデルを最適化するために大量のラベル付けされたデータを使用する、人間のフィードバックに基づく強化学習(RLHF)サービスを提供できる可能性がある。
しかし、データ検証とリアルタイム処理の専門知識を持つOpenLayerは、プライベートデータに重点を置いているため、データの品質と信頼性において優位性を維持する可能性が高い。加えて、OpenLayerはEigenlayerのAVSの1つであるため、分散型の検証メカニズムにより深く踏み込むことができるかもしれない。
2つのプロジェクトはいくつかの分野で競合するかもしれませんが、独自の強みと技術的な道筋によって、データのエコシステムにおいて異なるニッチを占めることになるかもしれません。
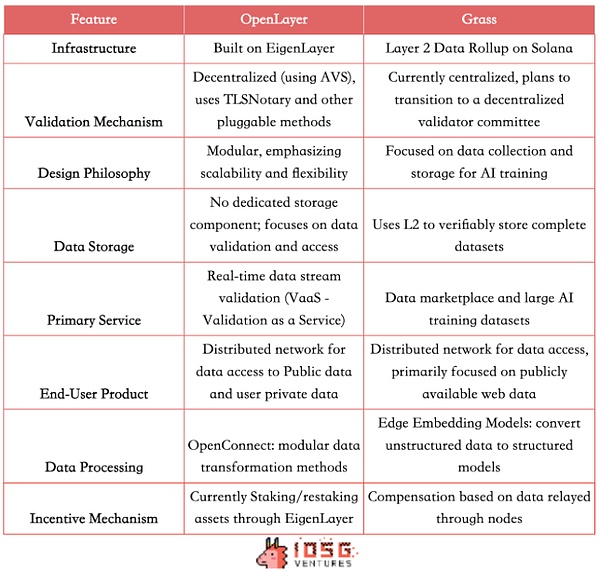
(出典:IOSG, David)。出典:IOSG, David)
4.3 VAVA
もともとMITの研究プロジェクトとして2018年に立ち上げられたVanaは、プライベートなユーザーデータのために特別に設計されたレイヤー1のブロックチェーンであることを意図している。Vanaの中核には、信頼できる非公開の帰属型Data Liquidity Poolと革新的なProof of Contributionメカニズムを通じてブロックチェーンを作成する機能がある。
4.3.1. データ流動性プール
4.3.1. Vanaはデータ流動性プール(DLP)という独自の概念を導入しています。Vanaネットワークの中核的な構成要素として、各DLPは特定の種類のデータ資産を集約するための独立したピアツーピアのネットワークです。ユーザーは、自分のプライベートデータ(ショッピング履歴、閲覧習慣、ソーシャルメディア活動など)を特定のDLPにアップロードし、特定の第三者によるこのデータの使用を許可するかどうかを柔軟に選択することができます。データはこれらの流動性プールを通じて統合・管理され、ユーザーのプライバシーを確保するために非識別化される一方で、AIモデルのトレーニングや市場調査などの商用アプリケーションにデータを参加させることができます。 ユーザーはDLPにデータを提出し、対応するDLPトークン(各DLPに固有)で報酬を得ます。トークンはユーザーのデータプールへの貢献を表すだけでなく、ユーザーにDLPに対するガバナンス権と将来の利益を分配する権利を与えます。ユーザーはデータを共有するだけでなく、その後のデータ呼び出しから継続的な収益を受け取ることができます(視覚的な追跡が可能)。従来の1回限りのデータ販売とは異なり、Vanaはデータが継続的に経済サイクルに参加することを可能にします。 4.3.2.貢献証明メカニズム ヴァナのもう一つの中核となるイノベーションは、貢献証明メカニズムです。ヴァナの中核となるイノベーションのひとつは、貢献の証明メカニズムである。これは、データの品質を保証するためのVanaの主要なメカニズムであり、各DLPがデータの真正性と完全性を検証し、AIモデルのパフォーマンス向上に対するデータの貢献度を評価するために、その特性に基づいて独自の貢献度証明機能をカスタマイズすることを可能にします。このメカニズムにより、ユーザーのデータ貢献が定量化・文書化され、ユーザーに報酬が提供される。暗号通貨におけるProof of Workと同様に、Proof of Contributionはユーザーが貢献したデータの質、量、使用頻度に基づいてユーザーに収益を分配する。これはスマートコントラクトによって自動化されており、貢献者が貢献に対して報酬を得られるようになっている。 データ流動性レイヤー これはVanaの中核レイヤーであり、データへの貢献、検証、およびDanaへの記録を担当します。DLP作成者は、データ貢献の目的、検証方法、貢献パラメータを設定するDLPスマートコントラクトを展開します。データ貢献者とカストディアンは検証のためにデータを提出し、貢献証明(PoC)モジュールはデータの検証と価値評価を行い、パラメータに基づいてガバナンスの権利と報酬を付与します。 データポータビリティ層。 これはデータ貢献者と開発者のためのオープンデータプラットフォームであり、Vanaのアプリケーションレイヤーです。データポータビリティレイヤーは、データ貢献者と開発者がDLPに蓄積されたデータモビリティを使ってアプリケーションを構築するための共同スペースを提供します。アプリケーションを構築するためのデータモビリティユーザー所有モデルの分散トレーニング、AI Dapp開発のためのインフラを提供します。 ユニバーサル・コネクトーム 分散型台帳とVanaエコシステム全体にわたるリアルタイムのデータフローグラフで、Proof of Stakeコンセンサスを使用してVanaエコシステム内のリアルタイムのデータトランザクションを記録します。DLPトークンの効率的な転送を保証し、アプリケーションのクロスDLPデータアクセスを提供します。EVMと互換性があり、他のネットワーク、プロトコル、DeFiアプリとの相互運用が可能です。 (出典:Vana) Vanaは、ユーザーデータの可動性と価値に焦点を当て、異なる道を提供します。この分散型データ交換モデルは、AIトレーニングやデータマーケットプレイスのシナリオに適しているだけでなく、Web3エコシステムにおけるユーザーデータのクロスプラットフォーム相互運用性と認証の機会も提供します。この分散型データ交換モデルは、AIトレーニングやデータマーケットプレイスのようなシナリオに適用されるだけでなく、Web3エコシステムにおけるユーザーデータのクロスプラットフォーム相互運用性と認可のための新しいソリューションを提供し、最終的に、ユーザーが自分自身のデータと、そのデータから作成されたスマート製品を所有し管理する、オープンなインターネットエコシステムを作り出します。 5. The value proposition of decentralised data networks データサイエンティストのクライヴ・ハンビーは2006年に、データは新しい時代の石油であると述べた。過去20年間、私たちは「精製」技術の急速な発展を目の当たりにしてきた。ビッグデータ分析や機械学習といった技術は、かつてないほどデータの価値を解き放った。IDCによると、2025年までに世界のデータユニバースは163 ZBに成長し、そのほとんどは個人ユーザーからもたらされ、IoT、ウェアラブル、AI、パーソナライズされたサービスなどの新興テクノロジーの普及により、将来的に商業的に利用可能な大量のデータも個人からもたらされることになる。 Web3データソリューションは、ノードの分散ネットワークを通じて従来の施設の限界を打破し、より広範で効率的なデータ収集を可能にするとともに、特定のデータへのリアルタイムアクセスや信頼性の検証の効率を向上させます。その過程で、Web3テクノロジーはデータの真正性と完全性を保証し、ユーザーのプライバシーを効果的に保護することで、より公平なデータ利用モデルを実現します。この分散型データアーキテクチャは、データアクセスの民主化を推進します。 OpenLayerやGrassのユーザーノードモデルであれ、Vanaのユーザープライベートデータの収益化であれ、特定のデータ収集の効率を向上させることに加えて、平均的なユーザーにもデータ経済の配当を共有させ、ユーザーと開発者のWin-Winモデルを作り出します。 Vanaモデルは、ユーザーが自分のデータとそれに付随するリソースをコントロールすべきであるという考えに基づいています。 トークンエコノミーを通じて、Web3 Data Solutionsはインセンティブモデルを再設計し、より公平なデータ価値分配メカニズムを作り上げました。これにより、ユーザー、ハードウェア資源、資本が大量に投入され、データネットワーク全体の運用が調整・最適化される。 また、従来のデータソリューションよりもモジュール式でスケーラブルです。例えば、Openlayerのモジュール設計は、将来の技術の反復や生態系の拡大に柔軟に対応します。AIモデルトレーニングのためのデータアクセスを最適化する技術的特徴のおかげで、より豊かで多様なデータセットが提供されます。 データの生成、保存、検証から交換、分析に至るまで、Web3主導のソリューションは、独自の技術的優位性によって従来の施設の欠点の多くを解決すると同時に、ユーザーに個人データを換金する権限を与え、データの経済モデルの根本的な転換を引き起こします。技術が進化し、アプリケーションのシナリオが拡大するにつれて、分散型データレイヤーは、他のWeb3データソリューションとともに次世代の重要なインフラとなり、データ駆動型の産業を幅広くサポートすることが期待されています。Vanaの技術的アーキテクチャ
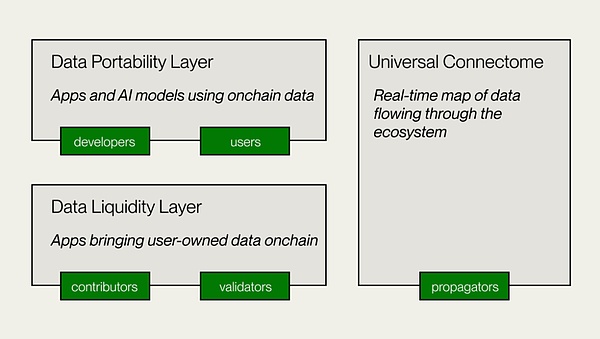
レガシーソリューションのペインポイント:Web3でイノベーションを解き放つ
この記事では、ArweaveとIPFSの冗長性メカニズム、そしてどちらのオプションがデータにとってより安全かを見ていきます。
JinseFinance本稿では、ArweaveとIPFSがどのようにファイルを保存、維持、アクセスし、それがデジタル資産の信頼性と永続性にどのような影響を与えるかを探る。
JinseFinance本稿では、現在のETHエコシステムのレステイキング、AVS、リキッド・レステイキング回路の核となる問題のいくつかを再検討し、リスクと報酬の評価のための類似のフレームワークを予測的に与える。
JinseFinanceアルウィーヴのコア・メカニズムにおいて、非常に重要なコンセプトとコンポーネントのひとつが、貯蓄基金「エンダウメント」である。
JinseFinanceあなたが今日、家族旅行の写真アルバムをネットワーク・ストレージにアップロードしたとしよう。
JinseFinance現在、市場で主流となっている分散型ストレージは、Arweave、Filecoin、Storjで、それぞれユニークな機能と設計コンセプトを持っている。
JinseFinanceこの技術は、オンライン環境との安全な分離を維持しながら、資産の手動処理に関連するリスクを軽減することを目的としている。
 Alex
AlexソフトウェアとITコンサルティングの雄であるIBMは、Hyper Protect Offline Signing Orchestratorの導入により、Web3の分野で波紋を広げている。
 Aaron
Aaronミハエル・セイラー氏のBTCアドレスを追跡するSaylortrackerのデータによると、彼のポートフォリオは7,102,706,533.19ドルで、33.37%の上昇を記録し、史上最高値を更新した。
 Brian
Brian分散ストレージは Web3 にとって不可欠なインフラストラクチャです。しかし現段階では、ストレージの規模にしてもパフォーマンスにしても、分散型ストレージはまだ初期段階にあり、集中型ストレージからは程遠いです。この記事では、いくつかの代表的なストレージ プロジェクト (Storj、Filecoin、Arweave、Stratos Network、Ceramic) を選択し、それらのパフォーマンス、コスト、市場での位置付け、市場価値などの情報を要約および比較し、技術原則を分析し、エコロジーの進歩を要約します。
 链向资讯
链向资讯