Visaは、AIエージェントがすべてのカードネットワークで買い物や支払いを行えるようにする「Intelligent Commerce Connect」を導入しました
Visaは、AIエージェントがユーザーに代わってVisaカードおよびVisa以外のカードを利用して商品の閲覧、選択、支払いを行うことができるプラットフォーム「Intelligent Commerce Connect」をリリースしました。
 Anais
Anais

ネットワークは、AIビッグモデル時代の重要なピースです。ビッグモデルの時代には、光モジュールやスイッチなどのネットワーク機器に対する反復の加速と爆発的な需要が見られ始めています。しかし、なぜグラフィックカードが大量の光モジュールと組み合わせる必要があるのか、なぜ通信がビッグモデルのペインポイントになっているのか、市場の理解は浅い。本稿では、なぜネットワークがAI時代の新たな「Cポジション」になったのかという原理原則から出発し、最新の業界変化の背景にあるイノベーションと投資機会について、ネットワークサイドの今後を考察する。
ネットワークの需要はどこから来るのか?大規模モデルの時代において、モデルサイズとシングルカード容量のギャップは急速に広がっており、業界はモデルトレーニング問題を解決するためにマルチサーバクラスタに目を向けており、これはAI時代のネットワーク「アップ」の基礎も形成しています。同時に、純粋にデータの伝送のための過去に比べて、今日のネットワークは、より多くのグラフィックスカード間のモデルパラメータを同期するために使用され、ネットワークの密度は、ネットワークの容量は、より高い要件を提示している。
ますます大きくなるモデル量:(1)学習時間=学習データサイズ×モデルパラメータ数/計算速度(2)計算速度=シングルデバイス計算速度×デバイス数×マルチデバイス並列効率。さて、デュアル追求の訓練データサイズとパラメータの業界では、訓練時間を短縮するために計算効率を加速する唯一の方法は、シングルデバイスの計算速度の更新は、そのサイクルと制限がありますので、できるだけネットワークを使用する方法 "デバイスの数 "と "並列効率 "を拡大する直接演算を決定します。
マルチカード同期の複雑さ:大規模なモデル学習中、モデルを個々のカードに切り刻むには、計算ごとにカード間の整列(Reduce、Gatherなど)が必要です。All-to-All (つまり、すべてのノードが互いの値にアクセスでき、整列される) 操作は、NVIDIA の通信プリミティブのシステムである NCCL ではより一般的であり、したがって、ネットワーク間の伝送および交換に高い需要があります。
増大する高価な障害コスト:大規模モデルのトレーニングは、しばしば数ヶ月以上続き、その間に中断があると、数時間または数日前のブレークポイントに戻って再トレーニングする必要があります。また、ネットワーク全体における単一のハードウェアまたはソフトウェアのリンクの障害、または過度の待ち時間は、中断につながる可能性があります。より多くの中断は、進歩の遅れとコストの増加を意味する。現代のAIネットワークは、航空機や空母などに匹敵する人間のシステムエンジニアリング能力の集大成へと徐々に進化している。
ネットワーク・イノベーションはどこへ向かうのか?ハードウェアは需要に応じて動き、2年後、世界的な演算投資の規模は数百億ドルレベルにまで膨れ上がり、モデルパラメータの拡大は、悲劇的な戦いの巨人はまだ激しいです。今日、コスト削減、開放性、規模のバランスは、ネットワーク革新の主要な問題になります。
通信媒体の反復:光、銅、シリコンは、人類の伝送の3大媒体であり、AIの時代には、光モジュールがより高速を追求する一方で、LPO、LRO、シリコン光などのコスト削減へのステップも踏んでいる。現時点では、費用対効果や故障率などの観点から、カッパーがインキャビネット・コネクティビティに取って代わっている。また、チップレット、ウェハースケーリングなどの新しい半導体技術は、シリコンベースの相互接続の上限の探求を加速させています。
ネットワークプロトコル競争:チップ間通信プロトコルは、NVIDIAのNV-LINK、AMDのInfinity Fabric などのグラフィックスカードと強く結びついており、1台のサーバーまたは1台の演算ノードの能力を決定します。上限は、非常に残酷な巨大な戦場です。そして、IBとイーサネットの闘いは、ノード間通信のメインテーマです。
ネットワークアーキテクチャの変化:現在のノード間ネットワークアーキテクチャは、リーフリッジアーキテクチャが一般的で、便利でシンプルで安定しています。しかし、1つのクラスタ内のノード数が増えるにつれて、リーフリッジのやや冗長なアーキテクチャは、非常に大規模なクラスタに大きなネットワークコストをもたらすことになります。今日、ドラゴンフライやレールオンリーアーキテクチャのような新しいアーキテクチャが、次世代メガクラスタの進化の方向性として期待されています。
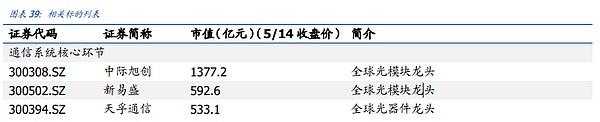
投資アドバイス:通信システムコアリンク:国際許褚、新Easun、天府通信、工業福建、Invec、Hudian株。通信システム革新リンク:長飛光ファイバー、泰成光、遠傑科学技術、盛科通信宇、カンブリアン、徳力。"https://img.jinse.cn/7227140_image3.png">


1。strong>。 投資の要点
AIトレーニングにおけるコミュニケーションネットワークの重要性を、市場は過小評価している。AI市場は、ネットワーク産業チェーンの研究に産業チェーンのロジックフォーカスからより多くの市場以来、主な研究方向は、ネットワークアーキテクチャの各世代に必要な光モジュールの数に焦点を当て、産業チェーンの各リンクの生産と性能測定の基礎として、しかし、研究の基礎となる関係のAIと通信の市場は少ないです。本稿では、モデルから、マルチカード同期、トレーニング費用対効果など3つの側面のAI時代の通信ネットワークの中核的な位置、より深い議論。
一言で言えば、AI時代に通信がCの位置に立つ主な理由は3つある。第一に、ますます大規模になるモデル量、グラフィックカードの数、接続の計算効率は、訓練に必要な時間を直接決定します。第二に、トレーニングの原則から、モデル並列処理からデータ並列処理への主流の並列モードでは、コンピューティングの各層の後、既存のパラメータを整列させるために、異なるNPUの間にクラスタ化する必要があり、整列プロセスのチップタイムの数千は、低遅延と精度を確保するために、ネットワークの非常に高い要件。第三に、ネットワーク障害のコストは非常に高いですが、現在のモデルの訓練時間は、多くの場合、数ヶ月続く、一度障害またはそれ以上の中断は、アーカイブポイントの前に数時間に戻ってアーカイブされている場合でも、全体的な訓練の効率とコストは、巨大なAI製品の反復の分と秒のために、大きな損失を生成しますより致命的な。同時に、クラスタのサイズはすでに1万枚に達し、接続されたコンポーネントは数十万個に達する可能性があり、これらのコンポーネントの全体的な安定性と歩留まりを確保する方法は、非常に奥深いシステムエンジニアリングとなっている。通信ネットワークの反復に対する市場の理解は、どちらかというとグラフィックカードの買い替えに伴う研究のレベルです。ハードウェアの反復によってもたらされるアップデートの周期と方向性は比較的固定されており、それ以外の反復の方向性と産業チェーンの革新の度合いは日々高まっていると考えています。同時に、現在の海外の巨人のAI資本投資戦争は数百億ドルレベルに達し、モデルパラメータの拡大、巨人の悲惨な戦いは依然として激しい。現在、「コスト削減」、「開放性」、「算術規模」のバランスがネットワーク革新の主要な話題となる。
全体として、産業チェーンのフロンティア開拓は主に3つの方向に焦点を当てている。第一に、通信媒体の反復。これには、光、銅、シリコン基板の共通の進歩と、LPO、LRO、シリコンオプティカル、チップレット、ウェハースケーリングなど、さまざまな媒体内の技術革新が含まれます。第二に、通信プロトコルの革新、これには2つの側面があり、第一に、NVLINKやInfinity Fabricなどのノード内部通信は、障壁と革新の分野が非常に難しく、巨人の戦場に属しています。第三に、ネットワークアーキテクチャの更新、リーフリッジアーキテクチャが超多ノード数に適応できるかどうか、DrangonflyがOCSの助けを借りて次世代ネットワークアーキテクチャの主流になれるかどうか、Rail-only+ソフトウェアの最適化が成熟できるかどうか、これらはすべて業界にとって新しい視点である。
業界触媒:
1.スケーリング法則は引き続き有効であり、拡大するクラスターの規模は、通信ネットワークの需要が増加し続けています。
2. 海外のAIがサイクルを加速しており、インターネット大手が設備投資競争を加速している。
投資アドバイス:通信システムのコアリンク:中間のXutron、新しい易生、天府通信、Hudian株。
通信システムの革新リンク:長飛光ファイバー、中天科技、恒通光電、盛科通信。
2. クラウドコンピューティングの時代からAIの時代へ、なぜ通信がますます重要になるのか
前戦通信の栄光はインターネット時代にまで遡ることができる。爆発的なネットワークトラフィックの伝送需要によって、人類は初めて大量のサーバー、ストレージ、スイッチを組み合わせた交換システムを構築した。この一連の構築において、シスコは人類の技術進歩のリーダーとして一人立ちしていた。しかし、インターネットの波が穏やかになるにつれ、光モジュールとスイッチは、マクロ経済、クラウド支出、製品の更新や変動に伴い、よりマクロ経済的な品種に偏り、速度、技術の反復もよりステップバイステップで、変動上向きの定常状態の開発期間のサイクルになります。
小型モデルの時代には、業界はアルゴリズムの革新に重点を置いており、多くの場合、モデル全体のボリュームは、単一のカード、単一のサーバー、または比較的単純な小さなクラスタによって負担することができ、AI側からのネットワーク接続のニーズは顕著ではありません。しかし、大規模なモデルの出現はすべてを変え、OpenAIは、より良いモデルの性能の形でパラメータを積み重ねることにより、よりシンプルなトランスフォーマーアルゴリズムで、現在では、業界全体が急速な発展のモデルボリュームの加速拡大の期間に入っていることを証明した。
まず、モデルの計算速度を決定する2つの基本式を見てみましょう。そうすることで、なぜ算術スケールや算術ハードウェア産業チェーンが大型モデルの時代に最初に恩恵を受けるのかをよりよく理解することができます。
(1) トレーニング時間=トレーニングデータサイズ×モデルパラメータ数/計算速度
(2) 計算速度=シングルデバイス計算速度×デバイス数×マルチデバイス並列効率
(2) 計算速度=シングルデバイス計算速度×デバイス数数×マルチデバイス並列効率
現在のビッグモデルの時代では、トレーニング時間消費の分子末端の2つの要因が同時に拡大していることがわかります。演算能力が一定の場合、トレーニング時間消費は指数関数的に長くなります。貴重な資源である。したがって、競争の道は明らかです:スタッキングを加速する唯一の方法は、パワーをスタッキングすることです。
2番目の式では、我々は、ますます拡大演算今日では、モデルのボリュームに起因するシングルカード演算、チップの更新の上限は、割合の演算構成では、全体からリングの1つに劣化していることがわかります、グラフィックスカードの数だけでなく、マルチデバイスの並列処理の効率はまた、2つの等しく重要なリンクとなっている、英国である。NVIDIAのMellanoxの前向きな買収の理由は、計算速度のすべての決定要素でリードを取りたいことです。
シングルカード演算への複数のルートについては、前回のレポート「AI演算のASICパス - イーサ採掘マシンから始まる」で詳述したので、今回は割愛しますが、後者の2つ、デバイス数とマルチデバイス並列の効率は、単純にグラフィックカードの枚数を重ねるだけでは達成できないことがわかりました。デバイスの数が増えれば増えるほど、ネットワーク構造の信頼性の度合いが指数関数的に高まり、必要とされる並列計算の最適化の度合いが高まることが、ネットワークがAIにおける重要なボトルネックのひとつである究極の理由である。デバイスの積層と並列販売の増加が、人類史上最も複雑なシステム・プロジェクトである理由を説明するために、このセクションでトレーニングの原理を見ていきます。
2.1 ビッグモデル時代のマルチカード連携の原則、モデル並列性とデータ並列性
モデルにおいてモデル トレーニングでは、モデルを複数のカードに分割するプロセスは、従来のパイプラインや単純な分割のように単純ではなく、グラフィックス カード間でタスクを分散する、より複雑な方法です。全体として、タスク割り当てには、モデル並列処理とデータ並列処理の 2 つの大まかなアプローチがあります。
モデル サイズが小さく、データ量が増加傾向にあった初期の頃は、データ並列が一般的に使用されていました。データ並列コンピューティングでは、モデルの完全なコピーを各GPUに保持し、学習用のデータを異なるグラフィックカードに分割して学習させ、バックプロパゲーション後に各カード上のモデルコピーの勾配を同期して減少させる。しかし、モデルパラメータインフレのもとでは、1枚のグラフィックカードでフルモデルを収容することが難しくなってきており、ヘッドサイズのモデル学習では1枚の並列割り当てとしてデータ並列性が低下してきている。
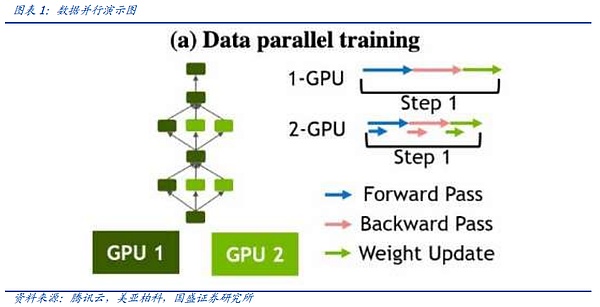
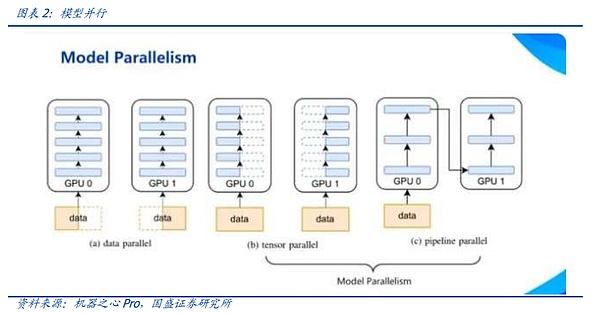
モデル並列性は、ビッグモデル時代の新たな分散手法です。モデル並列主義は、大きなモデルの時代における新たな分配方法です。モデルが非常に大きいため、モデルの異なる部分がグラフィックカードにロードされ、カードは各部のパラメータをトレーニングするために同じデータストリームを供給されます。
モデルの並列性には、テンソル並列性とパイプライン並列性という2つの支配的なモデルがあります。モデル訓練操作(C=AxB)の基礎となる操作の行列乗算において、テンソル並列性とは、まずB行列を複数のベクトルに分割し、各デバイスがベクトルを保持し、次にA行列とこれらのベクトルのそれぞれを別々に乗算し、結果を集約してCリフトを要約することを意味します。
一方、パイプライン並列では、レイヤーごとにモデルを分割し、各ピースを単一のデバイスに与えて実行させます。前方伝播の間、各デバイスは中間活性化を次のステージに渡し、続く後方伝播の間、各デバイスは入力テンソルの勾配を前のパイプラインステージに戻します。を前のパイプラインステージに渡します。
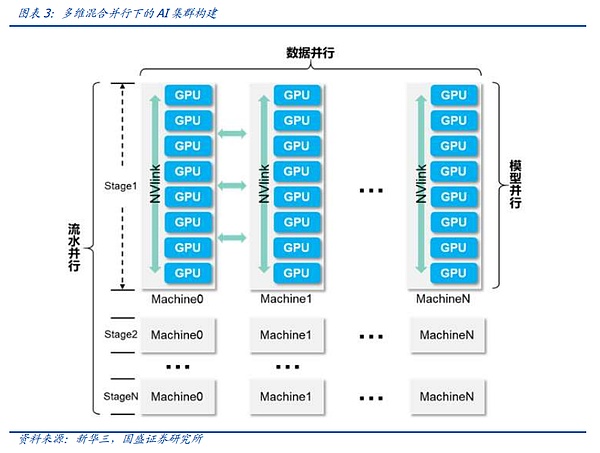
今日のビッグモデルのトレーニングでは、1種類のデータ並列性だけでは存在できません。今日のビッグモデルのトレーニングでは、1種類のデータ並列性だけでは存在できず、頭のビッグモデルのトレーニングでは、多次元ハイブリッド並列性を達成するために、上記の複数の技術を混在させる必要があることがよくあります。実際の接続では、このAIクラスタはいくつかのステージに分割され、各ステージは論理バッチに対応し、各ステージは多数のGPUノードで構成される。これは、多次元ハイブリッド並列の必要性を満たすアーキテクチャです。
並列性が何であれ、それは計算の各ラウンドで行われる必要があります。
2.2ビッグモデル時代のマルチカード相互接続の核心: 同期の正確さ
AIネットワーク・クラスターが引き受ける重要な機能。ネットワーククラスタが引き受ける重要な機能は、異なる分業で異なるグラフィックスカードによって行われたトレーニングの結果をコンピューティングユニット間で整列させ、グラフィックスカードが次のステップを実行できるようにすることです。この作業は逆ブロードキャストとしても知られています。ブロードキャストプロセスは、Reduce、Gatherなどのアルゴリズムを使用して結果を処理するために使用されることが多いため、その後、グローバルブロードキャストはAll to Allと呼ばれます。AIクラスタのパフォーマンスメトリクスで一般的なAll-to-Allのレイテンシは、グローバルな逆ブロードキャストを行うのにかかる時間を指します。
原理的には、各グラフィックスカードにデータを送受信するだけで、データを同期させるリバースブロードキャストを行う方が簡単に思えますが、実際のネットワーククラスタの構築には多くの問題があり、この待ち時間を短縮することが、さまざまなネットワークソリューションの重要な焦点となっています。
最初の問題は、各グラフィックスカードが現在の計算を完了するまでに一貫性のない時間がかかるということです。リバースブロードキャストする前に、同じグループ内の最後のグラフィックスカードがタスクを完了するのを待つと、最初のステップでタスクを完了したグラフィックスカードはアイドル状態で多くの時間を過ごすことになり、コンピューティングクラスター全体のパフォーマンスが低下します。クラスタのパフォーマンスが低下します。同様に、過度に積極的な同期方法は、同期中にエラーが発生し、トレーニングの中断を引き起こす可能性があります。そのため、安定した効率的な同期方法が、業界が追求してきた方向性でした。
今日の観点から、主な同期方法は同期並列、非同期並列、All-Reduceなどに分類することができます。
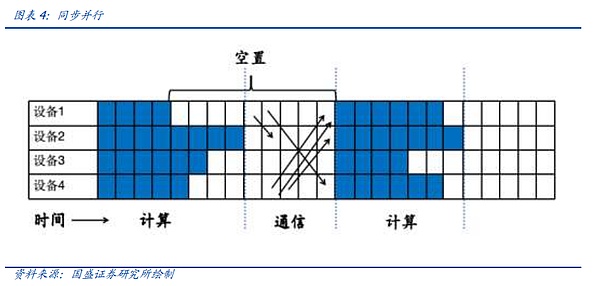
最初の同期並列を見てみましょう、我々は前の記事で述べたアイデアの同期並列は、つまり、現在のユニットでは、すべての計算ユニットは、統一された通信の計算を完了するには、その安定性とシンプルさの利点が、それは計算ユニットの数が多く空きが発生します。下図では、例えば、計算ユニット1が計算を終了した後、それは計算ユニット4が計算を終了し、通信を収集するための時間を待つために待機する必要があり、これは多くの空室が発生し、クラスタの全体的なパフォーマンスを低下させます。
非同期並列処理は、利子増進のような非生成的な大規模モデルに適しています。インタレストプロモーションのような非再生的な大規模モデルを扱う場合は、非同期並列処理が選択されます。 デバイスが順方向計算と逆方向計算のラウンドを完了すると、他のデバイスがサイクルを完了するのを待つ必要がなく、データを直接同期します。これはネットワークモデルの学習では収束せず、大規模モデルの学習には適していませんが、検索モデルや推薦モデルには適しています。
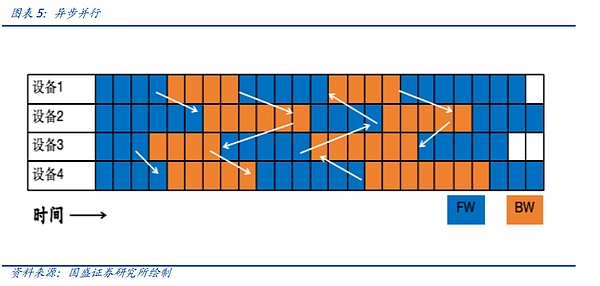
3つ目の分類で、現在最も使われているのがAll-Reduceです。All-Reduce、またはAll-to-All-Reduceとも呼ばれる3つ目のクラスは、すべてのデバイス(All)の情報をすべてのデバイス(All)に要約(Reduce)することです。同じデータが何度も重複して送信される可能性があるため、All-Reduceを直接行うことは、通信リソースの大きな浪費を伴うことは明らかである。したがって、Ring All-Reduce、バイナリツリーベースのAll-Reduceなど、All-Reduceアルゴリズムの多くの最適化バージョンが提案されており、これらはすべて、All-Reduceの帯域幅と待ち時間を大幅に削減することができます。
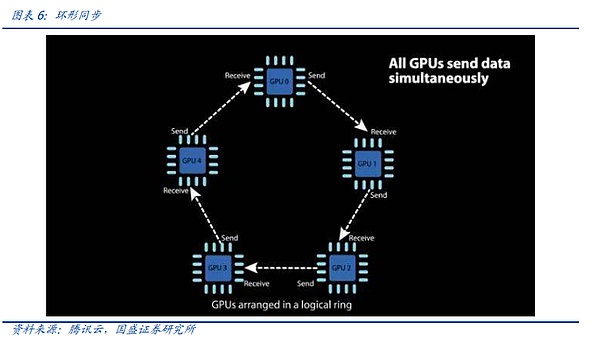
中国のAIリーダーBaiduが発明したRing All-Reduceを例に、分散コンピューティングエンジニアが、絶え間ない反復によって、同期時間をいかに短縮できるかを見てみましょう。
リング・オール・レデュース(リング同期)では、各デバイスは他の2つのデバイスと通信するだけでよく、これは「散布-レデュース(Scatter-Reduce)」と「全集合(All-Gather)」の2つのステップに分けられる。まず、隣接するデバイスに対して複数のScatter-Reduceオペレーションが完了し、各デバイスで集約された完全なデータの一部を個別に取得する。その後、各デバイスは隣接するデバイスを整列させ、複数のAll-Gatherオペレーションを完了させ、各デバイスの完全なデータを構成する。Ring All-Reduceは、帯域幅と待ち時間を削減するだけでなく、ネットワークのトポロジーを単純化し、ネットワークの構築コストを削減します。
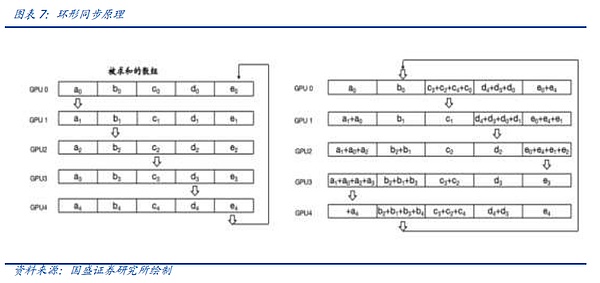
しかし、どのようなアルゴリズムであれ、ネットワーク通信ハードウェアのサポートに依存しています。それが、より広い帯域幅をサポートするためのチップセットのネイティブおよびプロトコルレベルであれ、純粋な銅線接続からNVLink経由の接続への移行であれ、IBプロトコルの導入であれ、RAMはネットワークからより広い帯域幅を引き出す唯一の方法です。あるいは、IBプロトコルの導入、RDMAの爆発的な需要、すべては複雑化する通信と同期のニーズを満たすためです。
この時点で、なぜAIが高密度通信を必要とするのか、その原理的なロジックを予備的に理解しています。まず第一に、小さなモデルの時代から、マルチノードクラスターと分散トレーニングへの急速な切り替えの大規模モデルの時代へと、モデルはコンピューティングの異なるノードに分割され、どのように分割し、どのように同期を確保するかが重要な課題となっています。
すべてのデータが互いに同期していることを確認することです。2.3ビッグモデル時代のシステム工学:監視-要約-革新、反復は常に進行中。
上記では、訓練原理がビッグモデルが通信システムに依存する程度を決定することを説明しました。それとともに、数え切れないほどさまざまで複雑な並列性と同期の要件が、AIクラスタのデータフローを構成しています。 通信ネットワークは、加速する速度や製品の反復、接続性の革新など、このような要件によって推進されていますが、すべての問題を一度で解決できる完璧なクラスタはまだ存在せず、クラスタの安定性は常に最適化されていますが、何百万もの洗練されたデバイスで構成されるシステムは、依然としてブレークポイントや中断に悩まされています。
したがって、大規模モデル通信システムの進化の方向は、大まかに3つに分けることができます。1つは、大規模モデルシステムの監視機能であり、データの流れの大規模モデルのリアルタイムの認識、運用状況をできるようにすることで、障害がタイムリーに検出できるように、プロセスでは、ハードウェアとソフトウェアのネットワークの可視化に基づいて、パケットをキャプチャするための主流の手段となっています。FPGAチップと特殊なソフトウェアを介して、クラスタ内のデータの流れを監視し、知覚のための基本的なツールを提供するように、
最も一般的に使用されるデータパケットキャプチャのソフトウェアの実装は、国内および外国のよく知られている製品は、Wireshark(TCP / UDPを扱う)です、Fiddler(HTTP/HTTPSを扱う)、tcpdump&windump、solarwinds、nast、Kismetなどがあります。Wiresharkを例にとると、その基本的な動作原理は次のとおりです。プログラムは、ネットワークカードの動作モードを "混合モード "に設定します(通常モードでは、カードは自分のMACアドレスに属するパケットのみを処理し、混合モードでは、カードは通過するすべてのパケットを処理します)。Wiresharkによって傍受、再送、編集、ダンプされます。
ソフトウェア パケット キャプチャは、システム パフォーマンスの一部を占有します。システムパフォーマンスの一部を占有します。第一に、NIC はプロミスキャス モードで「ブロードキャスト モード」になり、ネットワークの下位レイヤーが送受信するすべてのパケットを処理するため、NIC のパフォーマンスの一部が消費されます。第二に、ソフトウェアはリンク レイヤーでシリアルまたはパラレルではなくパケットをキャプチャし、パケットを複製して保存するため、CPU とストレージ リソースの一部が消費されます。リソースを消費する。同時に、Wiresharkのようなソフトウェアのほとんどは、システム内の単一のネットワークノードのトラフィックしか監視できず、グローバルネットワークをカバーすることは困難である。
システム全体のパフォーマンスに影響を与えないために、ハードウェアとソフトウェアツールの組み合わせによるパラレルまたはシリアルアクセスが出現しています。 DPI (Deep Packet Inspection)は、パケットに基づくアプリケーション層の情報です。DPI (Deep Packet Inspection) は、パケットのアプリケーション層情報に基づいてトラフィックを検出し、制御する機能です。DPI はアプリケーション層の分析に重点を置いており、さまざまなアプリケーションとその内容を識別することができます。IPパケット、TCPまたはUDPデータストリームがDPI技術に対応したハードウェアデバイスを通過する際、デバイスはメッセージの負荷を深読みすることで再編成・分析し、アプリケーション全体の内容を特定し、その後デバイスによって定義された管理ポリシーに従ってトラフィックを処理します。DFI (Deep/Dynamic Flow Inspection)は、異なるタイプのアプリケーションがセッション接続またはデータフローの異なる状態に反映される、フロー動作に基づくアプリケーション識別技術を使用します。 DPIテクノロジーは、きめ細かく正確な識別ときめ細かな管理を必要とする環境に適しており、DFIテクノロジーは、非常に効率的な識別とずさんな管理を必要とする環境に適しています。
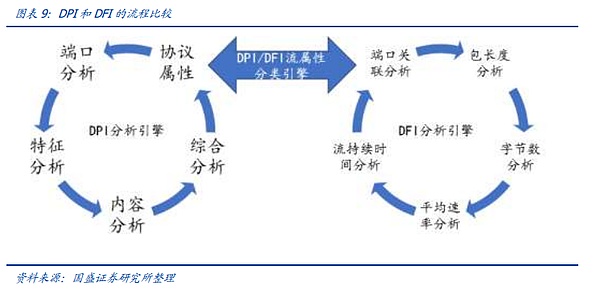
DPI/DFIは次のように構成されています。VastDepthのDPIハードウェアとソフトウェア製品を例にとると、通信ネットワークのネットワークノードの各レイヤーに配置することができ、同時にSaaS/PaaSを通じて各レイヤーの監視ノードのデータ収集、分析、プレゼンテーションを完了することができます。 DPIハードウェアは通信の物理レイヤーで直列または並列接続され、パケットをミラーリングすることでほぼ無損失のネットワーク監視を実現し、DPIソフトウェアはDPIハードウェアに組み込まれています、DPIソフトウェアはDPIハードウェア、スタンドアロンサーバー、またはスイッチ/ルーターに組み込まれ、ネットワーク監視を可能にします。

監視問題を解決した後、大型モデルシステムエンジニアリングの反復経路は基礎があり、前述したように、実際の運用では、システムの運用効率と安定性のバランスに注意を払うことがより必要であり、一方では、我々はReduce方法があります。最初のReduceメソッドの最適化、パラレルメソッドの技術革新など、新しいトレーニング方法や理論を作成するには、分散トレーニングの技術革新の底部、しかし、技術革新の底部は、常に関連するハードウェアのサポートを必要とし、スイッチのスループットが大きく、より適切なスイッチングプロトコル、より安定した、安価な通信デバイスは、システムの大きなモデルは、常にリングのアップグレードに不可欠になります。
3.通信プロトコルの競争と反復:AIデータストリームを運ぶ言説
前節で、私たちは以下のことを体系的に説明しました。前節では、AIクラスターにおける通信の主な役割が何であるかを系統的に説明したが、本節では、通信システム全体の最も基本的な部分を構成する通信プロトコルを系統的に紹介する。
直感的には、通信システムは主にスイッチ、光モジュール、ケーブル、NICなどの物理ハードウェアで構成されているが、実際には、通信システムの確立の本当の決定、物理ハードウェアの中を流れる通信プロトコルの動作と性能特性である。通信プロトコルは、コンピュータネットワークでは、データの円滑かつ正確な伝送を確保するために、双方の間の通信は、一連の合意に準拠する必要があります。これらの規約には、データのフォーマット、エンコード規則、伝送速度、伝送ステップなどが含まれます。
AI時代には、通信プロトコルの分類は主に2つに分けられ、1つ目は演算ノード内の演算カード間の通信に高速プロトコルを使用し、このクラスのプロトコルは高速、強い閉鎖性、弱い拡張性などの特徴があり、各グラフィックスカードメーカーのコア能力の障壁の1つであることが多く、そのレート、インターフェースなど。レート、インターフェースなどはチップレベルでサポートする必要がある。プロトコルの2番目のタイプは、演算ノード間を接続するために使用され、プロトコルのこのタイプは、低速、スケーラビリティなどの特性を持って、プロトコルの2番目のタイプは、現在2つの主要な、InfiniBandプロトコルだけでなく、プロトコルのRoCEファミリの下にイーサネットがあり、プロトコルのこのタイプは、ノードの伝送容量を越えてデータを確保するためだけでなく、メガクラスタの基礎を構築するだけでなく、スマートコンピューティングユニットは、データセンターにアクセスするために提供する。ソリューションです。
3.1ノード内通信 - 大規模ベンダーの中核となる障壁とムーアの法則への期待
3.1ノード内通信 - 大規模ベンダーの中核となる障壁とムーアの法則への期待
3.2ノード内通信 - 大規模ベンダーの中核となる障壁とムーアの法則への期待
イントラノード通信は、1つのサーバー内のグラフィックスカード通信プロトコルで、同じサーバー内のグラフィックスカード間の高速相互接続を担っています。
まず、最も古いPCIeプロトコルから見てみましょう。 PCIeは一般に公開されている汎用プロトコルであり、PCIeプロトコルを介して従来のサーバーPCの異なるハードウェアを接続します。サードパーティが組み立てた演算サーバーでは、グラフィックスカードは、PCIeスロットとマザーボードを通じて、従来のサーバーと同様にまだ互いに接続されています。マザーボード上のPCIeスロットとPCIeライン。
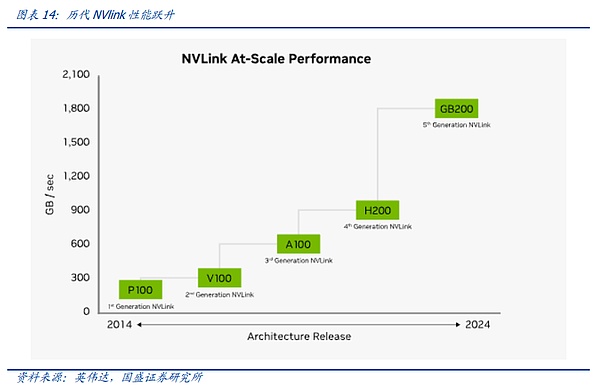
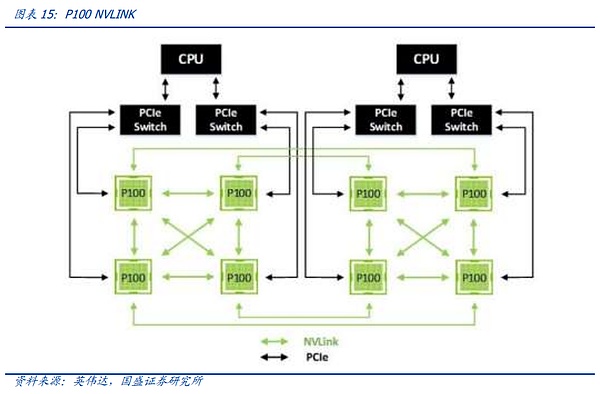
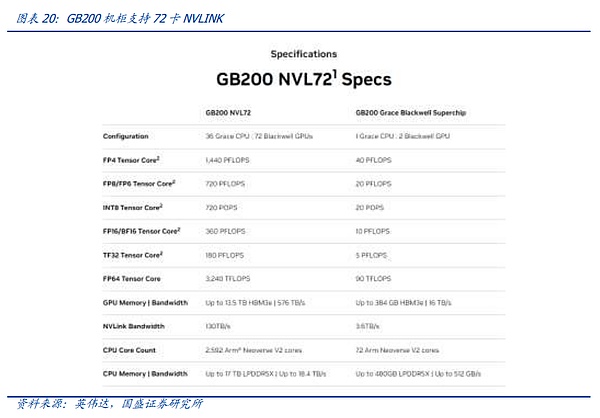
PCIeは最も広く使用されているバスプロトコルです。 PCIe バスツリートポロジーとエンドツーエンドの転送方式により、接続数と速度が制限され、PCIeスイッチが誕生しました。 しかし、前述のように、モデル規模が徐々に拡大し、NPU間の同期がとれれば、NPU同士の通信が容易になります。しかし、上述したように、モデル規模が拡大し、NPU間の同期ループが複雑になると、レートが低く、動作モードが最適化されていないPCIEでは、ビッグモデル時代の要求を満たすことができなくなるため、ビッグモデル時代には、主要なグラフィックスカードメーカーの独自プロトコルが急速に台頭しています。 業界で最も注目され、最も速く進化したプロトコルは、NVIDIAが提案した高速GPUインターコネクト プロトコルであるNV-Linkプロトコルであると私たちは考えています。 従来のPCIeバス プロトコルと比較して、NVLINKは3つの主要な領域で大きな変更を加えました。1)限られたチャネル アクセスの問題を解決するためのメッシュ トポロジーのサポート。限られた問題。2)ユニファイド・メモリにより、GPUが共通のメモリ・プールを共有できるため、GPU間のデータ・コピーの必要性が減り、効率が向上する。3)ダイレクト・メモリ・アクセスにより、CPUが関与することなく、GPUが互いのメモリを直接読み込めるため、ネットワーク・レイテンシが短縮される。さらに、GPU間の不均一な通信の問題を解決するために、NVIDIAは、スイッチASICに似た物理チップであるNVSwitchも導入しました。NVSwitchは、NVLinkインターフェイスを介して複数のGPUを高速で相互接続し、高帯域幅のマルチノードGPUクラスタを作成します。 NV リンクの歴史を振り返ると、ノード間 NVSwitch が GPU を相互接続する最も効率的な方法であることがわかります。 ノード間の NV-Link 相互接続は、グラフィックス カード間の同期の必要性が変化するにつれて、正確に徐々に反復されてきたことがわかります。NV-Linkの最初の世代は、Pascalアーキテクチャで登場し、NVIDIAは、ユニバーサルPCIEスイッチと同様に、PCBボード上の高速銅線を介して、単一のサーバー内部リンク8カードサーバーで、我々は、下図の接続を介して見つけることができます、8つのGPUの間に、4つのグラフィックスカードの内部X型接続に重畳されたグラフィックスカード外部の大きなリングを介して、開始点として、任意の1つに。グローバルデータの整列は最短経路で行うことができます。 しかし、個々のカードの性能が拡大するにつれて、スループットが増加し、グラフィックカードが互いに同期する方法が増加します。そのため、NVLINKの第3世代に相当するAmpereアーキテクチャにおいて、NVIDIAは、NV-Linkレートと柔軟性をさらに向上させるために、第1世代のNV-Linkスイッチ専用チップセットを導入しました。 しかし、PascalアーキテクチャからAmpereアーキテクチャへの更新では、以下のようなことが起こりました。NV-LINKは、主にチップ内部チャネルの反復を通じて、定期的な更新のリズムを維持し、NV-Linkスイッチチップの反復は、更新の速度を達成するために、時間の期間中に、NVIDIAはまた、ハイエンドのCの一部のニーズを満たすために、ゲームグラフィックスカード用のNV-Linkブリッジを立ち上げました。 A100からH100へのアップデートで、NVIDIAはNV-Link Switchで一歩前進しました。NVIDIAは、NV-Linkの進化の第一歩を踏み出しました。 大規模モデルの需要が出始めたとき、大きなデータサイズとモデル量により、NV-Linkインターコネクトでは対応することが難しくなりました。 ユーザーは、モデルをスライスして、トレーニングやアライメントのために異なるサーバーにロードする必要があり、サーバー間の通信速度の低下は、モデルトレーニングの効果に直接影響しました。私たちは、最速の通信プロトコルで相互接続できるグラフィックカードの数をHB-DOMINと呼んでいます。モデル・パラメーターがますます大きくなるにつれて、HB-DOMINは同世代のチップ内でのモデル・トレーニング能力の重要な決定要因になります。 このような状況において、NVIDIAのNV-LINKは、Hopperアーキテクチャの進化の第一歩を踏み出し、外部専用スイッチを介してより多くのNV-LINKスイッチチップをホストすることにより、既存のグラフィックスカードのHB-DOMINを拡張しました。 しかし、Hopperアーキテクチャの対応するNV-LINKは、GH200 SuperPODとGH200 SuperPODと同様に、サーバー間で256枚のグラフィックスカードの相互接続を可能にしました。 ブラックウェル・アーキテクチャの時代には、NVIDIAは正式にHB-ドミンの拡張を完成させました。NVIDIAはNVLINKの拡張経路を正式に完成させ、4NMの最新世代のNV-Linkスイッチングチップのリリースに伴い、NVIDIAは公式の拳製品であるGB200 NVL72を発売しました。 NVIDIAは、1つの筐体内でNVlink+銅の1層の接続を通じて、より低コストで費用対効果の高いHB-DOMIN数に到達するという目標を達成し、まさに一歩を踏み出しました。 私たちは、最新世代のNV-LINKに加えて、ノード相互接続を再導入しました。そして、イントラノード通信の拡張は、算術の時代におけるムーアの法則の継続に不可欠になったとさえ言えるでしょう。イントラノード通信プロトコルを反復的かつ低コストで実装することは、「通信の壁」や「メモリの壁」に対処するための今日の最善のソリューションです。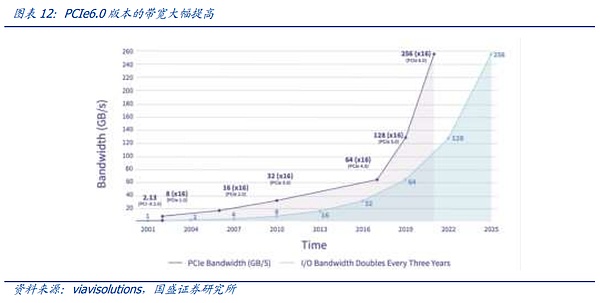
PCIeはエンド・ツー・エンドのデータ転送リンクを使用し、PCIeリンクの両端でアクセスできるデバイスは1つだけで、識別されるデバイスの数は限られているため、多数のデバイスが接続されるシナリオや高速データ転送を必要とするシナリオを満たすことができず、PCIeスイッチが誕生しました。PCIeスイッチは、接続と切り替えの両方の機能を備えており、PCIeポートがより多くのデバイスを認識し接続できるようにすることで、チャネル数不足の問題を解決し、複数のPCIeバスを接続してマルチデバイス通信用の高速ネットワークを形成することができます。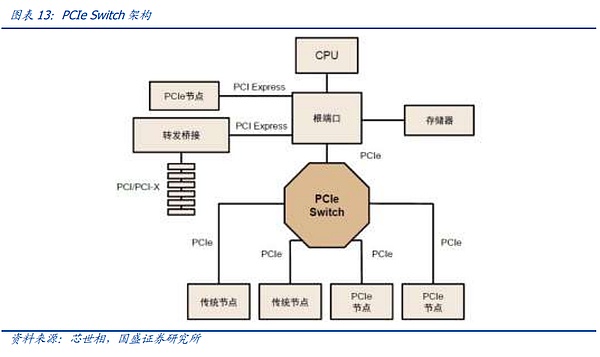




クラウドとの自動同期
クラウド・サービスとの同期に手動での操作は必要ありません。同時に、GH200のリリース時点では、モデルのパラメータはまだ1兆レベルまで膨張しておらず、Metaの調査結果によると、1兆のパラメータの下では、100を超えると、HB-ドミンの膨張の限界効果が加速度的に減少する。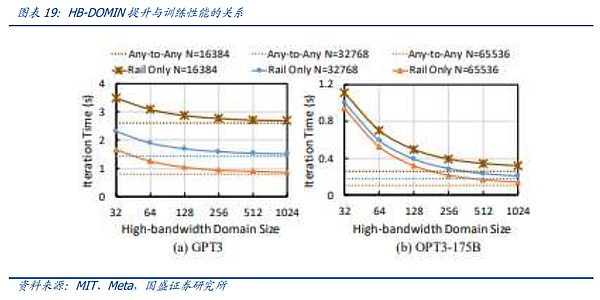
現在、NV-LINKの最大の競争相手は、汎用グラフィックス分野でNVIDIAの最大の競争相手であるAMDです。 NVIDIAのように、オープン・ネットワーク・プロトコルを最も支持してきたAMDでさえ、ノード内相互接続に独自のプロトコルを使用しています。

今日、Infinityは、NVIDIAの「Infinity Fabric」とNVIDIAの「Infinity Fabric」を比較しています。Infinity FabricとNVLINKの差はまだ大きく、AMDは専用スイッチングチップ、マルチカード相互接続、プロトコル補完の点で追いつくにはまだ長い道のりがあります。このことは、現在の真っ向勝負の汎用演算競争が、チップ設計の単一リンクからノード間通信のリンクへと徐々に拡大していることも示しています。
まとめると、演算においてノード間通信の重要性が増しており、同時にHB-DOMINの拡大により「演算ノード」も徐々に拡大していることが、AIクラスタ全体におけるノード間プロトコルの「上昇気流」の背景にあると考えます。これが、AIクラスタ全体の中でのノード間プロトコルの「上方浸透」の背景にあり、同時に、ノード間プロトコルとそのホスティングハードウェアの体系的な圧縮に依存することも、AI演算の将来にとってムーアの法則を実現する道であると信じています。
3.2ノード間通信プロトコル:クローズドとオープンの戦い
さて、ノードの外に目を向けて、グローバルな演算クラスタを構成する主なプロトコルを見てみましょう。主要プロトコルのクラスタ接続性今日の演算センターでは、NPUは徐々に100万台規模に移行しており、演算ノードまたはHB-DOMINと呼ばれるノードが加速度的に拡大しているにもかかわらず、ノード間の接続性は依然としてグローバルAI演算を構成する基礎部分となっています。
現在の観点から、ノード間接続プロトコルは、主にInfiniBandプロトコルとイーサネットファミリーの中のROCEプロトコルファミリーに分かれています。スーパーコンピューティングノード間の相互接続の中核はRDMA機能にある。従来のCPUベースのデータセンターでは、送信にはTCP/IPプロトコルが一般的で、送信側のメモリからデータが送信された後、送信側のデバイスのCPUでエンコードされて受信側のデバイスのCPUに送られ、デコード後にメモリに格納される。このプロセスは、データが複数のデバイスを経由し、何度も符号化と復号化を行うため、高い待ち時間が発生します。待ち時間は、コンピューティングカード間の同期にとって最も重要な要素であるため、グラフィックスカード間の相互接続の需要では、CPUをバイパスして、メモリ間のリモートダイレクトメモリアクセス(RDMA)を実現することが、AIクラスタの接続のための厳格なニーズとなっています。
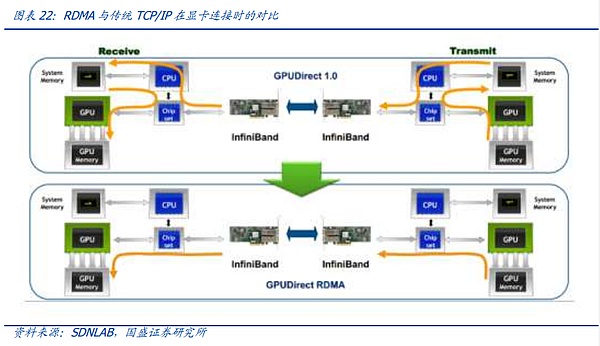
この文脈において、NVIDIAが主導する現在のRDMA対応IEEE 802.168.1標準は、AIクラスタ接続のための最も広く採用されている標準となっています。この文脈では、現在のNVIDIAがサポートするIBイーサネットの下でRDMAをサポートするプロトコルROCEファミリーが唯一の選択肢となっており、これら2つのプロトコルの特徴的な機能により、ノード間プロトコル競争全体がエキサイティングなものとなっています。
IBプロトコルの出現は1999年まで遡ることができます。PCIバスの貧弱な通信能力が徐々に様々なデバイス間の通信のボトルネックとなり、このような状況の中で、Intel、Microsoft、IBM、いくつかの大企業がFIO開発者フォーラムを設立し、NGIOフォーラムが統合されました。このような状況の中、インテル、マイクロソフト、IBM、その他いくつかの大手企業はFIO Developers ForumとNGIO Forumを設立し、合併してInfiniBand Trade Association (IBTA)を設立し、2000年にIBプロトコルフレームワークの最初のバージョンを発表しました。1999年に設立されたスイッチング・チップ企業のMellanoxもIB陣営に加わりました。
IBはその設立当初から、PCIバスの制限を回避してより高速なアクセスを可能にするRDMAの概念を開拓しましたが、長くは続かず、2022年には、Intel、Microsoft、およびその他の大手企業がIBコンソーシアムから離脱し、前述のPCIEプロトコルを採用すると発表しました。2022年、インテル、マイクロソフト、その他の大企業は、先に述べたPCIEプロトコルを支持してIBコンソーシアムを脱退すると発表し、IBは衰退していった。しかし2005年、ストレージ・デバイス間の通信需要の高まりを受け、IBは再び上昇期に入り、その後、世界的なスーパーコンピューティングのセットアップに伴い、接続にIBを使用するスーパーコンピュータが増え始めました。その過程で、IBへの不滅のコミットメントと関連する買収を頼りに、メラノックスはチップ会社からNIC、スイッチ/ゲートウェイ、テレマティクス・システム、ケーブルおよびモジュールのフルレンジへと拡大し、世界トップクラスのネットワーキング・プロバイダーとなり、2019年には、Nvidiaがインテル&マイクロソフトを抑えて69億ドルのオファーでメラノックスの買収に成功した。/strong>

。
ビッグモデルの時代に入って以来、世界のデータセンターは急速にスマートコンピューティングにシフトしています。そのため、設備への主要な新規投資はRDMA接続を必要とします。しかし、現在の競争環境は、以前のRoCE V2やIB競争とは様変わりしています。 NVIDIAが世界のグラフィックス分野で絶対的なリーダー的地位を占めているため、NVIDIAグラフィックスカードはIBにはるかに適しており、最も明白な点は、メラノックスのスイッチに配備されているSharpプロトコルです。
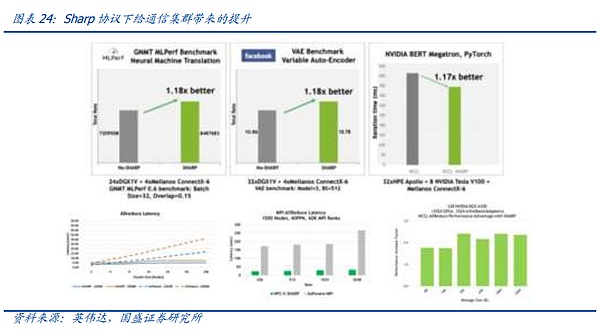
前述のように、AIコンピューティングではグラフィックスカードとグラフィックスカードの間で多数の複雑なReduce通信が必要とされるため、これはAI通信システムのエンジニアリングにおいて解決すべき中核的な問題でもあります。 メラノックスのスイッチ製品では、NVIDIAの協力を得て、スイッチングチップにコンピュートエンジンユニットを革新的に統合しており、関連するReduce計算をサポートすることができるため、GPUが以下のことを行うのに役立ちます。このため、GPUの負荷を軽減することができますが、関連する機能にはGPUメーカーの協力が必要です。
これは、通信プロトコルのAI時代において、グラフィックスカードベンダーの背面のコアは、闘争を語る権利となっており、現時点では、NVIDIAのサポートを受けたIBプロトコルは、より良い競争上の優位性を占めていることを示しています。従来のイーサネット・ベンダーは、強力なチップ・サポートがないため、一部の機能においてやや弱い。しかし、AMDが主導するハイパー・イーサネット・アライアンスの出現により、この状況は徐々に逆転していくと予想されます。

2023年7月。7月19日、AMD、Broadcom、Cisco、ARISTA、Meta、Microsoft、その他コンピュートチップ、ネットワークサイド、ユーザーサイドの主要ベンダーが共同でHyper-Ethernet Allianceを設立しました。これは、イーサネットの上に、IBの性能を上回る、つまりIBと競合する、完全にオープンでより柔軟なネットワークプロトコルを構築することを目的として設立されたと私たちは考えています。
ハイパーイーサネット・アライアンスは、イーサネットの上に、IBを凌駕する、完全にオープンで柔軟で高性能なネットワークプロトコルを構築するために設立されました。

AMDはハイパーイーサネット・アライアンスのコアメンバーとして、MiTACプラットフォームの開発に大きく貢献しています。ハイパー・イーサネット・アライアンスの中核メンバーとして、同社はMi300シリーズの発表会において、グラフィックスカードのバックエンド接続は無条件でイーサネットになり、ノード内相互接続に使用されるInfinity Fabricプロトコルはイーサネット・ベンダーにも開放されると述べました。AMDとブロードコムおよびUECアライアンスの他のメンバーとの協力の進展が徐々に加速するにつれて、UECアライアンスもまた、Nカード+IBのような一連の互換性と協力体制を本当に形成することが期待され、NVIDIAに課題をもたらすだろうと判断している。しかし、そのプロセスは長くなる運命にあり、シングルカードのコンピューティングパワーのAMD側が追いつき、次にスイッチングチップの進歩のBroadcom側が追いつき、そして異なるベンダー間の開放性と協力に至るまで、まだ多くの道のりがあります。
概要
、ノード通信プロトコルの紛争は、徐々にどのような契約を使用して、話す権利に紛争の原則から進化している、より多くのGPUの話す権利の拡張であり、Nvidiaは話す権利IBを介して全体のリンクを展開することを望んで、顧客が受け入れたい。よりオープンなIBは、業界の競争は、通信プロトコルの継続的な進化を推進していきます。
4.ネットワークハードウェアの革新はAIとともにどこへ向かうのか?
前節では、AIの需要がRDMA機能の進化とボリュームを促進していることを説明しましたが、同様に、ネットワークハードウェアの領域でも、AIの新たな需要は、伝送メディア、スイッチ、ネットワークアーキテクチャ、さらにはデータセンターの全体的な形状に至るまで、レートの更新以外の変化をもたらしています。データセンターの全体的な形が変わりつつある。
4.1光、銅、シリコン:伝送媒体の議論はどこへ向かうのか
近年、人間のデータ量が急速に拡大し、伝送速度が指数関数的に向上しています。ワイヤレスネットワーク、固定回線ネットワーク、および他の通信側の最初の光の波を銅の後退に先駆け、最も初期のダイヤルアップインターネットから、その後、家庭への光ファイバ、さらには現在FTTR、銅の緩やかな交換のための光ファイバケーブルの公式ラウンドへ。
データセンターの内部では、光が銅の後退のプロセスも進行中であり、光モジュール、AOCなどによって、光通信システムは徐々にDAC、AEC、および高速伝送の背面である銅伝送システムの他のコンポーネントに置き換えられ、銅メディアの減衰は、より劇的な必然的な物理法則です。AIがもたらす多様なニーズがなければ、光伝送は徐々にキャビネットの内部に浸透し、サーバーのポートレートが時間の経過とともに増加するにつれて、最終的には全光データセンターを形成するでしょう。
しかし、AIの出現は、「銅の背に光を」このプロセスにねじれをもたらし、または市場にある種の混乱を生じさせた。その背後にある核心的な理由は次のとおりです。AI は通信システムの複雑さとコストの非世代的な線形成長をもたらし、需要の指数関数的な増加を前に、高レートの光モジュールはますます高価になります。したがって、魅力の現在のレートでより費用対効果の高い銅ケーブルが徐々に増加し、冷却と改善の他のサポートコンポーネントに重畳しながら、グラフィックスカードのメーカーは、銅のできるだけ多くのコンピューティングユニットの圧縮が単一のキャビネットの範囲内に到達することができるようになります。

この背景には、AIの時代であることが容易にわかります。支出の増加により、光-銅の議論の核心は、現在の2-3年の節目において、レートのエスカレーションからコスト第一に変わりました。一方、通信システムの複雑さが加速しているため、シンプルさと低故障率は、メディアを選択する顧客にとって重要な考慮事項となっています。
長距離クロスサーバー伝送:光モジュールが唯一のソリューションであり、コスト削減とシンプルさが技術革新の方向です。
銅線伝送距離の制限により、いわゆる「光が出て銅線が入る」ことは短距離伝送でしか起こりえず、5メートル以上の伝送距離、つまりクロスサーバーやクロスコンピューターノード伝送に直面した場合、光伝送が唯一の選択肢であることに変わりはありません。しかし現在では、従来の速度アップに対する顧客の関心に加え、コストと故障率(デバイスの複雑さ)の追求がますます急務となっており、光通信業界の今後のアップグレードの方向性も後押ししています。
LPO/LRO:LPOは従来のDSPをリニアダイレクトドライブ技術に置き換え、その機能をスイッチングチップに統合し、ドライバとTIAチップのみを残します。LROは、一方の端で従来の光モジュールを使用し、もう一方の端でLPO光モジュールを使用する過渡的なソリューションであり、その結果、より高い顧客受容性が得られます。
シリコンオプティカル:シリコンオプティカルは、ディスクリートデバイスの光エンジンの光モジュールの一部を作る技術の成熟を通じて、シリコンチップに自動統合することができ、大幅なコスト削減を達成することができます。LPOとシリコンオプティカルは、業界で最も急速に進歩しているコスト削減イノベーションの2つだと考えています。
薄膜ニオブ酸リチウム:ニオブ酸リチウムは、信頼性の高い材料の中で、電気光学係数(キュリー点と電気光学係数を考慮)において最良の選択です。薄膜プロセスにより電極距離を引き下げ、電圧を下げることで帯域幅対電圧比を向上させている。他の材料に比べ、広帯域、低損失、低駆動電圧、その他多くの光電子学的利点がある。現在、薄膜ニオブ酸リチウムは主に高レートシリコン光変調器に使用されていますが、我々は、薄膜ニオブ酸リチウム変調器の使用は、より良い性能を達成するために1.6T、3.2Tにすることができると信じています。
CPO:CPOとは、光モジュールがスイッチマザーボードに直接封入されることを指し、スイッチマザーボードの放熱を共有できると同時に、スイッチマザーボード内の電気信号の伝送距離を短縮することができますが、現在、光モジュールのAIセンターは生鮮品に属するため、共通の封入の維持は困難です。しかし、現時点では、AIセンターの光モジュールは生鮮品であるため、共同封止後のメンテナンスが難しく、CPOの顧客認知度はまだわからない。
キャビネット内の接続:コストと安定性の二重の利点は、銅は、選択の短期的および中期的な利点であり、長期的な上昇率で、銅に光がまだ起こるでしょう。
DAC:ダイレクトアタッチケーブル、つまり高速銅ケーブルは、超高速接続内の短い距離に適応することができ、3メートル以下の現在の市場の主流の800G DACの長さは、費用対効果の高いキャビネット内接続ソリューションです。
AOC:アクティブ光ケーブル、アクティブ光ケーブル、つまり、光モジュールと光ファイバのサブアセンブリの統合の早期完了の両端は、システムを構成し、従来のマルチモードまたはシングルモード光モジュールに比べて伝送距離が短いですが、コストが低く、短い距離の接続オプションの後にキャビネット内の銅ケーブル伝送の限界を超えています。これは、銅線ケーブルの限界を超えたキャビネット内の接続に最適な短距離接続です。
シリコンの進化について、現在主流の考え方には主にチップレットとウェハースケーリングの2種類があります。シリコンの単一ピースでより多くの通信開発を行い、計算効率を最大化し、我々は以前の "AI演算ASICの道 - イーサネットマイナから始まる "の深さで持っているコンテンツのこの部分は、この記事では詳細な紹介を繰り返すことはありません。
要約すると、伝送媒体の反復と競争は、需要に従うと、現在の需要は非常に明確であり、MOEや他の新しいトレーニングフレームワークでは、数兆ドルの規模に向かってモデルパラメータは、どのように費用対効果を達成するために、より潜在的に強力なシングルノード演算を達成するために、または拡張する。HB-DOMIN "ドメインの数は、モデルのカットが訓練効率の低下につながる、あまりにもきめ細かくする必要がないように、それは光、銅、またはシリコンの底であるかどうか、常にこのルートに取り組んでいます。
4.2スイッチの革新:地平線上の光スイッチ
ネットワークの核としてのスイッチ
スイッチは、ネットワークの核となるノードとして、通信プロトコルを伝送するための中核的なコンポーネントであり、今日のAIクラスタでは、スイッチもより複雑なタスクを担うようになってきている。例えば、前述のメラノックスのスイッチのように、SHARPプロトコルに部分的に合わせることで、AIの運用を加速させることができる。
しかし一方で、今日の電気的スイッチがより強力になり、反復速度が依然として安定している一方で、純粋な光スイッチングが新たなトレンドになりつつあるようです。このため、光スイッチング・トレンドの背景には、主に2つの理由があると考えている。1つ目は、AIプレーヤーの巨大化。2つ目は、AIクラスターの加速的な拡大です。
光スイッチングシステムは、電気スイッチングシステムと比べて、電気チップを取り除き、光レンズを使ってスイッチの内部に入ってくる光信号を屈折させ、変換されないように分散させ、対応する光モジュールに通す。電気スイッチと比較して、光スイッチは、光電変換プロセスの排除に起因するため、消費電力、遅延などが低くなり、同時に、それは、ネットワークレイヤの数の最適化のための電気スイッチチップの容量の制限を受けないため、単一のスイッチでカバーすることができるユニットの数も増加しているが、逆に、光スイッチの使用は、ネットワークアーキテクチャが同じ時間に適応できるように特別に設計する必要がありますが、光スイッチは、クラスターの確立は、断片的に拡張することはできませんが、1回限りの拡張のみ同時に、光スイッチのクラスタが確立されると、それは断片的な拡張を実施することはできません、ネットワーククラスタ全体の1回限りの拡張のみ、柔軟性も低いです、さらに、現在の段階で光スイッチは、普遍的なバージョンはありません、あなたは、自己研究またはカスタマイズされた設計をする必要があり、しきい値は高くなります。
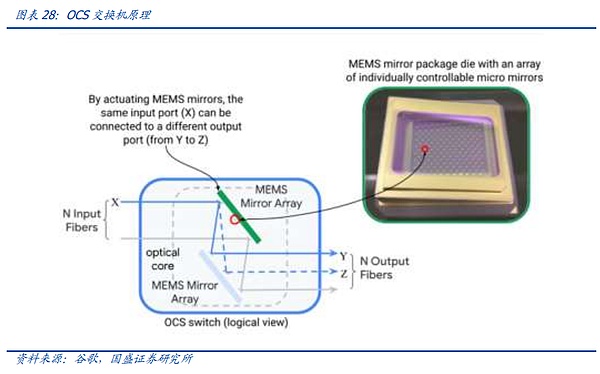
しかし、AI競争が正式に巨人を殺すに入った。巨人が所有するAIクラスターの規模は、旅の後半に急速に拡大しており、巨人は成熟した投資計画、ネットワークアーキテクチャの自己研究能力、および十分な資金を持っているので、ノードの規模が拡大し続けているように、今日、Googleなどの巨大な顧客は、OCSシステムの研究開発および展開を加速している。
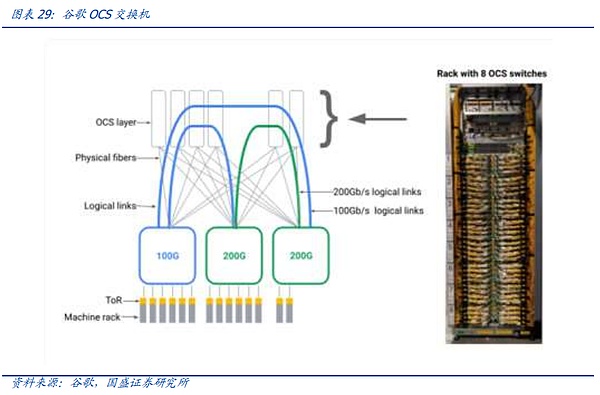
そして、伝統的な電気スイッチングコンポーネントに話を戻すと、今日の電気スイッチングは、プロトコルに加えて、電気スイッチの技術革新が進んでいます。スイッチの技術革新は、上記のプロトコル部分に加えて、プロセスの反復、機能革新などを含むチップ部分に、より焦点を当てた。同時に、ブロードコムなどのスイッチベンダーは、自社と顧客のバインディングの使用で異なる下流の顧客チップの独自のIPの美徳によって、強くなり、戦いの派閥の通信プロトコルと組み合わせることで、AIの時代には、スイッチ業界は正式にチップの同盟になっています。全面的な競争だ。
4.3ネットワークアーキテクチャの革新:リーフリッジの後は?
ネットワークアーキテクチャは、プロトコルやハードウェア以外の通信システムの重要な部分です。 アーキテクチャは、サーバー内のデータがどのような経路で送信されるかを決定します。優れたネットワークアーキテクチャは、遅延を減らし安定性を確保しながら、全領域でデータトラフィックにアクセスできるようにします。同時に、ネットワーク・アーキテクチャは、容易なメンテナンスと拡張のニーズを満たす必要もあるため、アーキテクチャは、紙の設計から物理的なエンジニアリングに至るまで、通信システムの重要な部分である。
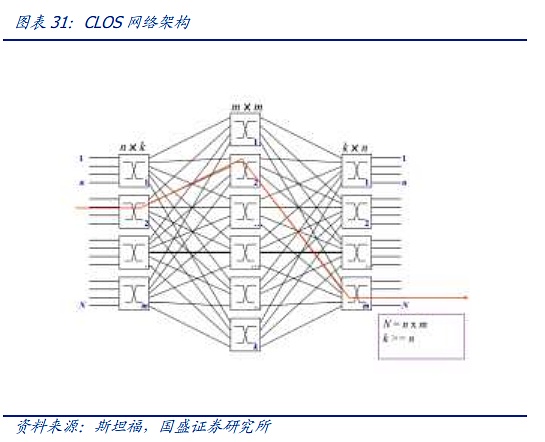
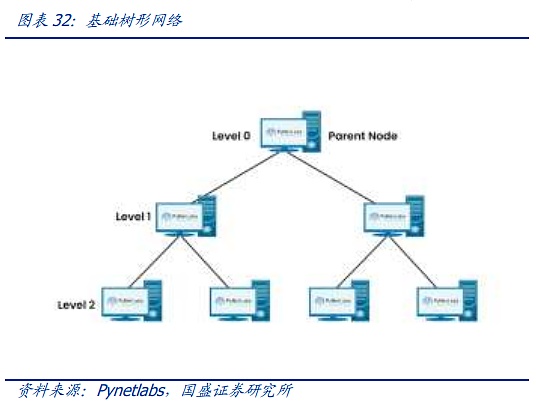
現代社会のネットワークアーキテクチャは、マトリックス図構造の電話時代から、現代のネットワークのためのClOSネットワークモデルにインフラストラクチャを構築するために、CLOSアーキテクチャの中核は、多数の小規模、低コストのユニットで、複雑な大規模ネットワークを構築することです。CLOSモデルに基づいて、スター型、チェーン型、リング型、ツリー型、その他のアーキテクチャなど、さまざまなネットワークトポロジが徐々に進化し、その後、ツリー型ネットワークが徐々に主流アーキテクチャとなっています。

ツリー・アーキテクチャは3世代にわたって進化してきました。第1世代は最も伝統的なツリー・アーキテクチャで、各レイヤーの帯域幅が厳密に2:1に収束していることが特徴です。スイッチへのダウンストリーム機器のアクセスは、100Mのデータストリームへのすべての方法固定出力、クラウドコンピューティングに直面して、より小さなデータストリームの到着前に、このアーキテクチャはまだ対処することができますが、インターネットとクラウドコンピューティング時代の到来に伴い、帯域幅の収束は、トラフィック伝送要件を満たすことができないので、一種の "ファットツリー "と呼ばれる改良されたアーキテクチャは、徐々にデータセンターで使用されています。そのため、データセンターでは「ファットツリー」と呼ばれる改良型アーキテクチャが徐々に使用されるようになっている。ファットツリーアーキテクチャは3層のスイッチを使用し、そのコアコンセプトは、多数の低性能スイッチを使用して大規模なノンブロッキングネットワークを構築することです。どのような通信パターンでも、ネットワークカードの帯域幅に到達するための経路は常に存在しますが、上位レイヤーのスイッチの収束率をできるだけ低く保つために、上位レイヤーではより高度なスイッチが使用されます。
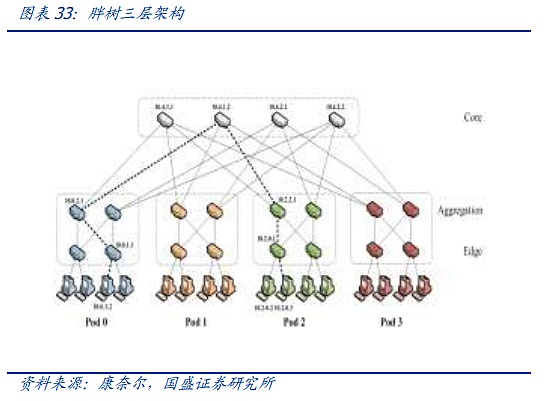
ファットツリーアーキテクチャは、現代のデータセンター接続の基盤を提供しますが、帯域幅の無駄、スケーリングの難しさ、大規模なクラウドコンピューティングをサポートすることの難しさといった問題も抱えています。しかし、無駄な帯域幅、スケーリングの難しさ、大規模なクラウド・コンピューティングをサポートすることの難しさなど、固有の問題があります。ネットワークの規模がますます大きくなる中で、従来のファットツリーの欠点はますます明らかになってきています。
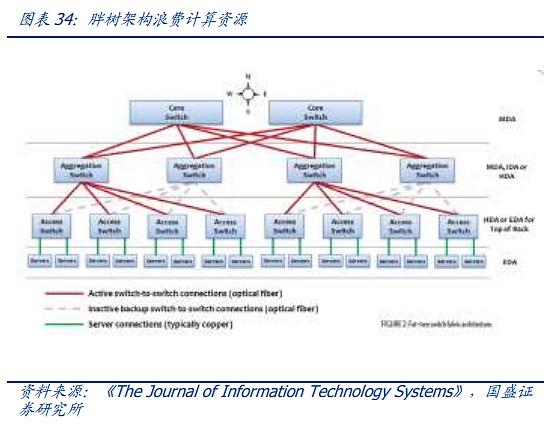

ファットツリーを基礎に、現在の先進的なデータセンターとAIクラスターはリーフリッジ(スパインリーフ)アーキテクチャを採用し、ファットツリーと比較して、リーフリッジは平坦化に重点を置いています。複雑な3層のファットツリーと比べ、各下位スイッチ(リーフ)は各上位スイッチ(スパイン)に接続し、フルメッシュトポロジーを形成する。リーフ層はサーバーや他のデバイスに接続するためのアクセススイッチで構成される。スパイン層はネットワークのバックボーンであり、すべてのリーフを接続する役割を担う。この構成では、任意の2つの物理サーバ間のデータ転送は、リーフとスパインスイッチを通過するノードの数は、東西トラフィックのベアリングと遅延を確保するために固定されているだけでなく、スパインスイッチの拡張を通じて、非常に高価なコアレイヤスイッチの広範な使用を避けるだけでなく、いつでもネットワーク全体を拡張するために、スパインレイヤスイッチの数を増やすことによって。
今日、多くの利点を持つリーフリッジは、主流のAIクラスタおよびヘッドデータセンターの標準的なアーキテクチャとなっていますが、1つのAIクラスタ内のノード数が劇的に拡大し、AIトレーニング中の待ち時間が極度に追求されるにつれて、ファットツリーアーキテクチャのいくつかの問題が表面化し始めています。strong>第一に、規模が劇的に拡大した場合、スイッチの容量上限更新がグラフィッククラスタの進化速度に対応できるかどうか。第二に、何百万ものコンピュート ノードの相互接続に直面して、リーフ リッジはまだ費用対効果があるのか。
リーフリッジの上記の2つの質問は、ネットワークアーキテクチャーレベルでの革新にもつながりますが、私たちの見解では、2つの方向に集中しています。1つ目は、非常に大規模なノード数に対応する新しいアーキテクチャーの追求、2つ目は、ソフトウェア最適化によるHB-DOMINオーバーレイの拡張などのアプローチです。1つ目は、非常に大規模なノード数のための新しいアーキテクチャを追求することであり、2つ目は、モデルの完全な理解に基づいて、例えばソフトウェア最適化によってHB-DOMINオーバーレイを拡張することによって、ノード間のトラフィック通信を縮小することです。
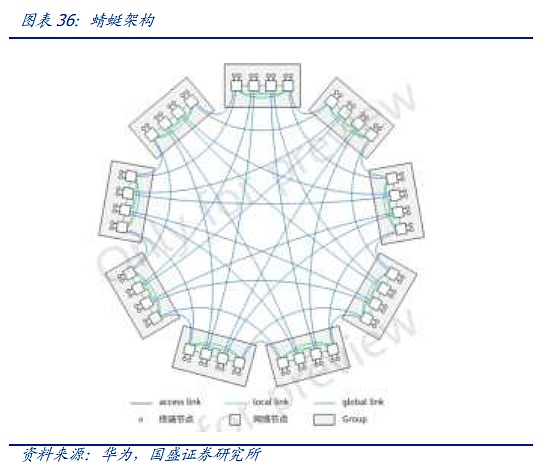
1つ目のソリューションの代表の1つが、2008年に初めて提案され、HPCで最初に使用されたDragonflyアーキテクチャですが、拡張のたびに配線を変更しなければならないため、Cisco HB-DOMINと比較するとスイッチとしての使いやすさは劣るとしても、配線は複雑です。しかし、拡張のたびに配線し直さなければならず、配線が複雑になるため、CLOSアーキテクチャに比べてスイッチの使用数が少ないにもかかわらず、結局主流になることはできなかった。しかし今日、巨大なノードと高価なAIハードウェアのCAPEXの中で、Dragonflyアーキテクチャは業界の最前線で徐々に注目を取り戻し始めている。現時点では、上記のOCS光スイッチングシステムの出現により、複雑なケーブル配線は、OCSを介して簡素化されることが期待され、AIクラスタの計画とCAPEXテンポのための第二の巨人は、より明確であるため、トンボより面倒な拡張プロセスは、もはや制約ではありません。第三に、葉リッジに比べて遅延のトンボは、物理的なレベルでは、より有利である、今GroqとAIチップの遅延に敏感な他のようなクラスタを構築するためにアーキテクチャを使用し始めている。

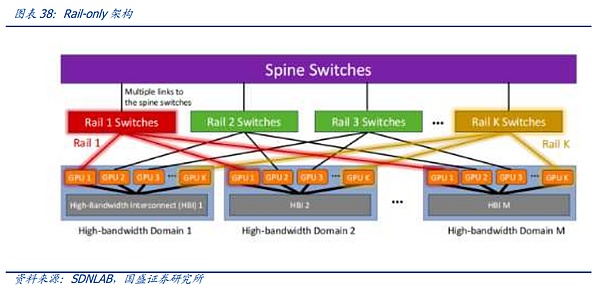
2つ目のソリューションの代表の1つが、MetaとMITによって提案されたRail-onlyアーキテクチャです。 Rail-Onlyアーキテクチャは、GPUを高帯域幅にグループ化することで機能します。Rail-Onlyアーキテクチャは、GPUをグループ化して高帯域幅相互接続ドメイン(HBドメイン)を形成し、このHBドメイン内の特定のGPUを特定のRailスイッチに交差させます。 ドメインをまたぐ通信のルーティングとスケジューリングの複雑さは増しますが、HBドメインとRailスイッチの合理的な設計により、アーキテクチャ全体ではスイッチの使用量を大幅に削減でき、ネットワーク通信の消費量を最大で75%削減できます。このアーキテクチャは、前述のスライス間通信によるイノベーションも示唆しており、拡大されたHB-DOMINドメインを通じてトレーニングスライシングとソフトウェア最適化を実装する余地を与え、HB-DOMIN間のスイッチ要件を削減し、非常に大規模なクラスタにおけるネットワークコスト削減の余地を提供します。
4.4 ;データセンター・クラスタリングの革新:未来の算術ネットワークの究極形?
AIクラスタが規模を拡大し続けるにつれて、1つのデータセンターの容量は、資本支出や通信ネットワークで搬送できるノードの最大数ではなく、データセンターのローカルまたは費用対効果の高い電力リソースの容量という点で、最終的に上限に達するでしょう。この上限は、資本支出や通信ネットワークで伝送できるノードの上限ではありません。
2024年初頭、マイクロソフトとOPENAIは2028年にスーパーコンピューター「Stargate」の建設を模索し始めた。The Informationによると、これには1,000ドル以上の投資が伴う可能性があり、100万ドル以上の投資が必要となる。The Information』によると、『スターゲイト』の最終的な全体計画には1,000ドル以上の投資が伴う可能性があり、最大5ギガワットの電力を使用する必要があるとのことで、これはチップと資金以外のプロジェクトにとって最も差し迫った問題のひとつとなるだろう。
そのため、今日の業界の最前線では、スマート・コンピューティング・センター間の長距離相互接続により、演算を費用対効果の高い電力エリアに均等に分散させることが可能になり、単一エリアの過大な価格設定による演算コストの上昇や演算容量の上限を避けることができます。データセンター間の相互接続は、クラスタ内の相互接続とはまったく異なるプロトコルやハードウェアなどを使用します。
今日のデータセンターは通常、上位レイヤーのスイッチやコアスイッチを介して外部ネットワークに接続されています。一方、データセンターのインターネットDCIは通信事業者によって構築されることが多く、長距離コヒーレント光モジュールを使用しています。伝送速度は長くなりますが、光モジュールを使用したデータセンターと比較すると、その速度と安定性に大きな違いがあり、価格も高くなります。同時に、価格が高いので、コスト削減、アーキテクチャの再構築を検討する必要がある前に、問題の正式な建設である。
しかし、より巨視的な観点に視線を引き寄せると、1つの演算センターは本質的にHB-DOMINドメインが以前と似ており、より強力であるため、このタイプの接続性の発展の将来の道は、一方では、コヒーレント光モジュール業界への投資を加速することであり、AIセンターの相互接続ベアラーを取り上げる余裕ができると信じています。私たちは、この種のコネクティビティの将来の道筋は、コヒーレント光モジュール産業への投資を加速して、AIセンターの相互接続の負荷と容量の要件を引き受けることができるようにすることであり、一方では、データセンター内の相互接続の密度を強化し、データセンターを単一のHBドメインに近づけることであり、最後には、IDC間のデータとモデルのスライスと並列化を可能にするために、分散ソフトウェアとトレーニングソフトウェアを革新することであると考えています。
5.投資アドバイス:イノベーションは止まらない、コアリンクも新たな変数も
チップと同様、通信システムもAIの需要に後押しされている。通信システムもまた、AIの需要によってイノベーションが加速しているが、1人か2人の「天才」に頼ってアーキテクチャやアイデアを革新することが多いチップ業界とは異なり、通信ハードウェアとソフトウェアは、多くのエンジニアがさまざまな局面でイノベーションを起こし、共に切磋琢磨することを必要とする体系的なプロジェクトである。最も基本的なスイッチングチップである光チップから、スイッチの上位層である光モジュール、通信アーキテクチャ、通信プロトコルの設計、そして運用・保守後のシステムの構成に至るまで、各リンクは異なる技術の巨人と無数のエンジニアに対応している。
私たちは、起業家的な投資に傾いているチップ産業に比べ、通信産業への投資はより追跡可能であり、産業の反復は多くの場合、巨人によって開始され、実施され、同時に、通信システム工学の安定性の要求のため、大規模なAIクラスタのサプライヤーの選択はしばしば非常に厳しく、まず、ハードウェアにおいて、ネットワークアーキテクチャとプロトコルがどのように変更されるかに関係なく、スイッチとプロトコルが変更されます。ネットワークアーキテクチャとプロトコルがどのように変化しても、スイッチと光モジュールは常にシステムの最も基本的なビルディングブロックであり、スケーリング-ローが有効である限り、パラメータの人間の追求のプロセスはまだ存在し、ビルディングブロックの需要は常に継続されます。確かに、このようなLPO、トンボアーキテクチャ、レールオンリーアーキテクチャは、関連するデバイスの割合や価値をカットしますが、コスト削減は常にAIの最優先事項であり、需要の拡大後のコスト削減は、業界に広いスペースをもたらすでしょう。これは最初のAI通信投資は、コアの概念とリンクを把握する必要があります。
同時に、技術革新のリンクのために、我々はまた、積極的に新しい技術のダイナミクスを追跡する必要があり、将来へのコンポーネントの変化のコアリンクによってもたらされる新しい技術の反復によって見つけるために、まず第一に、銅ケーブルの需要によってもたらされる費用対効果の高いHB-DOMINドメイン構築によって、最初にリリースされ、続いてCPO、バイアス保存光ファイバ、光ファイバ、光ファイバなどの新しい技術によってもたらされる長距離データセンターになります。第二は、CPO、長距離データセンター、バイアス保存光ファイバ、ベイトドープファイバなどの特殊な光ファイバの需要であり、最後に全光スイッチ、超イーサネットアライアンスなど、産業機会の進化を加速するために国内のスイッチをもたらす。

6. リスクのヒント
1.AIの需要が予想より少ない。
現在のAIはモデル開発段階にとどまっており、具体的なCエンド製品の開発はまだ進行中である。
2. スケーリング法則の失敗。
現在、世界的な容量解放の主な根拠は、モデルをより良くするためにパラメータのスケールを積み重ねる法則がまだ有効であり、パラメータの積み重ねが上限に達すれば、コンピューティングパワーの需要に影響を与えることである。
3. 業界競争の激化。
世界の演算業界は、ネットワーク業界と同様、AIの下で急成長しており、競争のために新規参入者を集めすぎると、既存の大手企業の利益が希薄化する。
Visaは、AIエージェントがユーザーに代わってVisaカードおよびVisa以外のカードを利用して商品の閲覧、選択、支払いを行うことができるプラットフォーム「Intelligent Commerce Connect」をリリースしました。
AnaisA16Z、人工知能、AIエージェント、信頼の障壁:なぜAIの次の10億人のユーザーは信頼ネットワークを通じてアクセスすることになるのか 金色財経、YouTubeの世界的拡大から得た教訓。
 JinseFinance
JinseFinance真に画期的なイノベーションは、常に危険を伴うものだ。危険なイノベーションが必ずしも未来を一変させるわけではないが、未来を一変させるようなイノベーションは、初期の段階において例外なく「危険」というレッテルを貼られるものだ。
JinseFinance強化学習×Web3の真のチャンスは、OpenAIの分散版を複製することではなく、「知的生産関係」を書き換えることにある。
JinseFinanceトレーダーをSui NetworkのPerp DEXに乗り換えさせるには、技術革新以上のものが必要かもしれない。
JinseFinanceChainbaseは、AI時代の透明性、信頼性、無許可のデータレイヤーを提供することに特化したオムニチェーンデータネットワークです。最近、テンセントが主導するシリーズAで1500万ドルの資金を注入し、Chainbaseはブロックチェーンデータ管理の展望を再定義する態勢を整えている。
 Wilfred
WilfredPermaswapは、AgentFiとAiFiの基礎となるサポートを提供する金融インフラとなり、開発者はその上に、ソーシャル、ゲーム、DeFi、コンテンツ作成など、様々なアプリケーションを構築することができる。
JinseFinance暗号AIの分野では、Bittensor、Ritual、Virtual Protocolがそれぞれ異なる分野に深く関わっている。Bittensorは現在、時価総額で暗号AI分野をリードしている。
JinseFinanceAIがこのサイクルの中心的な物語となり、市場のセンチメントと資金調達の熱意が圧倒している。
JinseFinance著名人、ブランド、有名人が NFT に何百万ドルも注ぎ込んでいる理由は、利益だけではありません。
 Cointelegraph
Cointelegraph