Arweave의 작동 방식과 의미
Ar위브,Ar위브의 작동 방식과 존재의 의미 황금 금융,이 문서에서는 Ar위브의 작동 방식과 그 가치에 대한 간략한 개요를 제공합니다.
 JinseFinance
JinseFinance

저자: Arweave Source:X, @ArweaveOasis
2018년 출시 이후 Arweave 생태계는 탈중앙화 스토리지 회로에서 가장 가치 있는 네트워크 중 하나로 여겨져 왔습니다. 그러나 5년이 지난 지금, 기술 중심의 특성으로 인해 많은 사람들이 Arweave/AR에 익숙하면서도 낯설어하고 있습니다. 이 글에서는 아위브에 대한 심도 있는 이해를 돕기 위해 아위브의 시작부터 기술 개발의 역사를 살펴보는 것부터 시작하겠습니다.
아르위브는 5년 동안 12번 이상의 주요 기술 업그레이드를 거쳤으며, 주요 반복의 핵심 목표는 컴퓨팅 기반 마이닝 메커니즘에서 스토리지 기반 마이닝 메커니즘으로 전환하는 것이었습니다.
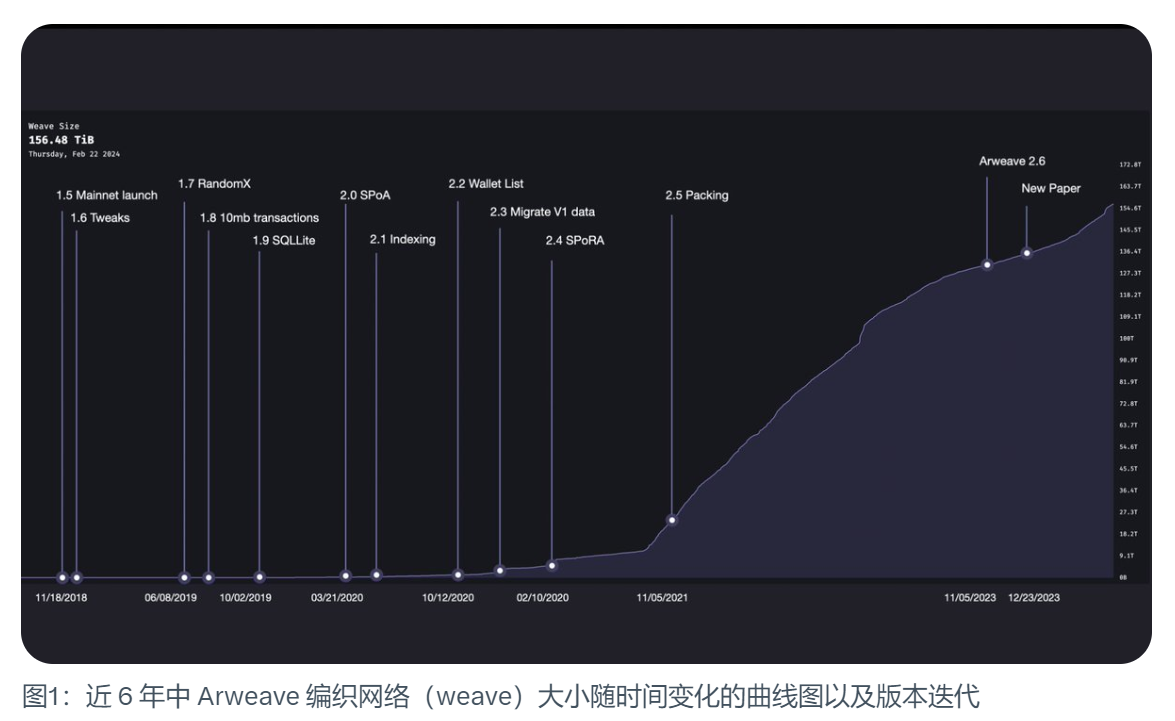
Arweave 1.5: 메인 네트워크 출시
2018년 11월 18일에 Arweave 메인 네트워크가 출시되었습니다. 당시 직조된 네트워크의 크기는 177MB에 불과했습니다. 초기 Arweave는 블록 아웃 시간이 2분, 블록당 스트로크 수가 1,000개로 현재와 비슷한 면이 있었습니다. 그 외에는 트랜잭션당 5.8 MiB의 크기 제한이 있었고, 접근 증명이라는 채굴 메커니즘을 사용하는 등 더 많은 차이가 있었습니다.
문제는 접근 증명(PoA)이란 무엇일까요?
단순히 말해, 새로운 블록을 생성하기 위해서는 채굴자가 블록체인 기록에서 다른 블록에 접근할 수 있음을 증명해야 한다는 사실입니다. 따라서 접근 증명은 체인에서 과거 블록을 무작위로 선택하고 채굴자에게 해당 과거 블록을 생성하려는 현재 블록에 리콜 블록으로 넣도록 요청합니다. 그리고 이는 해당 리콜 블록의 전체 백업이 될 것입니다. <채굴자가 모든 블록을 저장할 필요 없이, 해당 블록에 접근할 수 있다는 것만 증명하면 채굴 경쟁에 참여할 수 있다는 아이디어였습니다. (디맥은 동영상에서 이해하기 쉽도록 자동차 경주의 비유를 사용했으므로 여기서는 이를 인용하겠습니다.)
우선 이 레이스는 참가자 수나 채굴 속도에 따라 결승선이 움직여 항상 약 2분 안에 레이스가 끝나도록 합니다. 이것이 바로 2분 블록 타임의 이유입니다.
두 번째로, 이 대회는 두 부분으로 나뉘어 진행됩니다.
- 예선전이라고 할 수 있는 첫 번째 파트에서 채굴자들은 과거 블록에 접근할 수 있음을 증명해야 합니다. 지정된 블록을 손에 넣으면 최종 라운드에 진출할 수 있습니다. 채굴자가 저장 블록을 가지고 있지 않더라도 동료로부터 블록에 액세스하여 경쟁에 참여할 수 있습니다.
- 예선 후 결승에 해당하는 두 번째 단계에서는 해시 연산 능력을 사용하는 작업 증명 방식으로 채굴하며, 기본적으로 해시 계산을 위해 에너지를 소비하고 궁극적으로 경쟁에서 승리하는 것입니다.
채굴자가 결승선을 통과하면 레이스가 끝나고 다음 레이스가 시작됩니다. 그리고 채굴 보상은 모두 우승자 한 명에게 돌아가기 때문에 채굴은 매우 치열하게 진행됩니다. 그 결과 Arweave는 빠르게 성장하기 시작했습니다.

Arweave 1.7: RandomX
초기의 Arweave 원리는 매우 간단하고 이해하기 쉬운 메커니즘이었지만, 연구원들이 한 가지 바람직하지 않은 결과를 깨닫는 데는 그리 오랜 시간이 걸리지 않았습니다. 즉, 채굴자들이 네트워크에 해로운 전략을 채택할 수 있으며, 이를 우리는 퇴행적 전략이라고 부릅니다.
주로 일부 채굴자는 지정된 빠른 액세스 블록을 저장하지 않은 상태에서 다른 사람의 블록에 액세스해야 하기 때문에 블록을 저장한 채굴자보다 한 단계 느려져 출발선에서 뒤처지게 됩니다. 하지만 해결책도 간단합니다. 많은 GPU를 쌓아놓고 큰 컴퓨팅 파워와 많은 에너지 소비로 이를 보완하면 블록을 저장하고 빠른 액세스를 유지하는 채굴자보다 더 나은 성능을 낼 수 있습니다. 이 전략이 주류가 되면 채굴자들은 블록을 저장하고 공유하는 것을 중단하고 대신 경쟁에서 승리하기 위해 연산 장치를 최적화하고 많은 에너지를 소비하게 될 것입니다. 그 결과 네트워크의 효용성이 크게 감소하고 데이터가 점차 중앙 집중화될 것입니다. 이는 분명 스토리지 네트워크의 퇴보적인 출발점입니다.
이 문제를 해결하기 위해 Arweave 버전 1.7이 등장했습니다.
이 버전의 가장 큰 특징은 RandomX라는 메커니즘을 도입한 것입니다. 이는 GPU나 ASIC 장치에서 실행하기 매우 어려운 해싱 공식으로, 채굴자들이 GPU 파워 스택을 포기하고 범용 CPU를 사용하여 해싱 파워 경쟁에서 경쟁하게 만듭니다.
Arweave 1.8/1.9: SQL 라이트의 트랜잭션 크기 10MB
채굴자가 과거 블록에 접근할 수 있다는 것을 증명하는 것보다 더 중요한 문제는 사용자가 Arweave에 게시한 트랜잭션을 처리하는 것입니다.
모든 새로운 사용자 트랜잭션 데이터는 새로운 블록으로 패키징되어야 하며, 이는 퍼블릭 체인의 최소 요건입니다. Arweave 네트워크에서 사용자가 채굴자에게 트랜잭션을 제출하면 해당 채굴자는 해당 데이터를 자신의 다음 블록에 패키징할 뿐만 아니라 다른 채굴자들과 공유하여 모든 채굴자가 다음 블록에 트랜잭션을 패키징할 수 있도록 합니다. 왜 이렇게 할까요? 블록에 포함된 각 트랜잭션 데이터가 해당 블록의 보상을 증가시키기 때문에 금전적 인센티브가 있기 때문입니다. 마이너들이 거래 데이터를 서로 공유하면 블록을 생성할 권리를 획득한 사람이 최대 보상을 받을 수 있습니다.
-네트워크 개발의 데스 스파이럴 방지. 사용자의 거래 데이터가 수시로 블록에 담기지 않으면 사용자가 점점 줄어들고 네트워크의 가치가 떨어지며 채굴자는 돈을 덜 벌게 될 것이고, 이는 아무도 원하지 않는 일입니다. <따라서 채굴자들은 이러한 상호 이익이 되는 방식으로 자신의 이익을 극대화하는 방법을 선택합니다. 그러나 이로 인해 데이터 전송에 문제가 발생하고, 이는 네트워크 확장성의 병목 현상이 됩니다. 트랜잭션이 많을수록 블록이 커지는데, 5.8MB의 트랜잭션 제한은 도움이 되지 않았습니다. 그 결과, Arweave는 하드포크를 통해 트랜잭션 크기를 10 MiB로 늘림으로써 어느 정도 안도감을 얻었습니다.
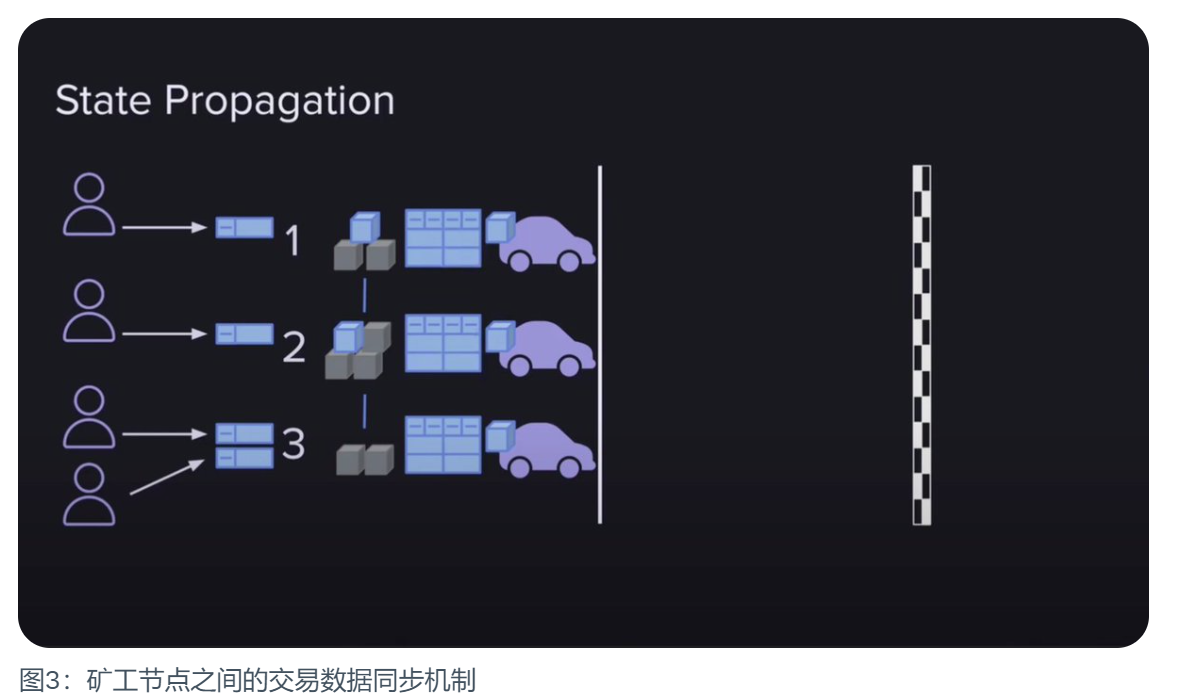
그러나 그럼에도 불구하고 전송 병목현상은 여전히 해결되지 않았습니다.Arweave는 전 세계에 분산된 채굴자 네트워크로, 모두 자신의 상태를 동기화해야 합니다. 그리고 각 채굴자는 서로 다른 속도의 연결을 통해 네트워크의 평균 연결 속도를 제공합니다. 네트워크가 2분마다 새로운 블록을 생성하려면 2분 동안 저장하고자 하는 모든 데이터를 업로드할 수 있을 만큼 연결 속도가 빨라야 합니다. 사용자가 네트워크의 평균 연결 속도보다 더 많은 데이터를 업로드하면 네트워크가 혼잡해지고 네트워크의 효용성이 떨어질 수 있습니다. 이는 Arweave 개발의 걸림돌이 될 수 있습니다. 따라서 1.9의 후속 업데이트에서는 네트워크의 성능을 개선하기 위해 SQL lite와 같은 인프라를 사용합니다.
2020년 3월 Arweave 2.0 업데이트에서는 네트워크에 두 가지 중요한 업데이트를 도입했으며, 그 결과 네트워크 확장성의 족쇄를 풀고 Arweave에 데이터를 저장하는 능력의 한계를 깨뜨렸습니다.
첫 번째 업데이트는 간결한 증명입니다. 이는 메르켈 트리 암호화 구조를 기반으로 하며, 채굴자는 간단한 메르켈 트리로 압축된 분기 경로를 제공하여 블록의 모든 바이트를 저장했음을 증명할 수 있습니다. 이를 통해 채굴자는 1KB 미만의 간결한 증명만 블록에 담으면 되며, 더 이상 10GB에 달하는 역방향 블록을 담을 필요가 없습니다.
두 번째 업데이트는 "형식 2 트랜잭션"입니다. 이 버전은 노드 간에 공유되는 데이터 전송 블록을 슬림화하기 위해 트랜잭션 형식을 최적화합니다. 트랜잭션의 헤더와 데이터를 동시에 블록에 추가해야 하는 형식 1 트랜잭션과 달리 형식 2 트랜잭션은 헤더와 데이터를 분리할 수 있어 채굴자 노드 간 블록 정보 데이터 공유 전송에서 간결한 증명이 있는 역추적 블록을 제외하고는 트랜잭션의 헤더만 블록에 추가하면 되고 거래의 데이터는 레이스 종료 시점에 블록에 추가할 수 있습니다. 이렇게 하면 채굴자 노드 간에 블록 내 트랜잭션을 동기화할 때 전송 요구 사항이 크게 줄어듭니다.
이러한 업데이트의 결과로 과거보다 더 가볍고 전송하기 쉬운 블록이 생성되어 네트워크에서 초과 대역폭을 확보할 수 있게 됩니다. 채굴자는 이 시점에서 이 초과 대역폭을 사용하여 향후 역추적 블록이 될 '형식 2 트랜잭션'의 데이터를 전송할 것입니다. 따라서 확장성 문제가 해결됩니다.
Arweave 2.4: SPoRA
지금까지 Arweave 네트워크의 모든 문제가 해결되었나요? 대답은 분명히 '아니오'입니다. 새로운 SPoA 메커니즘에서 또 다른 문제가 발생했습니다. <채굴자들이 GPU 파워를 쌓는 방식과 유사한 채굴 전략이 다시 등장했습니다. 이번에는 GPU 스태킹에서 파워의 중앙 집중화는 아니지만, 보다 컴퓨팅 중심적인 전략이 주류로 떠오르고 있습니다. 바로 고속 액세스 스토리지 풀의 등장입니다. 모든 과거 블록은 이러한 스토리지 풀에 보관되며, 접근 증명이 무작위 역추적 블록을 생성할 때 매우 빠른 속도로 증명을 생성하고 채굴자 간에 이를 동기화할 수 있습니다.
그러나 이러한 전략에서도 데이터를 충분히 백업하고 저장할 수 있기 때문에 큰 문제는 없어 보입니다. 하지만 문제는 이러한 전략은 더 이상 데이터에 고속으로 접근할 인센티브가 없는 채굴자들의 초점을 무의식적으로 이동시킨다는 것입니다. 이제 증명 전송이 너무 쉽고 빠르기 때문에 데이터를 저장하는 대신 작업 증명 해싱에 대부분의 노력을 쏟게 될 것이기 때문입니다. 이것은 또 다른 형태의 퇴행적 전략이 아닐까요?

그래서 Arweave는 데이터 인덱싱 반복(인덱싱), 지갑 목록 압축(월렛 목록), V1 트랜잭션 데이터 마이그레이션 등 여러 기능 업그레이드를 거쳤습니다. 마지막으로, 또 다른 대규모 릴리스인 간결한 무작위 접근 증명인 SPoRA가 출시되었습니다.
SpoRA는 채굴자들이 해시 계산에서 데이터 저장으로 주의를 전환할 수 있도록 하는 메커니즘을 반복함으로써 Arweave를 완전히 새로운 시대로 안내합니다.
랜덤 액세스 간결한 증명은 어떻게 다를까요? <두 가지 전제 조건, 즉 색인된 데이터 집합에서 시작됩니다. 버전 2.1의 반복 인덱싱 기능 덕분에 직조 네트워크의 각 데이터 청크(Chunk)에 글로벌 오프셋으로 레이블을 지정하여 각 청크가 이 글로벌 오프셋으로 빠르게 액세스할 수 있도록 합니다. 이제 SPoRA의 핵심 메커니즘인 데이터 청크의 순차적 검색에 대해 알아봅시다. 여기서 언급된 청크는 파티셔닝 후 대용량 파일에서 가장 작은 데이터 단위로, 256KiB 크기이며 블록의 개념이 아니라는 점을 상기할 필요가 있습니다.
-슬로우 해시. 이 해시는 후보 청크를 무작위로 선택하는 데 사용됩니다. 버전 1.7에 도입된 랜덤엑스 알고리즘 덕분에 채굴자는 파워 스태킹을 사용하여 앞서나갈 수 없으며, 계산을 위해 CPU만 사용할 수 있습니다.
이 두 가지 전제 조건에 따라 SPoRA 메커니즘은 4단계 프로세스로 진행됩니다.
첫 번째 단계에서는 난수를 생성하고 이 난수를 사용하여 RandomX를 통해 이전 블록의 정보로 느린 해시를 생성하고, 두 번째 단계에서는 이 느린 해시를 사용하여 블록의 글로벌 오프셋인 고유 리콜 바이트를 계산하고, 세 번째 단계에서는 이 리콜 바이트를 사용하여 블록의 오프셋인 고유 리콜 바이트를 계산하고, 마지막으로 채굴자는 이 리콜 바이트를 사용하여 고유 리콜 바이트의 계산에 사용합니다. 채굴자는 이 리콜 바이트를 사용해 자체 저장소에서 해당 데이터 블록을 찾습니다. 마이너는 데이터 블록을 저장하지 못하면 첫 번째 단계로 돌아가 다시 시작하고, 네 번째 단계에서는 첫 번째 단계에서 생성된 느린 해시를 사용하여 방금 찾은 데이터 블록으로 빠른 해시를 수행하고, 다섯 번째 단계에서 계산된 해시 결과가 현재 채굴 난이도 값보다 크면 블록의 채굴 및 분배가 완료됩니다. 대신 첫 번째 단계로 돌아가서 다시 시작합니다.
그러므로 여기서 볼 수 있듯이 이는 채굴자가 멀리 떨어진 스토리지 풀이 아닌 매우 빠른 버스를 통해 CPU에 연결할 수 있는 하드 드라이브에 가능한 한 많은 데이터를 저장하도록 하는 큰 인센티브가 됩니다. 컴퓨팅 중심에서 스토리지 중심으로 채굴 전략의 전환을 완료한 것입니다.
Arweave 2.5: 패킹과 데이터 급증
SPoRA는 채굴 효율성을 개선하기 위해 채굴자들이 미친 듯이 데이터를 저장하기 시작하게 만들었습니다. 그 다음에는 어떤 일이 일어났을까요?
일부 영리한 채굴자들은 이 메커니즘의 병목 현상이 실제로 하드 드라이브에서 데이터를 얼마나 빨리 가져올 수 있느냐에 달려 있다는 사실을 깨달았습니다. 하드 드라이브에서 가져올 수 있는 데이터 청크가 많을수록 더 간결한 증명을 계산할 수 있고, 더 많은 해시 연산을 수행할 수 있으며, 채굴 가능성도 높아집니다.
예를 들어 한 채굴자가 데이터를 저장하는 데 더 빠른 읽기 및 쓰기 속도를 가진 SSD를 사용하는 등 하드 드라이브에 10배 더 많은 비용을 지출한다면, 해당 채굴자는 10배 더 많은 해싱 파워를 갖게 될 것입니다. 물론 이것은 GPU 컴퓨팅 파워와 비슷한 군비 경쟁이 될 것입니다. 더 빠른 전송 속도를 가진 이색적인 형태의 스토리지인 RAM 드라이브와 같이 SSD보다 더 빠른 형태의 스토리지도 등장할 것입니다. 하지만 이 모든 것은 입출력 비율에 달려 있습니다.
현재 채굴자가 해시를 생성할 수 있는 가장 빠른 속도는 SSD 하드 드라이브의 읽기/쓰기 속도이며, 이는 작업 증명과 유사한 모드에서 에너지 소비에 더 낮은 제한을 두므로 환경 친화적입니다.
완벽할까요? 물론 아닙니다. 기술자들은 이보다 더 나은 방법이 있다고 생각합니다.
더 큰 규모의 데이터 업로드를 허용하기 위해 Arweave 2.5는 데이터 번들을 도입했습니다. 이것은 실제로 프로토콜 업그레이드가 아니었지만 확장성 계획의 큰 부분이었으며, 네트워크의 크기를 폭발적으로 늘릴 수 있었습니다. 처음에 말씀드렸던 블록당 1,000개의 트랜잭션 한도를 깨뜨릴 수 있기 때문입니다. 데이터 번들은 그 1000개의 트랜잭션 중 하나만 차지합니다. 이것이 Arweave 2.6의 토대가 되었습니다.
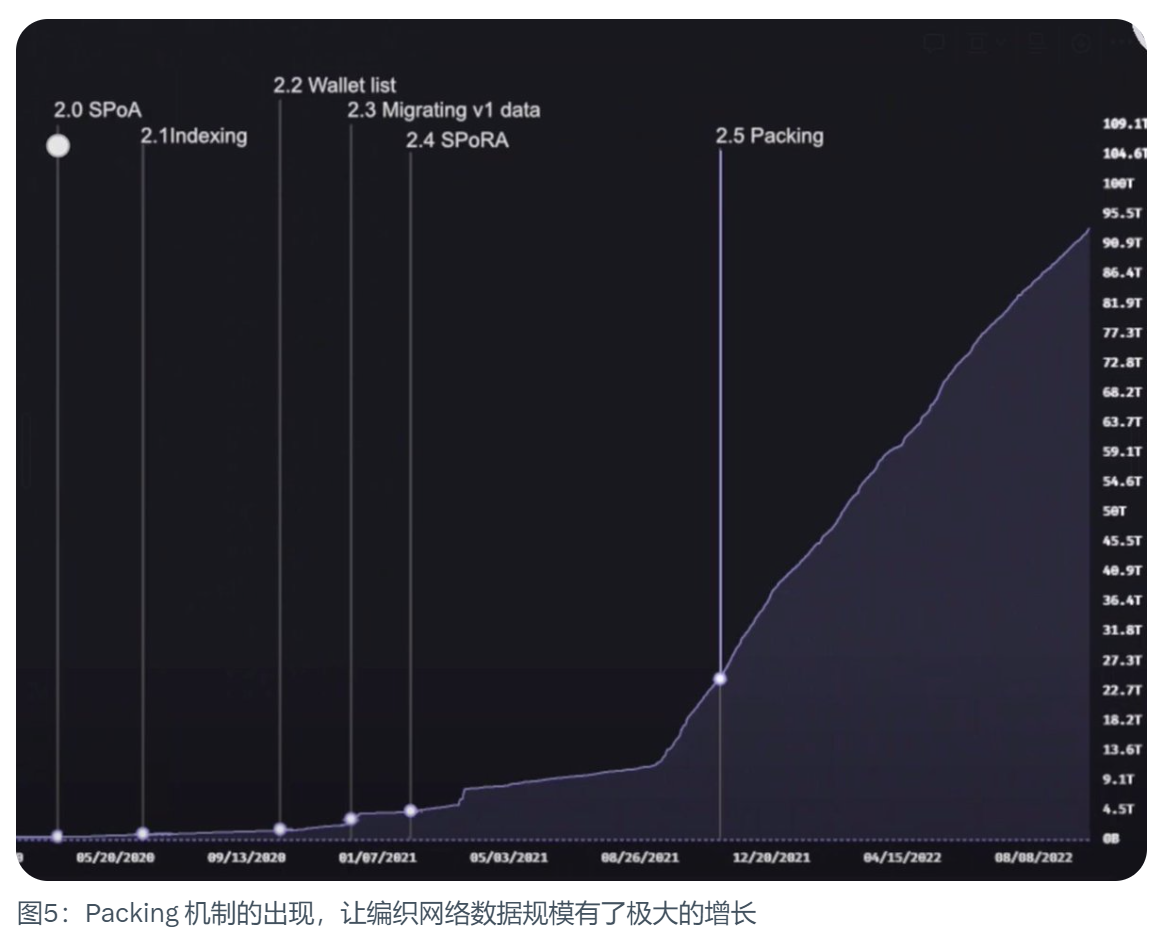
Arweave 2.6
Arweave 2.6은 SPoRA 이후 주요 버전 업그레이드입니다. 이전 릴리스를 기반으로 구축되었으며, Arweave 채굴의 비용 효율성을 높여 보다 탈중앙화된 채굴자 분배를 촉진한다는 비전에서 한 걸음 더 나아갔습니다.
그렇다면 정확히 무엇이 달라졌나요? 지면 제약으로 인해 여기서는 간략한 개요만 말씀드리고, 추후에 Arweave 2.6의 메커니즘에 대해 더 구체적으로 말씀드리겠습니다.
단순히 말해, Arweave 2.6은 SPoRA의 속도 제한 버전으로, 1초에 한 번씩 틱하는 검증 가능한 암호화 클럭을 SPoRA에 도입하여 해시체인이라고 부릅니다. <매 틱마다 채굴 해시를 생성하고,
- 채굴자는 채굴에 참여할 저장 데이터 파티션의 인덱스를 선택하고,
- 이 채굴 해시와 파티션 인덱스의 조합은 채굴자가 선택한 저장 데이터 파티션 내에서 400개의 룩백 블록으로 구성된 룩백 범위를 생성하며, 이는 채굴자가 채굴에 사용할 수 있는 블록인 룩백 블록입니다. 마이너가 채굴에 사용할 수 있는 블록입니다. 이 범위의 백트래킹 외에도 위브 네트워크(위브)에서 또 다른 범위의 백트래킹 2가 무작위로 생성되며, 채굴자가 충분한 데이터 파티션을 저장한 경우 최종 승리 확률을 높이기 위해 이 범위 2, 즉 400개의 백트래킹 블록 채굴 기회를 추가로 얻을 수 있습니다. 이는 마이너가 데이터 파티션의 사본을 충분히 저장하도록 하는 좋은 인센티브입니다.
- 채굴자는 역추적 범위 내의 블록을 사용하여 하나씩 테스트하고, 그 결과가 현재 주어진 네트워크 난이도보다 크면 채굴권을 획득하고, 충족되지 않으면 다음 데이터 블록을 사용하여 테스트합니다.
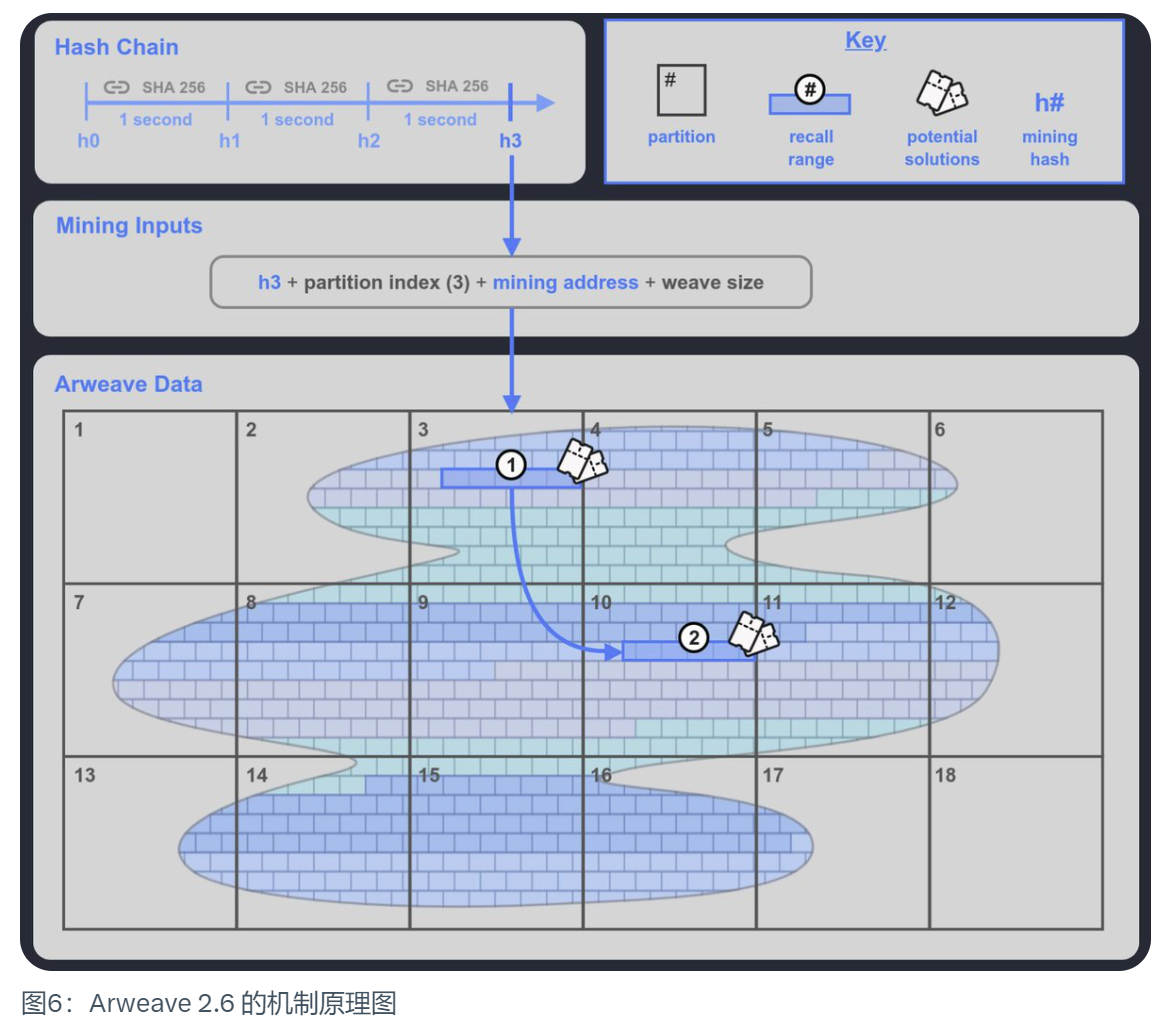
이것은 초당 생성되는 최대 해시 수가 고정되어 있음을 의미하며, 2.6 버전에서는 일반 기계식 하드 드라이브도 처리할 수 있는 범위 내에서 유지됩니다. 따라서 초당 수천 또는 수십만 개의 해시를 최대로 처리할 수 있는 SSD 기반 하드 드라이브의 성능은 초당 수백 개의 해시에 불과한 기계식 하드 드라이브와 경쟁할 수 있게 되었습니다. 이는 제한 속도가 시속 60킬로미터인 경주에서 람보르기니와 도요타 프리우스가 경쟁하는 것과 같으며, 람보르기니의 우위는 상당히 제한적입니다. 따라서 이제 마이닝 성능에 가장 큰 영향을 미치는 것은 마이너가 저장하는 데이터 세트의 수입니다.
위는 Arweave의 진화에 있어 주요한 반복적 이정표 중 일부입니다. PoA에서 SPoA, SPoRA, 속도 제한 버전인 2.6 버전에 이르기까지 Arweave는 항상 원래의 비전을 따랐습니다. 2023년 12월 26일, Arweave는 이러한 메커니즘을 기반으로 합의 메커니즘을 단순 복제 증명인 SPoRes로 발전시킨 또 다른 백서인 2.7 버전을 공식적으로 발표했습니다.
Ar위브,Ar위브의 작동 방식과 존재의 의미 황금 금융,이 문서에서는 Ar위브의 작동 방식과 그 가치에 대한 간략한 개요를 제공합니다.
JinseFinance이 백서에서는 저장된 기부금이 어떻게 작동하는지 자세히 살펴본 다음, 마르코프 체인을 사용하여 실행을 모델링하여 기부금의 속성과 위험 프로필을 살펴봅니다.
JinseFinance이 글에서는 Arweave와 IPFS의 이중화 메커니즘과 어떤 옵션이 데이터에 더 안전한지 살펴봅니다.
JinseFinance매일 1,000억 개의 WhatsApp 메시지가 전송됩니다. 대부분의 블록체인은 저장용으로 설계되지 않았습니다. 1,000억 개의 WhatsApp 메시지를 이더나 다른 블록체인에 저장하려면 비용이 엄청나게 많이 들 것입니다.
JinseFinance이 백서에서는 Arweave와 IPFS가 파일을 저장, 유지, 액세스하는 방법과 이것이 디지털 자산의 안정성과 지속성에 어떤 영향을 미치는지 살펴봅니다.
JinseFinanceArweave는 블록위브 기술과 네이티브 암호화폐 AR 토큰을 통해 영구적이고 불변하는 데이터 저장 서비스를 제공하는 탈중앙화 데이터 저장 솔루션입니다.
JinseFinanceArweave가 Filecoin을 대체하는 것이 아니라 더 주목해야 하는 주요 혁신인 이유입니다.
JinseFinance아이리스는 아위브를 포크하여 토큰 공급을 초기화할 계획이며, 이에 대해 아위브의 창립자는 근시안적이고 탐욕스럽다는 비판을 받고 있습니다.
 BerniceJinseFinance
BerniceJinseFinance이번 행사에는 100명 이상의 Arweave 에코시스템 개발자와 투자자가 참석할 예정이며, 참석자에게는 제품 테스트 기회, AR 에어드랍 보상, 실용적인 상품 등 특별한 혜택이 제공될 예정입니다.
 Samantha
Samantha